机器学习中一般用的比较多的是集成学习算法如bagging和boosting,以及SVM。这2个算法的效果好。且对数据的分布没有啥要求。今天要讲的是SVM即支持向量机。
SVM的定义
支持向量机(Support Vecor Machine, SVM)本身是一个二元分类算法,是
对感知器算法模型的一种扩展,现在的SVM算法支持线性分类和非线性分
类的分类应用,并且也能够直接将SVM应用于回归应用中,同时通过OvR
或者OvO的方式我们也可以将SVM应用在多元分类领域中。在不考虑集成
学习算法,不考虑特定的数据集的时候,在分类算法中SVM可以说是特别
优秀的。
SVM可以对线性可分数据进行分类,也能对非线性的数据进行分类。是不是感觉很强大?
对于线性可分数据,算法可以在数据中找到一个直线(平面或者超平面)让尽可能多的数据分布在两侧,从而达到分类的效果,但是这样的平面可能不止一个。为啥是尽可能多呢?原因很简单一方面我们找到的一个近似分类比较好的平面,另一方面数据中存在噪音,不可能对噪音都划分的很好。
我们可以找到多个可以分类的超平面将数据分开,并且优化时希望所有的点(预测正确的点)都离超平面尽可能的远,但是实际上离超平面足够远的点基本上都是被正确分类的,所以这个是没有意义的;反而比较关心那些离超平面很近的点,这些点比较容易分错。所以说我们只要让离超平面比较近的点尽可能的远离这个超平面,那么我们的模型分类效果应该就会比较不错喽。SVM其实就是这个思想。说完了划分规则,那么划分完以后如何来评估这样的划分的效果呢?
上面说到了我们只关心离超平面近的点,因为超平面离这些点的距离决定了稳定性,容错性。那么就有一个概念出来了,对于这些离超平面近的点我们称之为支持向量。支持向量到超平面上的距离称之为间隔。距离L:
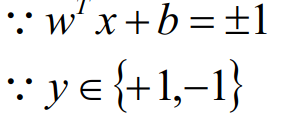
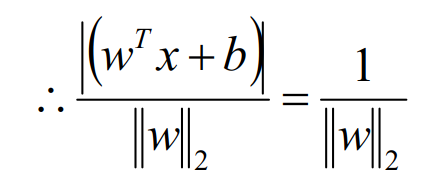
备注:在SVM中习惯性的将间隔设置为1,这是不影响推导结果的。
每一种模型都会一个衡量指标,我们常称之为目标函数或者loss。而对于衡量一个SVM的好坏,我们用间隔衡量,间隔越大,则越好即目标是下面的式子
对于上面的问题,我们可以进行一个转换:

即反过来求||W||式子的最小值,从最大值问题转换成最小值问题,这两者是等价的。
从而SVM原始函数的损失值为:

因为目标函数和约束函数满足KKT条件。
所以可以将损失函数最终变成:
即引入拉格朗日乘子后,优化目标变成:
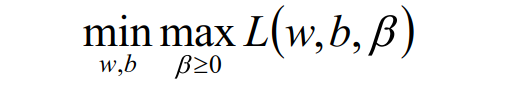
根据拉格朗日对偶化特性,将该优化目标转换为等价的对偶问题
来求解,从而优化目标变成: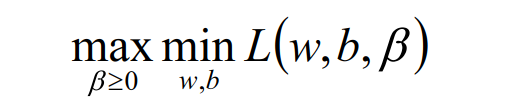
要是还不明白,可以参考下图:

所以对于该优化函数而言,可以先求优化函数对于w和b的极小
值,然后再求解对于拉格朗日乘子β的极大值。
首先求让函数L极小化的时候w和b的取值,这个极值可以直接通
过对函数L分别求w和b的偏导数得到:
将求解出来的w和b带入优化函数L中,定义优化之后的函数如下:
假设存在最优解β*; 根据w、b和β的关系,可以分别计算出对应的
w值和b值(一般使用所有支持向量的计算均值来作为实际的b值);
这里的(xs,ys)即支持向量,根据KKT条件中的对偶互补条件(松弛条
件约束),支持向量必须满足一下公式: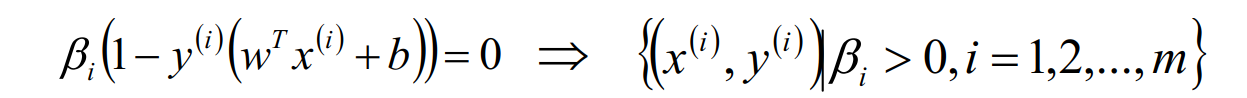
线性可分SVM算法流程

以上就是线性可分情况的SVM。对于非线性可分的数据,可以通过核函数求得对应的权重和偏置。这就是本人学习SVM后的总结 。
【机器学习四】SVM
猜你喜欢
转载自blog.csdn.net/weixin_35389463/article/details/84594778
今日推荐
周排行