【目标检测】2020年遥感图像目标检测综述
- 本文禁止转载
- 1. DOTA数据集:
- 2. 待解决的问题:
- 3. B a s e l i n e Baseline Baseline:
- 4. 几个经典模型:
- 5. 易迁移的Tricks:
- 更多内容:
本文禁止转载
1. DOTA数据集:
论文地址:https://arxiv.org/pdf/1711.10398.pdf
官网地址:https://captain-whu.github.io/DOTA/dataset.html

目标检测是计算机视觉中的一个重要而富有挑战性的问题。尽管过去十年已经见证了目标检测的主要进步的自然场景,但由于缺乏好的注释数据集对象的空中场景,遥感目标检测领域进展缓慢。为了推进对地观测和遥感中目标检测的研究,作者引入了一个用于航空图像中目标检测的大数据集(DOTA)。
作者从不同的传感器和平台上收集了2806幅航拍图像。每幅图像的大小约为4000×4000像素,包含了各种尺度、方向和形状的对象。这些DOTA图像然后由航拍图像判读专家使用15种常见的目标类别进行注释。
完整注释的DOTA图像包含188,282个实例,每个实例都由一个任意四边形标记。其中真值框大部分为矩形,训练时往往也将任意四边形近似看作一个矩形。
图片张数:2806
图片大小:4000*4000
分类数:15
包含物体数:188,282
数据集大小:35G
2. 待解决的问题:
2.1 目标小而密集:

主要指的是图像中可能出现较多密集而且较小的目标(如停车场密集车辆)。同时遥感图像数据也存在着尺度差异大的问题,即图像中也可能同时出现较大的目标(如广场等标志建筑)。这就使得Anchor的大小设计需要包含较大范围。
2.2 任意旋转角:

主要指的是检测任务中的目标框有一个旋转角,那么如何有效表示带有旋转角的任意矩形,以及如何定量确定表示检测框的回归目标也是一个有待研究的问题。
2.3 Anchor匹配问题:

一些目标横纵比非常大(比如桥梁),这些类别的目标在RPN阶段很难匹配到合适的正样本Anchor,从而较少参与Loss的计算,导致这些类别AP较低。而且横纵比变化较大也导致难以进行有效的Anchor设计。如上图所示,即使图中Anchor已经达到最佳匹配位置,但是实际IOU也只有0.33。
2.4 回归任务的边界问题:

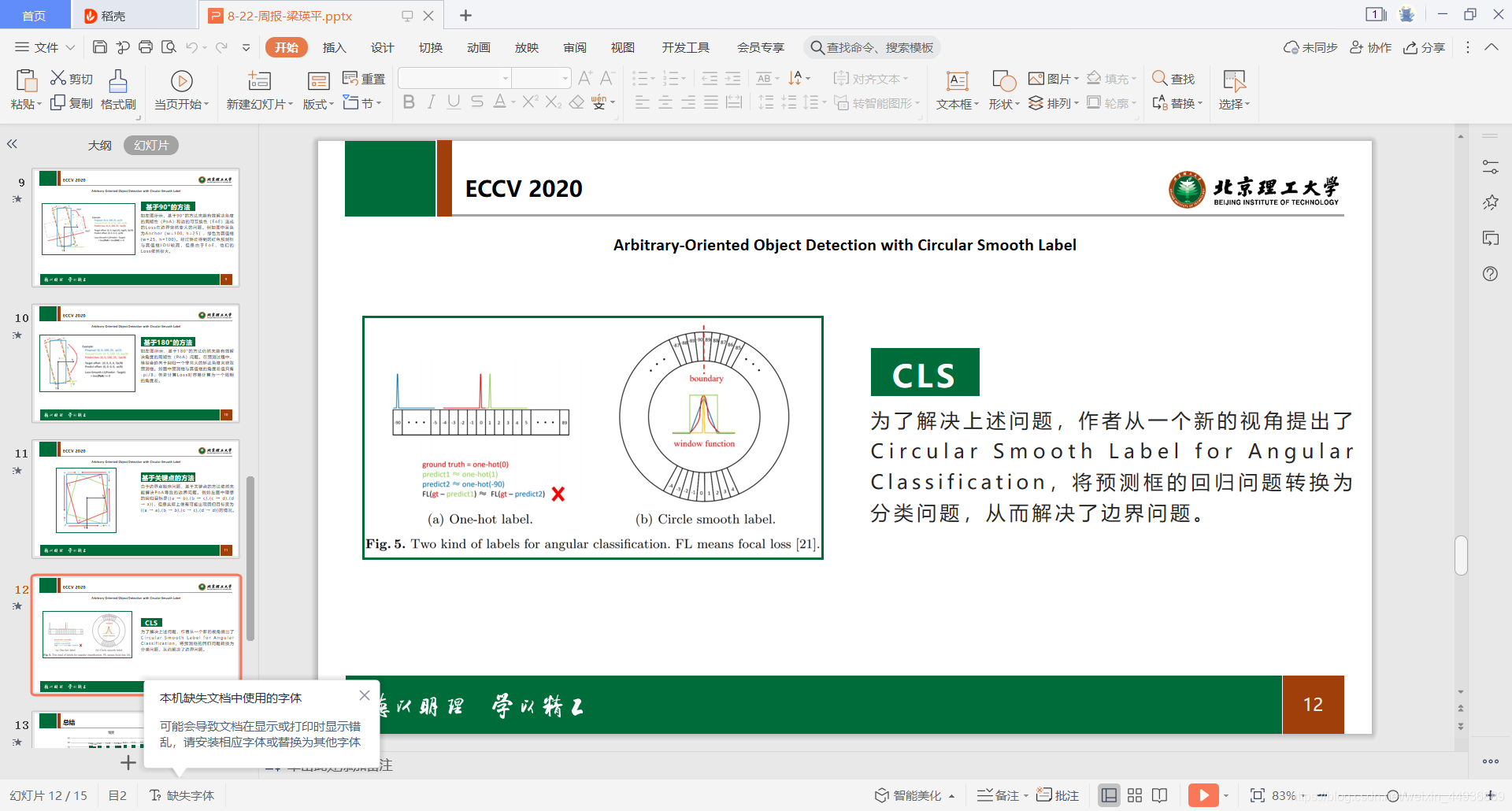
由于角的周期性(PoA)和边缘的互换性(EoE),损失函数可能非常大。因此,需要对模型进行其他复杂形式的回归。如上图所示,如果w和h互换,那么即使预测框和真值框IOU很高,他们的回归Loss也会很大。
2.5 实例级噪声:

实例级噪声一般是指物体之间的相互干扰,也指来自背景的干扰。例如上图:
- 第一行:形状类似目标的非目标在特征图中的响应较高;
- 第二行:密集目标存在类间特征耦合和类内特征边界模糊的问题;
- 第三行:被背景包围的对象响应不够突出。
3. B a s e l i n e Baseline Baseline:

Baseline是DOTA在公开比赛中提供的基线模型,基本结构为经典的 Faster-RCNN 模型,只是在回归任务中添加了一个额外的回归目标 t θ t_{\theta} tθ 用于旋转目标的表示。该模型被称为 FR-O,即 Faster R-CNN trained on Oriented bounding boxes。
源码地址:https://github.com/jessemelpolio/Faster_RCNN_for_DOTA
4. 几个经典模型:
4.1 R 2 C N N R^2CNN R2CNN:
4.1.1 论文地址:
论文地址:https://arxiv.org/abs/1706.09579
源码地址:https://github.com/DetectionTeamUCAS/R2CNN_Faster-RCNN_Tensorflow
(注意这一篇论文提出时是用于OCR任务的)
4.1.2 模型结构:

主要特点为:
- ROI Pooling添加了311和113两种scale以解决纵横比较大目标的检测。然后将提取到的ROI特征做cancat操作进行融合;
- 预测输出有3个分支,分别预测景和背景二分类,水平框(axis-aligned box)和倾斜框(inclined box);
- 损失函数包括3部分:二分类损失,水平框和倾斜框的回归损失。回归均使用smooth L1损失函数。
坐标表示:
使用粗略的矩形框表示,每个水平真值框表示为 [ x , y , w , h ] [x, y, w, h] [x,y,w,h],每个倾斜框表示为 [ x 1 , y 1 , x 2 , y 2 , h ] [x1, y1, x2, y2, h] [x1,y1,x2,y2,h]。
缺点和不足:
- 未考虑旋转坐标框的边界问题。
- 主要结构为 Faster-RCNN,对小目标检测效果较差。
4.2 S C R D e t SCRDet SCRDet:
4.2.1 论文地址:
论文地址:https://arxiv.org/abs/1811.07126
源码地址:https://github.com/DetectionTeamUCAS/R2CNN-Plus-Plus_Tensorflow
4.2.2 模型结构:

主要特点:
- 设计了一种采样融合网络,它将多层特征融合到有效的anchor采样中,以提高对于小型目标的检测灵敏度。
- 通过抑制噪声和突出物体的特征,使用有监督的像素注意力网络和通道注意力网络,用于小而杂乱的目标检测。
- 为了更准确地进行旋转估计,将IoU常数因子添加到smooth L1 loss中,用来解决旋转边界框的边界问题。
SF-Net:

该模块主要是通过加入带有Inception结构的残差项,来融合low-level的特征和high-level特征进行目标信息保留和采样点密度的平衡。
MDA-Net:

为了在复杂背景下更有效地捕获小物体的目标性,作者还设计了一个监督的多维注意力模块 (MDA-Net)。(监督指的是根据ground truth得到一个二值映射作为标签,然后利用二值映射和显著性映射的交叉熵损失作为注意力损失),并使用SENet作为信道注意网络作为辅助。
Rotation Branch:

作者使用五个参数(x, y, w, h,θ)来表示任意方向的矩形,并提出了一种基于三角剖分思想的斜IOU计算的实现方案。最后使用旋转非最大抑制(R-NMS)作为基于倾斜IOU计算的后处理操作。对于数据集中形状的多样性,作者还设置了不同的R-NMS阈值。
4.3 S C R D e t + + SCRDet++ SCRDet++:
4.3.1 论文地址:
论文地址:https://arxiv.org/abs/2004.13316
源码地址:https://github.com/SJTU-Thinklab-Det/DOTA-DOAI/tree/master/FPN_Tensorflow_Rotation
(注意该论文的模型并未开源,上面的链接只是一个论文中实例级去噪的实现,而且似乎实现的也有问题,我提了issue等待作者回复ing)
4.3.2 模型结构:

主要特点:
本文主要探讨了进行实例级去噪(InLD)的方法,特别是在特征映射(即潜在层的输出由CNNs)中,以实现鲁棒检测。希望是减少类间特征耦合和类内干扰,同时阻止背景干扰。为此,指定了一种新颖的InLD组件以将不同目标类别的特征近似解耦到它们各自的通道中。
InLD:


核心思想是将不同目标类别的特征分离到各自的通道中,同时在空间域中分别增强和减弱物体和背景的特征。因此,SCRDet的新公式如图所示,其中考虑了对象类别的总数I,并为背景增加了一个类别。并且DInLD(X)可以近似为多个Ai(Xi)的组合,表示类别i的注意力函数。

“HA”,“SP”,“SH”和“SV”分别表示不同类别。“Ohters”包括背景和未显示在图片中的类别。该算法将不同类别的特征解耦到各自的信道中(上、中),并在空间域内分别对目标和背景特征进行增强和抑制(下)。

ImLD:

作者利用卷积层来模拟不同类型的差分滤波器,如非局部均值、双边滤波、均值滤波和中值滤波。受这些在对抗性攻击中成功操作的启发,作者对这些用于目标检测的差异操作进行了迁移和扩展。ImLD通过去噪操作处理输入特征(例如非局部均值或其他变体)。去噪后的表示首先由1×1卷积层处理,然后通过残差连接添加到模块输入中。
IoU-smooth L1 loss:

在边界情况下,损失函数∣−log(IoU)∣≈0,消除了由∣Lreg(v′j,vj)∣引起的损失的突然增加。
4.4 G l i d i n g Gliding Gliding V e r t e x Vertex Vertex:
4.4.1 论文地址:
论文地址:https://arxiv.org/abs/1911.09358
源码地址:https://github.com/MingtaoFu/gliding_vertex
4.4.2 模型结构:

主要特点:
举一个简单的例子,如果一个四边形的真值框是(x1,y1,x2,y2,x3,y3,x4,y4),那么检测器有可能给出的预测结果是(x2,y2,x3,y3,x4,y4,x1,y1)。其实这两个是框是完全重合的,但是网络训练算损失的时候并不知道,它会按对应位置计算损失,此时的损失值并不为0甚至很大。
因此本文提出可以通过学习四个点在非旋转矩形上的偏移来定位出一个四边形,从而表示一个物体。

即对于一个给定的面向对象O(图中蓝色框—)和其相应的横向边界框,作者建议用 (x, y, w, h, α1, α2, α3, α4)来表示,以取代(x1,y1,x2,y2,x3,y3,x4,y4)的表示方法。
4.5 R o I RoI RoI T r a n s f o r m e r Transformer Transformer:
4.5.1 论文地址:
论文地址:https://arxiv.org/abs/1812.00155
源码地址:https://github.com/dingjiansw101/AerialDetection
4.5.2 模型结构:

主要特点:
- RRoI Learner:在RPN阶段通过全连接层学习得到旋转ROI,回归目标定义如下:

- Rotated Position Sensitive RoI Align:该模块用来提取ROI的旋转不变特征;

坐标表示:
使用[x, y, w, h, θ]表示一个实例。
旋转IOU计算:
倾斜框的IOU计算方法如图。
4.6 C A D − N e t CAD-Net CAD−Net:
4.6.1 论文地址:
论文地址:https://arxiv.org/abs/1903.00857
源码地址:暂无开源代码
4.6.2 模型结构:

主要特点:
CAD-Net基于RCNN和FPN结构进行改进。设计并融合了全局上下文网络(GCNet)和金字塔局部上下文网络(PLCNet),分别在全局场景级和局部目标级提取上下文信息。并且作者也设计了空间感知注意模块,引导网络关注信息更丰富的区域和更合适的图像特征尺度。
GCNet:
GCNet主要是考虑到而场景级语义通常对目标检测有一定的帮助(比如湖泊里面的船),因此加入了全局特征。
其中Λ(I)表示特征提取网络的最后一层,ΦG(·)是由卷积层提取全局特征,ψ(·)表示Global Pooling层;
SAM:

作者还设计了一个空间感知和尺度感知的注意模块,有助于处理纹理稀疏、背景对比度较低的目标。该模块建立在FPN生成的特征金字塔上,提取P2到P5的特征图。对于一个特定尺度Pi(i∈[2,5])的特征,attention-modulated feature定义如下:

PCLNet:

PCLNet主要是考虑到局部上下文也可以捕获有用的信息,因此作者设计了一个金字塔局部上下文网络(PLCNet)来学习对象/特征与其局部上下文之间的相关性;
即通过将FPN中不同层的特征融合,作为新的特征(带有相邻目标信息)进行预测。
5. 易迁移的Tricks:
5.1 F e a t u r e Feature Feature P y r a m i d Pyramid Pyramid:

特征/图像金字塔被广泛用于不同大小的目标检测;
(a)方法(如R-CNN)使用了图像金字塔,使用不同大小的图像来生产不同大小的特征层,从而对不同大小的目标进行检测,计算消耗非常大;
(b)方法(如Faster-RCNN)为了节省计算时间,使用了具有高度语义信息的单层特征层,通过生成不同大小的anchors(预选框)来对不同大小的目标进行检测,对小目标检测效果不佳;
(c)方法(如SSD)为了解决不同大小目标特征不同的问题,重复使用了不同大小的特征层,分别对不同大小目标进行检测,但是由于底层特征并不具有高度的语义信息,导致对小目标检测的结果仍不理想;
这是因为目标分类需要的一般是深层的语义特征,而目标检测需要的一般是底层的特征(如颜色、拐角等);
因此,作者提出了一种新的特征金字塔检测方法——FPN;
如图(d),作者使用了具有高度语义信息的深层特征层,通过上采样(最邻近插值)的方式生成新的特征金字塔,从而使得不同大小的特征层都具有了高度的语义信息;同时也通过求和(类似残差)的方式融合底层特征。
5.2 C a s c a d e Cascade Cascade R C N N RCNN RCNN:

在基于anchor的检测方法中,我们一般会设置训练的正负样本,通常规定IOU>0.5的作为正样本,IOU<0.3作为负样本等。但是作者通过实验发现:(1)设置不同阈值,阈值越高,其网络对准确度较高的候选框的作用效果越好。(2)不论阈值设置多少,训练后的网络对输入的proposal都有一定的优化作用。
基于上述两点,作者设计了Cascade R-CNN网络。如图所示,即通过级联的R-CNN网络,每个级联的R-CNN设置不同的IOU阈值,这样每个网络输出的准确度提升一点,用作下一个更高精度的网络的输入,逐步将网络输出的准确度进一步提高。
5.3 L e n g t h Length Length I n d e p e n d e n t Independent Independent I o U IoU IoU:
LIIoU沿着真值框的长边拦截部分真值框,并使拦截后得到的坐标框的长度与Anchor的长度相同。如图所示,传统的IoU只有0.3,而作者提出的LIIoU接近1。具体的LIIoU计算如图所示,其中AB为目标框的中心线,C点为所提出框的中心线。从而解决的Anchor匹配问题。
更多内容:
感兴趣的同学关注我的公众号——可达鸭的深度学习教程,公众号内回复“遥感”获取遥感目标检测更多总结: