1 训练集ex6data2.mat可视化
绘制训练集函数plotData.m
同机器学习(20)中的plotData.m
训练集可视化脚本GaussianSVM部分代码
%% Initialization
clear ; close all; clc
%% =============== Part 1: 加载并可视化数据 ================
fprintf('Loading and Visualizing Data ...\n')
% 从文件 ex6data2.mat中加载,会发现环境中有X,y变量值:
load('ex6data2.mat');
% 绘制训练集数据
plotData(X, y);
fprintf('Program paused. Press enter to continue.\n');
pause;
执行结果
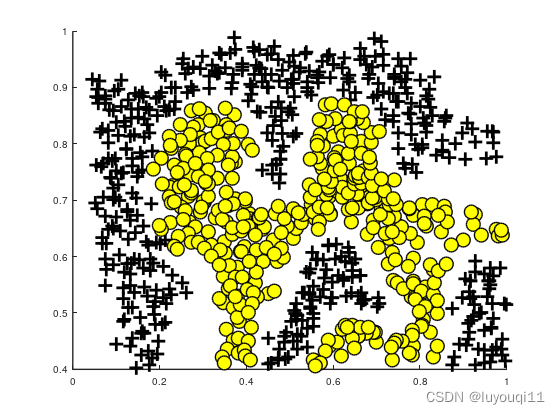
可以看到这里的数据集分两类,但SVM的决策边界是个曲线。且边界清晰
2 SVM的高斯核函数gaussianKernel.m
function sim = gaussianKernel(x1, x2, sigma)
% gaussianKernel(x1, x2, sigma)返回一个在x1和x2之间的径向基函数核,
% 输入参数: x1,x2 列向量。确保x1和x2是维度一致的列向量
% 返 回 值: sim 返回一个在x1和x2之间的高斯核
x1 = x1(:); x2 = x2(:);
% You need to return the following variables correctly.
sim = 0;
sim = exp(-sum((x1-x2).^2)/(2*sigma^2));
end
3 训练函数svmTrain.m
同机器学习(20)中的svmTrain.m
4 预测函数svmPredict.m
function pred = svmPredict(model, X)
% svmPredict(model, X)返回使用经过训练的SVM模型的预测向量
% 输入: model 由svmTrain函数得出的模型
% X 训练矩阵,行数为样本数,列数为输入特征数
% 输出: pred 是一个行数为样本数,列数为1的{0,1}值的预测列向量。
% 检查我们是否得到了一个列向量,如果是,那么假设我们只有需要对单个例子进行预测
if (size(X, 2) == 1)
% Examples should be in rows
X = X';
endif
% 数据集
m = size(X, 1); %样本数
p = zeros(m, 1); % 初始化列向量的元素为0
pred = zeros(m, 1); % 初始化列向量的元素为0
if strcmp(func2str(model.kernelFunction), 'linearKernel')
% 如果使用线性核函数,我们可以直接使用权值和偏差
p = X * model.w + model.b;
elseif strfind(func2str(model.kernelFunction), 'gaussianKernel')
% 矢量化RBF核
% 这相当于在每一对例子上计算内核
X1 = sum(X.^2, 2);
X2 = sum(model.X.^2, 2)';
K = bsxfun(@plus, X1, bsxfun(@plus, X2, - 2 * X * model.X'));
K = model.kernelFunction(1, 0) .^ K;
K = bsxfun(@times, model.y', K);
K = bsxfun(@times, model.alphas', K);
p = sum(K, 2);
else
% 其他非线性核
for i = 1:m
prediction = 0;
for j = 1:size(model.X, 1)
prediction = prediction + ...
model.alphas(j) * model.y(j) * ...
model.kernelFunction(X(i,:)', model.X(j,:)');
endfor
p(i) = prediction + model.b;
endfor
endif
% 将预测转换为0 / 1
pred(p >= 0) = 1;
pred(p < 0) = 0;
end
5 可视化SVM决策边界函数visualizeBoundary.m
function visualizeBoundary(X, y, model, varargin)
% visualizeBoundary绘制支持向量机学习到的非线性决策边界
% 输入: X 训练矩阵,行数为样本数,列数为输入特征数
% y 训练集输出特征向量,是一个包含1和0的列向量,行数为样本数,列数为1
% model 由svmTrain函数得出的模型
% varargin
plotData(X, y) % 绘制训练数据
% 对一个值网格进行分类预测
x1plot = linspace(min(X(:,1)), max(X(:,1)), 100)';
x2plot = linspace(min(X(:,2)), max(X(:,2)), 100)';
[X1, X2] = meshgrid(x1plot, x2plot);
vals = zeros(size(X1));
for i = 1:size(X1, 2)
this_X = [X1(:, i), X2(:, i)];
vals(:, i) = svmPredict(model, this_X);
endfor
% 绘制SVM决策边界
hold on
contour(X1, X2, vals, [0.5 0.5], 'b');
hold off;
end
6 非线性SVM脚本GaussianSVM.m
%% Initialization
clear ; close all; clc
%% =============== Part 1: 加载并可视化数据 ================
fprintf('Loading and Visualizing Data ...\n')
% 从文件 ex6data2.mat中加载,会发现环境中有X,y变量值:
load('ex6data2.mat');
% 绘制训练集数据
plotData(X, y);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ==================== Part 2: 线性SVM训练 ====================
% 在实现了内核之后,我们现在可以使用它来训练SVM分类器。
% 从文件 ex6data2.mat中加载,会发现环境中有X,y变量值:
fprintf('\nTraining SVM with RBF Kernel (this may take 1 to 2 minutes) ...\n');
% Load from ex6data2:
% You will have X, y in your environment
load('ex6data2.mat');
% SVM 参数
C = 1; sigma = 0.1;
% 我们在这里将容忍度和max_passes设置得更低,
% 以便代码运行得更快。然而,在实践中,您将希望将训练运行到收敛。
model= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma));
visualizeBoundary(X, y, model);
fprintf('Program paused. Press enter to continue.\n');
pause;
7 执行脚本GaussianSVM.m结果

左图无法用一个线性决策边界划分正负样本数据。
右图是用高斯核SVM训练的决策边界。这个决策边界能够正确分离大多数的正负样本,并且能很好的拟合数据。