前言 前面介绍了关于可见光遥感图像目标检测任务主要面临的问题,现在对旋转目标的问题进行优化,为了便于大家理解与之前通用目标检测区别,采用Faster-Rcnn网络模型的架构对旋转目标的检测进行改进。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

注 本篇文章以场景文字识别为背景,但是主要解决的问题是场景文中旋转目标检测的问题,我们主要做的是对方法的提炼,当然本文提供的方法同样适用于遥感图像的旋转目标检测任务。通过这篇文章我们要有意识去多读文章,积累自己的思路,这个领域的难题可能迁移了其他领域的知识就会相对容易的得到解决。
背景
近年来,遥感图像检测任务受到了很多关注,尽管这些方法显示出了有竞争力的结果,但大多数方法依赖于水平或接近水平的注释,并返回水平区域的检测。然而,在实际应用中,大量的遥感图像区域不是水平的,甚至将非水平对齐的遥感图像作为轴对齐的处理方法也可能不准确。因此,水平框的方法不能在实践中广泛应用。在本文中,作者提出了一种基于旋转的方法和端到端遥感图像检测系统,用于任意定向遥感图像检测。特别之处在于结合了旋转角度的信息,使得检测系统可以生成任意方向的proposals。
作者提出了旋转区域建议网络(RRPN),该网络旨在利用遥感图像方向角度信息生成倾斜proposals。然后,角度信息适合于边界框回归,以使proposals更准确的适合遥感图像区域。旋转感兴趣区域(RRoI)池化层用于将任意定向的proposals投影到Feature map。最后,部署了一个两层网络来将区域分类为前景或背景。
方法
1、模型整体架构图
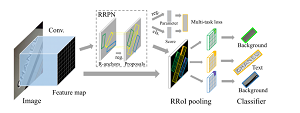
图1 基于Faster-Rcnn旋转目标检测框架图
相信大家有看过Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks这篇论文的对这张图片肯定是不陌生的。下图是Faster-Rcnn原图。


图2 Faster-Rcnn目标检测框架图
经过上图的对比,我们不难发现,旋转目标检测与通用目标检测的主要区别就是两个部分,区域推荐部分、感兴趣区域池化部分。 RPN是Faster-Rcnn最具有创新性的模块,其对于目标检测任务的重要程度不言而喻,下面简要说明作用原理。RPN网络组成是CNN,一般由3 3以及1 1的卷积构成,3 3卷积之后会有激活函数,RPN网络可以输入任意大小的图片尺寸,防止了因为crop、wrap等操作影响特征的丢失。影响图片输入尺寸的是全连接层,SPP-Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)已经解决了这个问题。在Feature map之后进行卷积处理,每个卷积的中心点都可以对应到原图一个区域里面,这就是感受野的概念,假设我们做了4次2倍的下采样,那么Feature map上一个点对应原来大小的区域,要在这个尺寸的区域生成9个锚框,根据3个尺寸和3个长宽比生成,假定Feature map大小为40 60,那么总共的锚框就有40 60 9 =20个锚框,由于锚框的数目众多而且质量不够好,所以对这些锚框进行筛选,用IOU这个指标进行处理,假定IOU>0.7为正样本,IOU<0.3为负样本,IOU在0.3到0.7之间的直接舍弃,若有的IOU达不到0.7,则取IOU最大的作为正样本。接下来经过全卷积网络(1 1卷积网络)来进行分类与回归任务,其中分类任务是二分类,要区分锚框里面的是不是存在物体,回归任务是根据锚框的坐标与真值的坐标进行编码与解码来生成预测框的位置。在分类任务结束之后还要进行预测框的筛选,这里采用NMS处理,对于预测框重叠面积较大的删除掉置信度较低的预测框,保留置信度较高的预测框。RoI Pooling的作用是把原图生成的框投射到Feature map上,进行Max Pooling操作。这里的RoI Pooling存在一些问题。第一、如果原图的框是不正好对齐在网格上面要进行框的改变,把他它齐在网格上。第二、在Pooling的时候分的网格尺寸并不是均分的,例如57的网格在分四个33的时候,会遇到5不能被3整除的情况,这时候会把5简单处理为3和2,7也不能被3整除,会把7分成3和4,如图3所示。这时候的网格就变为了23、24、33、34。为了解决上述问题,提出了RoI Align,用来替换RoI Pooling,这里不再赘述。
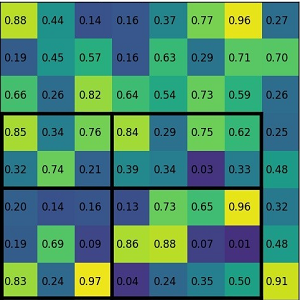
图3 RoI Pooling
2、RRPN模块
旋转边框表示用 (x, y, h, w, θ) 五元素表示;旋转锚点框使用角度、比例尺和长宽比参数。角度为-π/6, 0, π/6, π/3, π/2, 2π/3,比例尺为8,16,32,长宽比为1:2、1:5和1:8。feature map上的每个点,生成54个 r-anchor;如图4所示。水平框这里只有9个anchor,在开始训练之前,先定义好正负锚点的标定规则:1) 如果锚点对应的reference box与ground truth的IoU>0.7,标记为正样本;2) 如果锚点对应的reference box与ground truth的夹角小于π/12,标记为正样本;3) IoU小于0.3,标记为负样本;4) IoU大于0.7,但是夹角大于π/12,标记为负样本;5) 剩下的既不是正也不是负,不用于训练。损失函数的计算,比传统的多任务损失函数增加了一个角度的Loss计算;
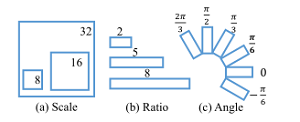
图4 R-anchor生成机制
Skew IoU Computation(倾斜IoU计算),其实就是IoU的计算,由于包围框的倾斜会造成重叠部分的为多边形,这部分的面积与水平框重叠的面积比较起来不好计算,作者用了很巧妙的方法,将不同的多边形都分解成为三角形,计算每个三角形的面积,在套用IoU计算公式,就能得到IoU的值。如图5所示。
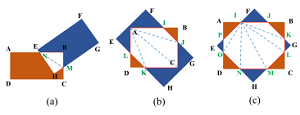
图5 IoU的计算
Skew Non-Maximum Suppression(倾斜NMS计算),偏斜NMS由两个阶段组成:(1)对于IoU大于0.7的proposals,保持最大IoU;(2)如果所有proposals的IoU都在[0.3,0.7]范围内,则保持提案与地面真相的角度差最小(角度差应小于π12)。与普通的NMS相比引入了角度的信息。
3、RRoI Pooling 层
对于任意方向的文本检测任务,传统的层只能处理水平的proposals。因此,作者提出了旋转层来调整生成的任意方向的建议。我们首先将层超参数设为和。对于高、宽的proposals,旋转后的proposlas区域可以划分为大小的子区域(如图6所示)。之后进行仿射变换,把旋转的包围框转变为水平框,然后在每个子区域执行, 的值保存在每个的矩阵中;与相比,可以将任何具有不同角度、长宽比或尺度的区域汇集到一个固定大小的feature map中。最后,将proposals转化为,发送给分类器给出结果,即是前景还是背景。
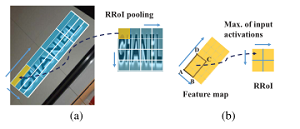
图6 RRoI Pooling Layer
实验
实验的部分都在场景文本检测的数据集进行实验的,都取得了很好的SOTA效果。
总结
第一,理解旋转目标检测的标注方法,各个参数的意义。
第二,深刻理解Faster-Rcnn中RPN用用原理。
第三,RRPN与RPN的不同,RoI Pooling的作用原理、RRoI Pooling原理。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章
上线一天,4k star | Facebook:Segment Anything
3090单卡5小时,每个人都能训练专属ChatGPT,港科大开源LMFlow
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)