前言:什么是自动标注?
在训练过程中,如果图片的数据量不够,或想通过某些手段加快标注的效率,可以在之前训练好的模型基础上识别出一些物体,根据已识别的数据进行转换。在labelme或labelimg上继续修改已识别的数据。这时候由于已经有很多物体被模型识别预先标注了,可以很大提高标注的效率。
工具:YOLO模型,labelImg
这里推荐使用的工具是labelImg,其它标注labelme工具需要其它转换,不太推荐。实测YOLO版本是YOLOV7,其它YOLO系列也可以保存识别的结果,就算有差异应该不大可以轻松地进行转换。
而关于labelImg的安装与使用请查看这篇文章
开始标注:
1.获取预权重
可以先用标注软件标注300张图片,然后用YOLOv7训练得出预权重。然后把权重放入YOLO模型的weight目录下。

2.修改参数
接着是通过设置参数,打开detect.py,修改save--text 参数,值为'store_false'。

该参数的意思是是否保存检测后后的结果,如框的位置大小,框的物体类别。注意,store_false才是保存检测的结果。
3.运行项目
现在我们在/yolov7/这个工作路径下,输入如下命令
python detect.py --weights weights/yolov7.pt --source inference/images参数说名
--weights weight/yolov7.pt # 这个参数是把已经训练好的模型路径传进去,就是刚刚下载的文件
--source inference/images # 传进去要预测的图片

如果得到如下的运行结果,则说明运行成功,预测的图片被保存在了/runs/detect/exp2/文件夹下

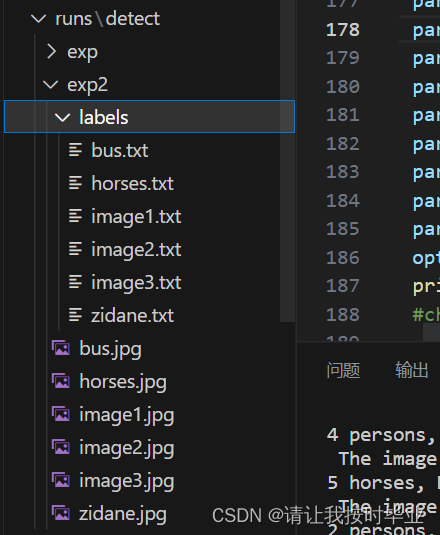
4.在检测的结果中加入图片和类数据。
首先来到检测结果的输出目录,看到已经生成和图片格式完全一致的label格式。
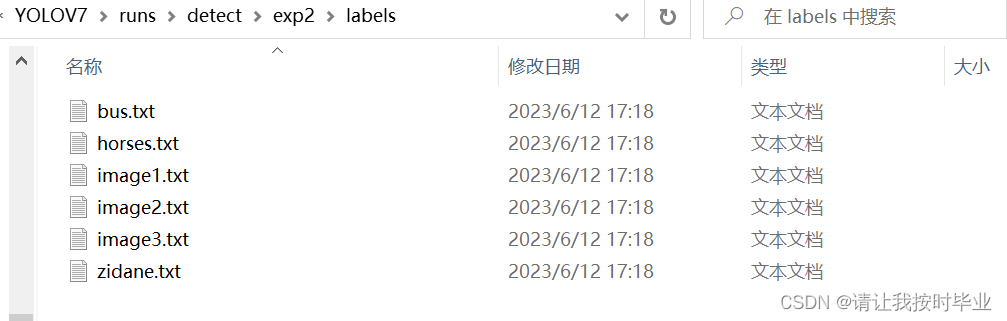
打开后是数据是这样的格式。保存的格式是:类别索引,框的位置和大小数据。

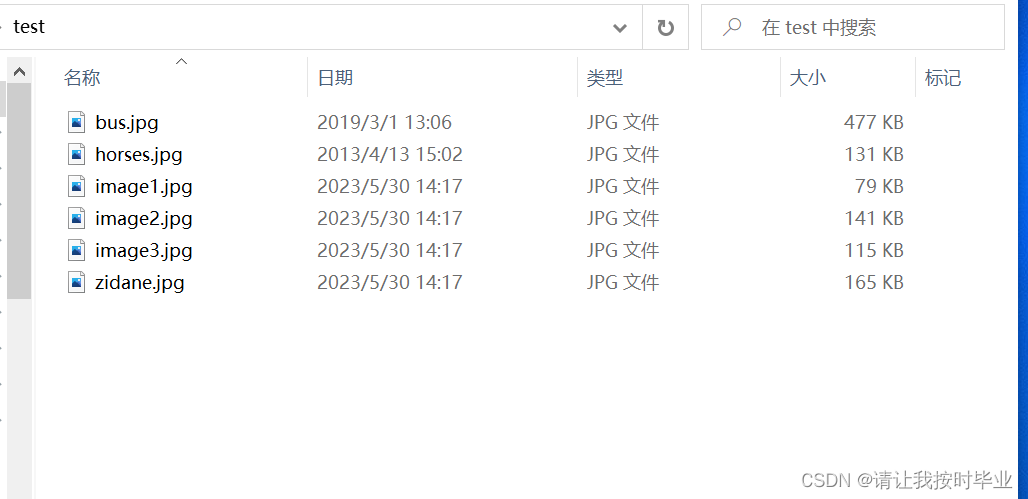
我们把对应的图片目录YOLOV7\inference\images下的图片全部拷到单独目录(是原图),如下图。输出结果的label文件和图片是对应的。
PS:label和原图要分开两个文件夹
最后加入框类型各类的文件。文件格式是.txt,格式如下。在我这个模型中识别的是一下几种类别。

5.最后打开标注软件对结果进行修改。
若是YOLO数据集格式,标注文件为txt文件:
在labelimg中选择Open Dir,打开存放原图的目录,让选择Change Save Dir,选择刚刚模型输出label目录。已经看到模型识别后标注的结果,具体框的结果与模型的准确度有关。

若是VOC数据集格式,标注文件为XML格式:
在精灵标注助手中选择新建项目,选择刚才的模型输出目录。进入后选择导入,把xml文件导入,则可以看到模型识别后标注的结果,具体框的结果与模型的准确度有关。


如果有发现标注不正确或错误太多的可以适当调高conf-thres值再检测,默认是0.25。

如果误识别或标注框不对,可以在labelimg上对标注的信息进行修改。