
论文题目:来自模拟预训练的多模态 3D 对象检测
完整PDF英文论文下载:《Multimodal 3D Object Detection fromSimulated Pretraining》

自动驾驶应用中对模拟数据的需求变得越来越重要,无论是验证预训练模型还是训练新模型。为了使这些模型推广到现实世界的应用程序,基础数据集包含各种驾驶场景并且模拟的传感器读数与现实世界的传感器非常相似,这一点至关重要。我们展示了 Carla 自动数据集提取工具 (CADET),这是一种用于从 CARLA 模拟器生成训练数据以用于自动驾驶研究的新型工具。该工具能够导出具有对象注释的高质量、同步的激光雷达和相机数据,并提供配置以准确反映现实生活中的传感器阵列。此外,我们使用该工具生成由 10 000 个样本组成的数据集,并使用该数据集训练 3D 对象检测网络 AVOD-FPN,并对 KITTI 数据集进行微调,以评估有效预训练的潜力。我们还在鸟瞰图中展示了两种新颖的 LIDAR 特征图配置,用于可轻松修改的 AVOD-FPN。这些配置在 KITTI 和 CADET 数据集上进行了测试,以评估它们的性能以及模拟数据集在预训练中的可用性。虽然不足以完全替代真实世界数据的使用,并且通常不能超过在真实数据上进行充分训练的系统的性能,但我们的结果表明,模拟数据可以大大减少达到令人满意的真实数据水平所需的真实数据训练量准确性。


机器学习模型变得越来越复杂,架构更深,参数数量迅速增加。这种模型的表达能力比以往任何时候都允许更多的可能性,但需要大量的标记数据来正确训练。自动驾驶领域中的数据标记需要大量的体力劳动,要么是主动生成注释,例如手动生成类标签、边界框和语义分割,要么是通过使用预训练的集成来监督和调整这些的自动生成。来自先前标记数据的模型。对于现代传感器(如激光雷达)的使用,并不存在很多大型标记数据集,而那些通常在环境或天气条件方面提供很少变化的数据集以适当地允许泛化到现实世界条件。 KITTI 等流行数据集提供了大量传感器,但天气条件和照明基本不变,而更大、更多样化的 BDD100K 数据集不包括多模态传感器数据,仅提供相机和 GPS/IMU。引入对自动驾驶产生重大影响的新传感器的可能性也带来了使用现有数据集来训练最先进的解决方案无效的风险。

随着近年来计算机图形学领域的进步,无论是在真实感还是加速计算方面,由于生成不同场景的效率,仿真一直是在看不见的环境中验证自主模型的重要方法。最近,人们对使用现代模拟器生成用于训练自动驾驶汽车模型的数据产生了兴趣,包括感知和端到端强化学习。通过模拟生成训练数据有几个优点。只要有足够的计算资源,就可以快速生成具有不同条件的大型数据集,而标签可以完全自动化,几乎不需要监督。可以更容易地构建特定、困难的场景,并且可以添加先进的传感器,前提是它们已被准确建模。 NVIDIA Drive Constellation 等系统正在使用强大的 NVIDIA GPU 集群推动自动驾驶的逼真模拟,但目前仅适用于使用 NVIDIA Drive Pegasus AI 车载计算机的汽车制造商、初创公司和选定的研究机构,并且仅提供验证模型,而不是用于训练的数据生成。但是,基于 Unreal Engine 4 和 Unity 等最先进游戏引擎的开源解决方案目前正在积极开发中,并提供了一系列功能,使任何人都可以为自动驾驶生成高质量的模拟。值得注意的例子包括 CARLA 和 AirSim,前者用于本研究。


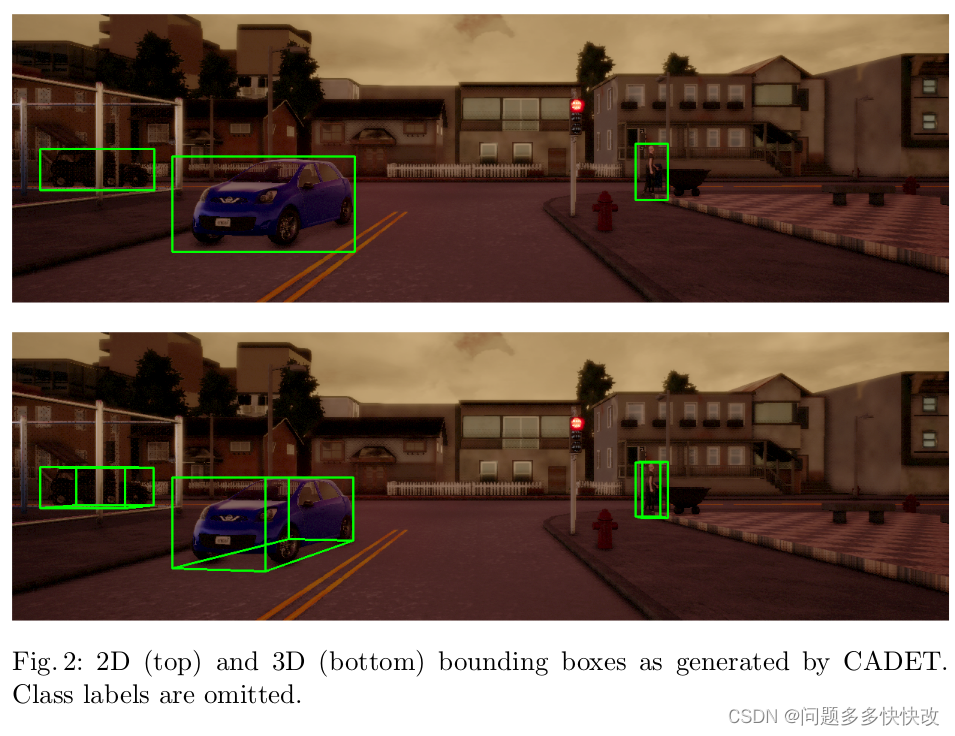
为了促进使用模拟数据对自动驾驶机器学习模型进行训练和验证,作者介绍了 Carla 自动数据集提取工具 (CADET),这是一种用于为自动驾驶模型生成标记数据的开源工具,与 Carla 0.8 兼容.该工具支持各种功能,包括 LIDAR 到相机的投影(图 1)、为汽车和行人生成 2D 和 3D 边界框标签(图 2)、检测部分遮挡的物体(图 3),以及生成传感器数据,包括 LIDAR、相机和地平面估计,以及传感器校准矩阵。所有标签和校准矩阵都以 Geiger 等人定义的数据格式存储。 [2],这使得它与许多现有的对象检测和分割模型兼容。由于多样化的数据集对于机器学习模型从模拟环境推广到现实生活场景至关重要,因此数据生成工具包括许多确保多样性的措施。最重要的是,该工具会在生成固定数量的样本后重置环境。在这里,样本被定义为包含来自每个传感器的读数、相应的地面实况标签和校准数据的元组。重置环境需要随机化车辆模型、生成位置、天气条件和地图,并确保天气类型、行人和汽车的代理模型以及所有车辆的起始位置的均匀分布。 LIDAR 和相机传感器的位置相同且同步,因此每个图像 1 都存在完整的 LIDAR 旋转。在确定场景中的可见对象之前,原始传感器数据被投影到虚幻引擎 4 中使用的统一坐标系,并投影到 KITTI 中使用的相对坐标空间。由于 CARLA 中的初始 LIDAR 配置忽略了它所连接的车辆的俯仰和滚动,因此在投影后应用了额外的变换,以便正确对齐传感器数据。生成对象标签时的一个挑战是确定当前场景中的可见对象。为了检测被遮挡的物体,使用了 CARLA 深度图。如果深度图中的一个相邻像素的值比顶点到相机的距离更近,则该顶点被定义为被遮挡。如果对象的八个边界框顶点中至少有四个被遮挡,则该对象被定义为被遮挡。这种遮挡检测的性能令人满意,而且比跟踪整个对象要快得多,即使对象位于诸如链栅栏之类的透视对象后面,如图 3 所示。可以通过使用语义分割来执行更稳健的遮挡检测场景,但这还没有实现。


我们使用 CADET 生成 CADET 数据集,由 10 000 个样本组成。数据集中总共有 13989 辆汽车和 4895 名行人,平均每张图像大约有 1.9 个标记对象。该数据集包含 Car 和 Pedestrian 类的 2D 和 3D 边界框注释,并包含 LIDAR 和相机传感器数据,以及地平面估计和传感器校准矩阵的生成。环境由两张地图生成,即CARLA模拟器中的Town01和Town02,它们都是郊区环境。每张图像中物体的分布如图8所示。与KITTI数据集相比,CADET数据集每张图像的汽车和行人较少,这主要是由于KITTI的城市环境,汽车经常停在一边道路和行人的存在程度更高。每个标记对象的方向如图 9 所示。我们观察到方向分布具有尖锐的多峰分布,具有三个峰值,即从前面、后面或侧面看到的对象。请注意,数据集中的行人通常比汽车具有更小的边界框,如图 7 所示,这使得它们更难检测。
为了评估模拟 CADET 数据集的使用,以及对 LIDAR 特征图表示进行实验,使用了 AVOD-FPN [6] 架构的几种配置,用于使用相机和 LIDAR 点云进行 3D 对象检测。已更改 AVOD-FPN 源代码以允许通过指定两个组(切片图和云图)所需的功能来进行自定义配置。切片图是指从点云被分割成的每个垂直切片中提取的特征图,如配置文件中所指定,而云图则考虑整个点云。按照 [6] 中描述的方法,两个网络分别用于检测汽车和行人,对每种配置重复该过程。由于多类检测在评估每类时也可能产生更不稳定的结果,因此这被认为是更好的选择。所有模型都使用特征金字塔网络从图像和激光雷达中提取特征,并早期融合提取的相机和激光雷达特征。使用翻转和抖动增强训练数据, 如第 4.1 节所述,同一类模型之间的唯一差异是鸟瞰图 (BEV) 中 LIDAR 特征图的各自表示。使用的所有配置都在源代码 [9] 中可用。


AVOD-FPN 使用基于 VGG-16 架构 [14] 的简化特征提取器从相机视图以及投影到 BEV 的 LIDAR 生成特征图,允许 LIDAR 由专为 2D 设计的卷积神经网络 (CNN) 处理图片。这些单独的特征图使用可训练的权重融合在一起,允许模型学习如何最好地组合多模态信息。除了将被称为默认 BEV 配置(如 [6] 中提出的那样)之外,还提出了两种额外的新配置,其实验结果要么显示出具有相似精度的更快推理,要么具有相似推理速度的更好精度。在所有情况下,BEV 都以 0.1m 的分辨率水平离散成单元。默认配置在指定的高度范围内创建 5 个大小相等的垂直切片,取每个单元格中的最高点,由切片高度标准化。整个点云密度的单独图像是根据公式 1 从每个单元格中的点数 N 生成的,如 [6] 和 [7] 中使用的,尽管在后者中由 log(64) 进行归一化。我们提出了一种简化的结构,取整个点云上每个单元的全局最大高度、最小高度和密度,避免使用切片并将 BEV 图的数量减半。我们认为这足以确定哪些点属于大对象,哪些是异常值,并且它充分定义了框尺寸。对于占用较少空间的类,我们认为使用每个切片的最大高度和密度垂直截取三个切片可以更好地执行且不易受噪声影响,因为网络可能会学习区分是否 切片的最大高度值是否属于对象取决于切片密度。所有配置都在图 4-6 中进行了可视化。


为了收集定性结果,每个模型在各自的数据集上总共训练了 120k 步,批量大小为 1,如 [6] 中所述。 每 2k 步存储检查点,其中选择最后 20 个进行评估。 表 1 和表 2 显示了在 KITTI 数据集上生成的结果,分别针对 Car 和 Pedestrian 类,为 3 种 BEV 配置中的每一种选择了性能最佳的检查点。 为了测量推理速度,每个模型使用 NVIDIA GTX 1080 显卡对验证集的前 2000 张图像进行推理,并禁用学习。 平均推理时间四舍五入到最接近的毫秒,并在表格中显示。

在对 KITTI 数据集进行评估之后,所有配置都是按照完全相同的过程在生成的 CADET 数据集上从头开始训练的。 CADET 数据集验证集的评估结果见表 3 和表 4。请注意,由于动态遮挡和截断测量不包括在数据集中(这些仅用于 KITTI 中的训练后评估),因此评估不遵循 KITTI 中使用的常规简单、中等、困难类别。相反,对象被分类为大或小,遵循 40 像素的边界框的最小高度要求,简单的边界框和 25 像素的中等和困难的边界框。这些模型还直接在 KITTI 验证集上进行了评估,结果汇总在表 5 和表 6 中。CADET 训练的模型随后在第 90k 步从其检查点恢复,并进行了修改以在 KITTI 数据集上进行进一步训练。训练恢复到第 150k 步,这意味着模型在 KITTI 训练集上接受了 60k 步的训练,而不是最初的 120k。除了增加步数和切换目标数据集外,配置文件在 CADET 数据集上训练时没有改变。表 7 和表 8 显示了每个模型的表现最好的检查点的结果。

对于完全 KITTI 训练的模型,Car 类的结果对于所有配置都非常相似,其中从默认配置到我们使用一半层数的配置的简单类别中,最大损失仅为 0.5% 3D AP纯电动汽车地图。对于 Pedestrian 类,更大的差异很明显,其中 3 层不足以与默认配置竞争。然而,使用 3 个最大高度和密度的切片,总共 6 层,与默认配置一样,显示出明显更好的结果,表明更稳健的行为。在 CADET 验证集上对 CADET 训练模型的评估显示模型之间的相对性能相似,但是更简单的自定义配置显示汽车类别的中等类别的准确度下降。关于行人,差异比预期的要小得多。还考虑到 KITTI 数据集的行人类的不显着且相当不一致的性能,我们可能认为这是对模拟 LIDAR 点云中可见的行人物理碰撞的过度简化表示。然而,经过 CADET 训练的模型在汽车类上的表现确实更好,这表明该任务可以更好、更一致地泛化。
微调后的模型在 Car 类上的性能与完全 KITTI 训练的模型基本相似,但是每个模型在简单或中等类别上的性能都有明显下降。 Pedestrian 类的结果更有趣一些。默认配置中,中等和困难类别的准确度略有提高,而简单类别的准确度略有下降。最大/密度配置在所有类别上的性能都显着下降,而不太复杂的最大/最小/密度配置虽然仍然是性能最弱的配置,但与仅在 KITTI 数据集上训练时相比,性能显着提高。与 KITTI 训练的模型相比,结果相当不一致的原因尚未得到彻底调查,但部分原因可能是由于梯度有些不稳定,无法产生完全可靠的结果。由于所有动态对象的简单碰撞,CARLA 生成的 LIDAR 点云不具有精确的几何形状。因此,在对 CADET 数据集进行预训练期间,可能无法利用配置的不同功能,从而影响整体结果。显着缩小行人类别差距的最简单配置可能证明了这一点,因为简化的行人表示更容易识别。虽然模拟和部分模拟训练的结果通常不会超过在数据集上直接训练的性能,但有一个明确的迹象表明,使用模拟数据可以在减少对实际数据的训练的情况下实现紧密匹配的性能。就传感器、场景、环境和条件而言,易于生成和可扩展性使得 CADET 等工具对于训练和评估自动驾驶模型非常有用,尽管在它们足以训练现实世界的解决方案之前需要改进。

近年来,由于收集现实生活数据的成本,使用合成数据来训练机器学习模型变得越来越流行。这在自动驾驶方面尤其如此,因为对广泛性的严格要求的驾驶场景。在这项研究中,我们描述了 CADET——一种用于生成大量训练数据以用于自动驾驶感知的工具,以及由此产生的数据集。我们已经证明,这个数据集虽然不足以直接训练用于现实世界的系统,但对于将训练机器学习模型所需的真实数据量降低到相当高的准确度水平很有用。我们还建议并评估了两种新颖的 BEV 表示,它们在训练之前很容易配置,分别具有更好地检测较小对象和降低检测较大对象的复杂性的潜力。 CADET 工具包虽然仍需要改进 LIDAR 建模中的物理模型,但目前能够生成数据集,用于训练和验证几乎任何为 KITTI 对象检测任务设计的模型。

