前言
目标检测(Object Detection)是计算机视觉领域的基本任务之一,学术界已有将近二十年的研究历史。近些年随着深度学习技术的火热发展,目标检测算法也从基于手工特征的传统算法转向了基于深度神经网络的检测技术。从最初2013年提出的R-CNN、OverFeat,到后面的Fast/Faster R-CNN,SSD,YOLO系列,再到2018年最近的Pelee。短短不到五年时间,基于深度学习的目标检测技术,在网络结构上,从two stage到one stage,从bottom-up only到Top-Down,从single scale network到feature pyramid network,从面向PC端到面向手机端,都涌现出许多好的算法技术,这些算法在开放目标检测数据集上的检测效果和性能都很出色。
本篇综述的出发点一方面是希望给检测方向的入门研究人员提供一个技术概览,帮助大家快速了解目标检测技术上下文;另一方面是给工业界应用人员提供一些参考,通过本篇综述,读者可以根据实际业务场景,找到合适的目标检测方法,在此基础上改进、优化甚至是进一步创新,解决实际业务问题。
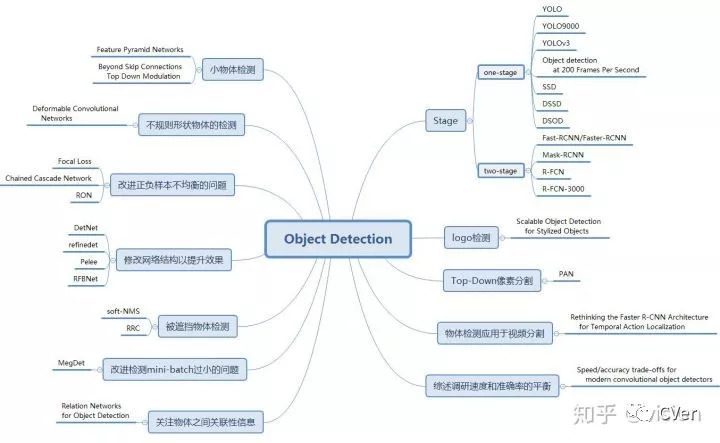
本文对其中的26篇论文进行介绍,这26篇论文涵盖了2013以来,除SSD,YOLO和R-CNN系列之外的,所有引用率相对较高或是笔者认为具有实际应用价值的论文。R-CNN系列,SSD和YOLO相关的论文详解资源已经非常多,所以本文不再赘述。下图对这些方法进行了分类概括。
一、 背景
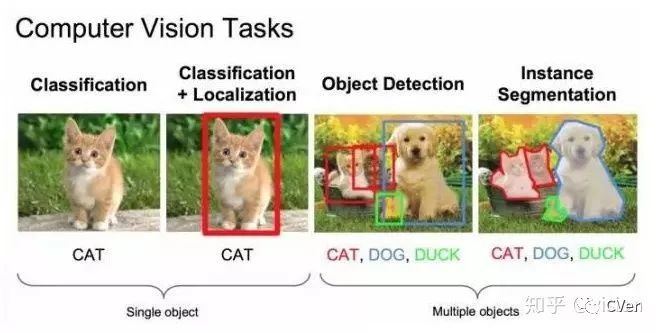
物体检测的任务是找出图像或视频中的感兴趣物体,同时检测出它们的位置和大小,是机器视觉领域的核心问题之一。
物体检测过程中有很多不确定因素,如图像中物体数量不确定,物体有不同的外观、形状、姿态,加之物体成像时会有光照、遮挡等因素的干扰,导致检测算法有一定的难度。进入深度学习时代以来,物体检测发展主要集中在两个方向:two stage算法如R-CNN系列和one stage算法如YOLO、SSD等。两者的主要区别在于two stage算法需要先生成proposal(一个有可能包含待检物体的预选框),然后进行细粒度的物体检测。而one stage算法会直接在网络中提取特征来预测物体分类和位置。

本篇综述将主要分为三个部分:
1. Two/One stage算法改进。这部分将主要总结在two/one stage经典网络上改进的系列论文,包括Faster R-CNN、YOLO、SSD等经典论文的升级版本。
2. 解决方案。这部分论文对物体检测中遇到的各类问题进行了分析并提出了解决方案。
3. 扩展应用、综述。这部分将就特殊物体检测和检测算法在其他领域的应用等方面进行介绍。
本综述分三部分,本文介绍第一部分。
1.1.1 R-FCN: Object Detection via Region-based Fully Convolutional Networks
论文链接:
https://arxiv.org/abs/1605.06409
开源代码:
https://github.com/daijifeng001/R-FCN
录用信息:CVPR2017
论文目标:
对预测特征图引入位置敏感分数图提增强征位置信息,提高检测精度。
核心思想:
一. 背景
Faster R-CNN是首个利用CNN来完成proposals的预测的,之后的很多目标检测网络都是借助了Faster R-CNN的思想。而Faster R-CNN系列的网络都可以分成2个部分:
1.Fully Convolutional subnetwork before RoI Layer
2.RoI-wise subnetwork
第1部分就是直接用普通分类网络的卷积层来提取共享特征,后接一个RoI Pooling Layer在第1部分的最后一张特征图上进行提取针对各个RoIs的特征图,最后将所有RoIs的特征图都交由第2部分来处理(分类和回归)。第二部分通常由全连接层组层,最后接2个并行的loss函数:Softmax和smoothL1,分别用来对每一个RoI进行分类和回归。由此得到每个RoI的类别和回归结果。其中第1部分的基础分类网络计算是所有RoIs共享的,只需要进行一次前向计算即可得到所有RoIs所对应的特征图。
第2部分的RoI-wise subnetwork不是所有RoIs共享的,这一部分的作用就是给每个RoI进行分类和回归。在模型进行预测时基础网络不能有效感知位置信息,因为常见的CNN结构是根据分类任务进行设计的,并没有针对性的保留图片中物体的位置信息。而第2部分的全连阶层更是一种对于位置信息非常不友好的网络结构。由于检测任务中物体的位置信息是一个很重要的特征,R-FCN通过提出的位置敏感分数图(position sensitive score maps)来增强网络对于位置信息的表达能力,提高检测效果。
二. 网络设计
2.1position-sensitive score map
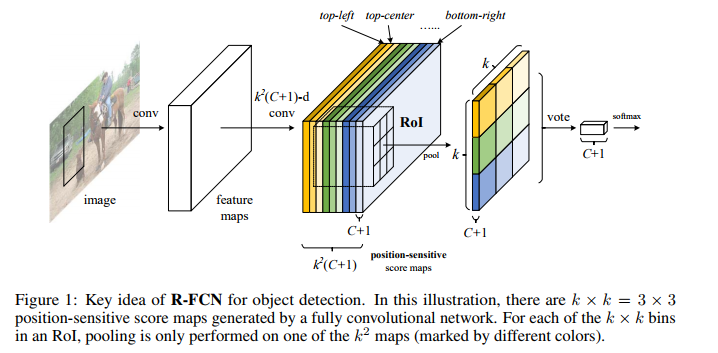
上图展示的是R-FCN的网络结构图,展示了位置敏感得分图(position-sensitive score map)的主要设计思想。如果一个RoI含有一个类别c的物体,则将该RoI划分为k x k个区域,分别表示该物体的各个相应部位。其每个相应的部位都由特定的特征图对其进行特征提取。R-FCN在共享卷积层的最后再接上一层卷积层,而该卷积层就是位置敏感得分图position-sensitive score map。其通道数channels=k x k x (C+1)。C表示物体类别种数再加上1个背景类别,每个类别都有k x k 个score maps分别对应每个类别的不同位置。每个通道分别负责某一类的特定位置的特征提取工作。
2.2 Position-sensitive RoI pooling
位置敏感RoI池化操作了(Position-sensitive RoI pooling)如下图所示:

该操作将每个RoIs分为k x k 个小块。之后提取其不同位置的小块相应特征图上的特征执行池化操作,下图展示了池化操作的计算方式。
得到池化后的特征后,每个RoIs的特征都包含每个类别各个位置上的特征信息。对于每个单独类别来讲,将不同位置的特征信息相加即可得到特征图对于该类别的响应,后面即可对该特征进行相应的分类。

2.3 position-sensitive regression
在位置框回归阶段仿照分类的思路,将特征通道数组合为4 x k x k 的形式,其中每个小块的位置都对应了相应的通道对其进行位置回归的特征提取。最后将不同小块位置的四个回归值融合之后即可得到位置回归的响应,进行后续的位置回归工作。
三. 网络训练
3.1 position-sensitive score map高响应值区域
在训练的过程中,当RoIs包涵物体属于某类别时,损失函数即会使得该RoIs不同区域块所对应的响应通道相应位置的特征响应尽可能的大,下图展示了这一过程,可以明显的看出不同位置的特征图都只对目标相应位置的区域有明显的响应,其特征提取能力是对位置敏感的。

3.2 训练和测试过程
使用如上的损失函数,对于任意一个RoI,计算它的Softmax损失,和当其不属于背景时的回归损失。因为每个RoI都被指定属于某一个GT box或者属于背景,即先让GT box选择与其IoU最大的那个RoI,再对剩余RoI选择与GT box的IoU>0.5的进行匹配,而剩下的RoI全部为背景类别。
当RoI有了label后loss就可以计算出来。这里唯一不同的就是为了减少计算量,作者将所有RoIs的loss值都计算出来后,对其进行排序,并只对最大的128个损失值对应的RoIs进行反向传播操作,其它的则忽略。
并且训练策略也是采用的Faster R-CNN中的4-step alternating training进行训练。在测试的时候,为了减少RoIs的数量,作者在RPN提取阶段就将RPN提取的大约2W个proposals进行过滤:
1.去除超过图像边界的proposals
2.使用基于类别概率且阈值IoU=0.3的NMS过滤
3.按照类别概率选择top-N个proposals
在测试的时候,一般只剩下300个RoIs。并且在R-FCN的输出300个预测框之后,仍然要对其使用NMS去除冗余的预测框。
算法效果:
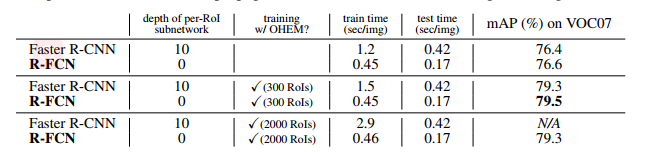
上图比较了Faster-R-CNN 和R-FCN的mAP值和监测速度,采用的基础网络为ResNet-101,测评显卡为Tesla K40。
1.1.2 R-FCN-3000 at 30fps: Decoupling Detection and Classification
论文链接:
https://arxiv.org/pdf/1712.01802.pdf
开源代码:无
录用信息:无
论文目标:
与YOLO9000(本论述后文会具体介绍YOLO9000)类似,本文的目标也是面向实际应用场景的大规模类别物体的实时检测。YOLO9000将检测数据集和分类数据集合并训练检测模型,但r-fcn-3000仅采用具有辅助候选框信息的ImageNet数据集训练检测分类器。
如果使用包含标注辅助信息(候选框)的大规模分类数据集,如ImageNet数据集,进行物体检测模型训练,然后将其应用于实际场景时,检测效果会是怎样呢?how would an object detector perform on "detection"datasets if it were trained on classification datasets with bounding-box supervision?
核心思想:
r-fcn-3000是对r-fcn的改进。上文提到,r-fcn的ps卷积核是per class的,假设有C个物体类别,有K*K个ps核,那么ps卷积层输出K*K*C个通道,导致检测的运算复杂度很高,尤其当要检测的目标物体类别数较大时,检测速度会很慢,难以满足实际应用需求。
为解决以上速度问题,r-fcn-3000提出,将ps卷积核作用在超类上,每个超类包含多个物体类别,假设超类个数为SC,那么ps卷积层输出K*K*SC个通道。由于SC远远小于C,因此可大大降低运算复杂度。特别地,论文提出,当只使用一个超类时,检测效果依然不错。算法网络结构如下:

上图可以看出,与r-fcn类似,r-fcn-3000也使用RPN网络生成候选框(上图中虚线回路);相比r-fcn, r-fcn-3000的网络结构做了如下改进:
1. r-fcn-3000包含超类(上图中上半部分)和具体类(上图中下半部分)两个卷积分支。
2. 超类卷积分支用于检测超类物体,包含分类(超类检测)和回归(候选框位置改进)两个子分支;注意上图中没有画出用于候选框位置改进的bounding-box回归子分支;回归分支是类别无关的,即只确定是否是物体。
3. 具体类卷积分支用于分类物体的具体类别概率,包含两个普通CNN卷积层。
4. 最终的物体检测输出概率由超类卷积分支得到的超类类概率分别乘以具体类卷积分支输出的具体类别概率得到。引入超类和具体类两个卷积分支实现了‘物体检测’和‘物体分类’的解耦合。超类卷积分支使得网络可以检测出物体是否存在,由于使用了超类,而不是真实物体类别,大大降低了运算操作数。保证了检测速度;具体类分支不检测物体位置,只分类具体物体类别。
超类生成方式:对某个类别j的所有样本图像,提取ResNet-101最后一层2018维特征向量,对所有特征项向量求均值,作为该类别的特征表示。得到所有类别的特征表示进行K-means聚类,确定超类。
算法效果:
在imagenet数据集上,检测mAP值达到了34.9%。使用nvidia p6000 GPU,对于375x500图像,检测速度可以达到每秒30张。在这种速度下,r-fcn-3000号称它的检测准确率高于YOLO 18%。
此外,论文实验表明,r-fcn-3000进行物体检测时具有较强的通用性,当使用足够多的类别进行训练时,对未知类别的物体检测时,仍能检测出该物体位置。如下图:
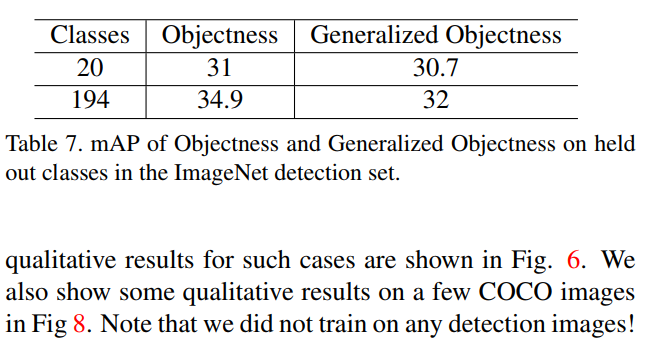

在训练类别将近3000时,不使用目标物体进行训练达到的通用预测mAP为30.7%,只比使用目标物体进行训练达到的mAP值低0.3%。
1.1.3 Mask R-CNN
论文链接:
https://arxiv.org/abs/1703.06870
开源代码:
https://github.com/TuSimple/mx-maskrcnn
录用信息:CVPR2017
论文目标