原文链接:https://arxiv.org/abs/2308.04556
1. 引言
目前的3D目标检测方法没有显式地去考虑漏检问题。
本文提出了困难实例探测(HIP)。受目标检测的级联解码头启发,HIP逐步探测误检样本,极大提高召回率。在每个阶段,HIP抑制TP样本并关注之前阶段的FN样本,则通过迭代HIP,可以处理困难的FN样本。
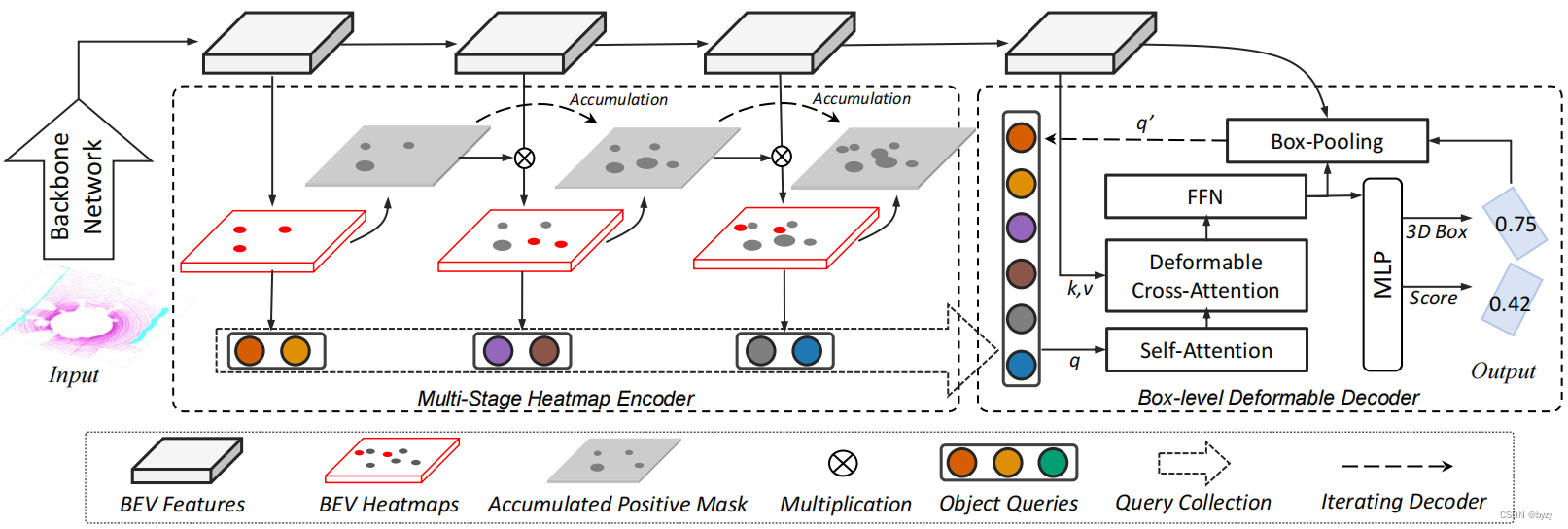
基于HIP,本文提出名为FocalFormer3D的3D目标检测,如下图所示。其中的多阶段热图预测用于挖掘困难实例。FocalFormer3D维护一个积累正样本掩膜,以指示之前阶段的正样本区域,这样网络忽略简单样本的训练而关注困难实例(FN)。最后,网络收集来自所有阶段的正预测以生成候选物体。
此外,本文还提出边界框级的细化阶段,以消除冗余的候选物体。使用可变形Transformer解码器,通过RoIAlign将候选物体表达为边界框级的查询,以进行边界框级的查询交互和迭代框细化。最后,使用重新评分策略从候选物体中选择正实例。
3. 方法
3.1 困难实例探测(HIP)
困难样本探测的表示:给定真实物体 O = { o i } i = 1 N G T \mathcal{O}=\{o_i\}_{i=1}^{N_GT} O={
oi}i=1NGT,这是初期阶段的主要目标。给定一组候选物体 A = { a i } i = 1 N O C \mathcal{A}=\{a_i\}_{i=1}^{N_OC} A={
ai}i=1NOC(可以是锚框、锚点或物体查询),神经网络预测其正负性。设第 k k k阶段预测的正样本为 P = { p i } i = 1 N P \mathcal{P}=\{p_i\}_{i=1}^{N_P} P={
pi}i=1NP,可将真实物体分配给预测物体,以分配情况为真实边界框确定类别: O k T P = { o j ∣ ∃ p i ∈ P k , σ ( p i , o j ) > η } \mathcal{O}_k^{TP}=\{o_j|\exist p_i\in \mathcal{P}_k,\sigma(p_i,o_j)>\eta\} OkTP={
oj∣∃pi∈Pk,σ(pi,oj)>η}其中 σ ( ⋅ , ⋅ ) \sigma(\cdot, \cdot) σ(⋅,⋅)为匹配指标(如IoU或中心距离), η \eta η为预定义的阈值。则剩余的未匹配的目标可视为困难实例: O k F N = O − ⋃ i = 1 k O k T P \mathcal{O}_k^{FN}=\mathcal{O}-\bigcup_{i=1}^k\mathcal{O}_k^{TP} OkFN=O−i=1⋃kOkTP第 k + 1 k+1 k+1个阶段的训练的目标是检测出 O k F N \mathcal{O}_k^{FN} OkFN,而忽略正预测。
由于本文从各个阶段收集候选物体,因此需要第二阶段的物体级细化模块消除FP。
3.2 多阶段热图编码器
BEV感知中中心热图的准备知识:中心热图的目标是在物体中心生成热图峰值。BEV热图用张量 S ∈ R X × Y × C S\in\mathbb{R}^{X\times Y\times C} S∈RX×Y×C表达,其中 X × Y X\times Y X×Y为BEV特征图的大小, C C C为类别数。目标热图是通过在物体BEV投影点附近生成2D高斯得到的。
正样本掩膜积累:为了跟踪正候选对象,本文在BEV上初始化全零的正样本掩膜(PM),并依照阶段进行积累得到积累正样本掩膜(APM): M ^ k ∈ { 0 , 1 } X × Y × C \hat{M}_k\in\{0,1\}^{X\times Y\times C} M^k∈{
0,1}X×Y×C 多阶段BEV特征是通过阶段之间的轻型逆残差块级联得到的。通过添加一层额外的卷积层,可以得到多阶段BEV热图。根据正样本预测结果,将BEV热图响应进行分数排序,生成正样本掩膜。具体来说,在第 k k k阶段,BEV热图所有位置、所有类别中的前 K K K个响应被选择为物体预测结果 P k \mathcal{P}_k Pk。正样本掩膜会记录所有正预测 p i ∈ P k p_i\in\mathcal{P}_k pi∈Pk的位置 ( x , y ) (x,y) (x,y)和类别 c c c,并将掩膜相应位置和类别的值设为1( M ( x , y , c ) = 1 M_{(x,y,c)}=1 M(x,y,c)=1),其余位置设为0。
上述掩膜生成方案仅填充候选物体中心点,称为点掩膜。本文提出另外两种掩膜生成方案:
- 基于池化的掩膜:小物体填充候选物体中心点,大型物体使用 3 × 3 3\times3 3×3大小的核填充。
- 边界框掩膜:为各阶段添加额外的边界框预测分支,掩膜填充预测边界框的内部区域。
第 k k k层积累正样本掩膜如下生成: M ^ k = max 1 ≤ i ≤ k M i \hat{M}_k=\max_{1\leq i\leq k}M_i M^k=1≤i≤kmaxMi然后,可以按照下式过滤热图的正样本区域并关注困难实例: S ^ k = S k ⋅ ( 1 − M ^ k ) \hat{S}_k=S_k\cdot(1-\hat{M}_k) S^k=Sk⋅(1−M^k)训练热图编码器时,对各层使用高斯focal损失,并求和得到总的热图损失。
收集所有阶段的候选物体送入第二阶段,重新评分并去除FP。
对HIP有效实施的讨论:掩膜方式需要满足以下条件以保证HIP的有效性:
- 在当前阶段排除过去的正候选物体;
- 避免移除潜在的真实物体。
点掩膜能满足上述条件,但与使用真实边界框掩膜的理想掩膜相比,对每个正预测只排除了一个BEV候选物体。因此基于池化的掩膜方法更有效。
3.3 边界框级的可变形解码器
候选物体可以视为带有位置信息的物体查询。增加候选物体数可以增加召回率,但冗余检测会增加FP。
本文将候选物体建模为边界框级的查询,并使用可变形注意力以提高效率。
边界框池化模块:使用RoIAlign从BEV特征中提取边界框上下文信息。具体来说,给定预测框,每个物体查询从BEV边界框中提取 7 × 7 7\times7 7×7的特征网格点,并通过2层MLP。位置编码被添加到查询和网格点中。
解码器实施:类似Deformable DETR,本文使用多头自注意力与多头可变形注意力。可变形注意力在3个尺度的BEV特征图上采样特征。边界框池化模块在每个旋转BEV边界框中采样,通过2层FC后将特征添加到查询嵌入中。采样时,将边界框放大到原来的1.2倍。
3.4 模型训练
模型按两个阶段训练。第一阶段使用Transformer解码头,训练激光雷达主干网络(对应的模型称为DeformFormer3D)。随后使用DeformFormer3D的权重初始化FocalFormer3D,训练多尺度热图编码器和边界框级的解码器。然而,在使用二部图匹配的可变形解码器时,训练初期会出现收敛缓慢的问题。因此,本文从真实物体生成噪声查询以解决这一问题。此外,匹配时会排除中心距离大于一定值的匹配对。
4. 实验
4.1 实验设置
数据集与指标:nuScenes数据集上除了官方指标外,还添加一个由中心距离定义的平均召回率(AR)指标。
4.2 主要结果
nuScenes基于激光雷达的3D目标检测:本文方法能达到SotA。比起使用额外分割级标注训练的模型仍能有更好的性能。
nuScenes多模态3D目标检测:本文使用预训练的图像主干提取图像特征,并将图像特征提升到预定义体素空间与基于激光雷达的BEV特征融合。不进行测试时数据增广(TTA)时,本文的方法能比sota有更好的性能,且推断时间更少;在一些少见的类别上性能较优。
nuScenes3D目标跟踪:使用SimpleTrack这一基于检测的跟踪算法,能比过去的sota更优;此外,使用TTA的FocalFormer3D能比使用模型集成的BEVFusion更优。
Waymo激光雷达3D目标检测:在不微调模型超参数的情况下,本文的模型能达到有竞争力的结果。
4.3 召回率分析
候选物体的召回率比较:仅使用激光雷达单一模态的FocalFormer3D能超过多模态方法。
最终预测的召回率比较:随着距离阈值的提高,多数方法最终预测的召回率(相比候选物体召回率的)提升减小。本文方法的召回率能大幅超过之前的方法。
逐类召回率比较:相比于TransFusion-L,FocalFormer3D在大型物体上的召回率更高。
4.4 消融研究
HIP查询大小和生成阶段:增加HIP层数或查询总数均能提高性能。
正样本掩膜类型:单点掩膜能比无掩膜方法有所提升;使用基于池化的掩膜能进一步提升性能。
逐步细化:虽然与CenterPoint相比,添加多阶段热图编码器的模型有明显更高的召回率,但在mAP和NDS上的提升很小。通过使用物体级别的重新评分、基于RoI的对齐,能进一步提高性能;使用边界框级的可变形解码器能大幅提高性能。
为评估重新评分的作用,本文设计了另一实验,在细化阶段仅进行重新评分以排除边界框回归的影响。实验表明,该方法相比于无细化阶段的模型有大幅性能提升。这说明初始阶段的热图评分存在局限。因此,第二阶段的重新评分是有用的。
模型组件的延迟分析:主要的计算时间位于基于稀疏卷积的激光雷达主干网络,而多阶段热图编码器和边界框级别的可变形解码器耗时占比较低。
5. 讨论
局限性:本文的HIP方法需要生成峰值在物体中心处的热图,可能不适用与基于相机的检测,因为相机的热图可能是扇状的。
附录
A. 额外消融实验
解码头的设计:和交叉注意力相比,堆叠多层可变形注意力能有更低的延迟和更好的性能。和点级查询相比,使用边界框级别的查询(即进行边界框池化)能有更高性能。
延迟分析:本文的方法能在性能和速度上均超过过去的方法。
B. 额外实施细节
nuScenes数据集的模型细节:将非关键帧积累到关键帧上输入模型;训练初期使用GT采样增广。
Waymo数据集的模型细节:使用单帧输入;训练初期使用GT采样增广。
扩展为多模态模型:为从投影后图像3D网格特征得到图像BEV特征,本文在每个柱体中使用交叉注意力:将激光雷达BEV网格特征视为查询,图像体素特征视为键与值。使用额外的卷积融合图像BEV特征和激光雷达BEV特征。该融合在多阶段热图编码器的各阶段均会进行。
C. 第二阶段细化的预测局部性
本文注意到,尽管使用了全局操作和相机透视图信息,小物体和大范围之间的差异限制了长距离二阶段细化。即与第一阶段的热图预测相比,多数方法在第二阶段的偏移量回归范围很小(即预测局部性),因此第二阶段补偿漏检(FN)的能力较弱。本文通过在BEV上确定FN并进行局部重新评分,能在一定程度上减轻这一问题。
D. 可视化示例
可视化结果:尽管本文方法的AR较高,但严重遮挡和缺少点会导致出现FN;错误的边界框方向预测也能导致FN出现。