【遥感目标检测】基于遥感图像的目标检测算法综述(DOTA/R2CNN/ROI Transformer/CAD-Net/SCRDet/Gliding Vertex)
- DOTA数据集:
- R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection
- Learning roi transformer for oriented object detection in aerial images
- CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery
- SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects
- Gliding vertex on the horizontal bounding box for multi-oriented object detection:
DOTA数据集:
1.简介:
DOTA是武大遥感国重实验室和华科电信学院合作做的一个航拍图像数据集,从不同的传感器和平台众包收集了2806个航拍图像,每一个图像是大小为4000*4000,包括15中目标类别,注释后的完整数据集图像包括188282个实例,每一个被一个任意四边形标记。
2.航拍图像特点:
(1)航拍图像目标检测的实例数量级更大。
(2)许多小物体实例在航拍图像中是聚集在一起的。
(3)航拍图像中物体出现的频率是非常不平衡的。
(4)航拍图像中物体常常以任意的位置出现,有一些实例常常有着比较夸张的纵横比。
3.Baseline:
使用了改进的Faster-RCNN;
R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection
1.主要贡献:
提出了Rotational Region CNN算法解决旋转目标的检测。注:作者没有使用角度来表示方位信息,而是使用顺时针方向的前两个点的坐标和边界框的高度来表示倾斜的矩形(x1,y1,x2,y2,h)。

2.模型结构:
主要是在Faster RCNN算法的基础上做了一些修改:
(1)ROI Pooling时也使用了311和113两种scale以解决水平和竖直长文本的检测。然后将提取到的ROI特征做cancat操作进行融合;
(2)预测输出有3个分支,第一个分支预测前景和背景二分类,第二个分支进行水平框(axis-aligned box)的预测,第三个分支进行倾斜框(inclined box)的预测;
(3)损失函数包括3部分:有无文本的二分类损失,水平框的回归损失和倾斜框的回归损失。回归任务均使用smooth L1损失函数。
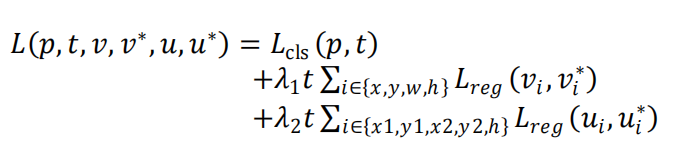
3.实验结果:

Learning roi transformer for oriented object detection in aerial images
1.主要贡献:
基于水平anchor,在RPN阶段通过全连接学习得到旋转ROI,并基于旋转ROI提取特征,然后进行定位和分类;
2.模型结构:

(1)RRoI Learner:目标是从水平ROI的特征图中学习旋转的ROI,回归目标定义如下;
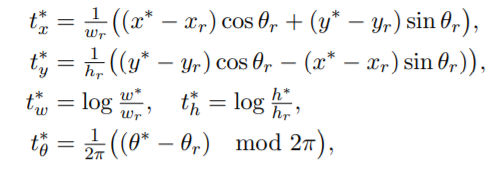
(2)Rotated Position Sensitive RoI Align:该模块用来提取ROI的旋转不变特征;
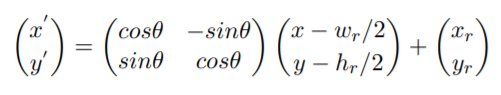
3.实验结果:

CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery
1.主要贡献:
CAD-Net基于RCNN和FPN结构进行改进。设计并融合了全局上下文网络(GCNet)和金字塔局部上下文网络(PLCNet),分别在全局场景级和局部目标级提取上下文信息。并且作者也设计了空间感知注意模块,引导网络关注信息更丰富的区域和更合适的图像特征尺度。
2.模型结构:

(1)GCNet:GCNet主要是考虑到而场景级语义通常对目标检测有一定的帮助(比如湖泊里面的船);其中Λ(I)表示特征提取网络的最后一层(即resnet - 101的C5层),ΦG(·)是由卷积层提取全局特征,ψ(·)表示Global Pooling层;
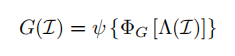
(2)PLCNet:除了全局上下文外,描述对象与邻近对象的局部上下文也可以捕获有用的信息。在观察到对象及其局部上下文都是尺度敏感的基础上,作者还设计了一个金字塔局部上下文网络(PLCNet)来学习对象/特征与其局部上下文之间的相关性;PLCNet通过训练来学习这些相关的特征和/或对象,在光学遥感图像纹理稀疏、对比度低、信息丢失严重的情况下对于检测很有帮助;
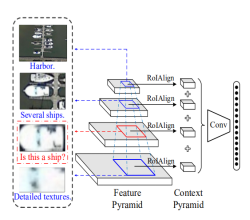
(3)Spatial-and-Scale-Aware Attention Module:作者还设计了一个空间感知和尺度感知的注意模块,有助于处理纹理稀疏、背景对比度较低的目标,并且尺度感知特征有助于处理不同尺度的目标。该模块建立在FPN生成的特征金字塔上,提取P2到P5的特征图,如图4所示。对于一个特定尺度Pi(i∈[2,5])的特征,attention-modulated feature定义如下:
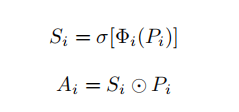
3.实验结果:

SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects
1.主要贡献:
(1)设计了一种采样融合网络,它将多层特征融合到有效的anchor采样中,以提高对于小型目标的检测灵敏度。
(2)通过抑制噪声和突出物体的特征,使用有监督的像素注意力网络和通道注意力网络,用于小而杂乱的目标检测。
(3)为了更准确地进行旋转估计,将IoU常数因子添加到smooth L1 loss中,用来解决旋转边界框的边界问题。
2.模型结构:
(1) Finer Sampling and Feature Fusion Network:该模块主要是通过融合low-level的特征和high-level特征进行目标信息保留和采样点密度的平衡。

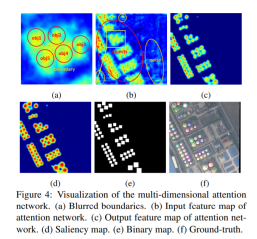
(2)Multi-Dimensional Attention Network:为了在复杂背景下更有效地捕获小物体的目标性,作者还设计了一个监督的多维注意力模块 (MDA-Net)。(监督指的是根据ground truth得到一个二值映射作为标签,然后利用二值映射和显著性映射的交叉熵损失作为注意力损失)。此外作者还使用SENet作为信道注意网络作为辅助。

(3)Rotation Branch:作者使用五个参数(x, y, w, h)来表示任意方向的矩形,并提出了一种基于三角剖分思想的斜IOU计算的实现方案。最后使用旋转非最大抑制(R-NMS)作为基于倾斜IOU计算的后处理操作。对于数据集中形状的多样性,作者还设置了不同的R-NMS阈值;
(4)回归目标:

(5)损失函数:

Gliding vertex on the horizontal bounding box for multi-oriented object detection:
1.主要贡献:
这篇文章任务,如果使用旋转矩形来表示物体,旋转矩形的旋转角比较难学习到因此提出可以通过学习四个点在非旋转矩形上的偏移来定位出一个四边形,从而表示一个物体。

2.模型结构:
(1)基本结构就是一个简单的Faster-RCNN,这篇文章主要是在预测输出这步做了一些改进;

(2)标签生成:对于一个给定的面向对象O(图中蓝色框—)和其相应的横向边界框,作者建议用 (x, y, w, h, α1, α2, α3, α4)来表示。

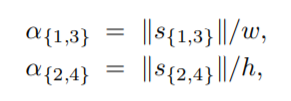
(3)损失函数:
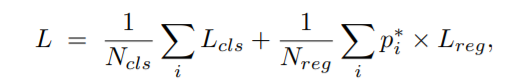
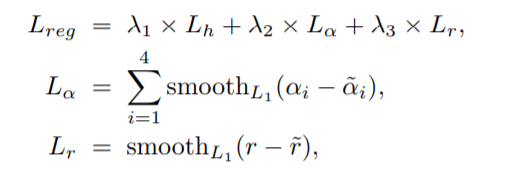
3.实验结果:
