Introduction
支持向量机(Support Vector Machine,SVM)是定义在特征空间中的最大间隔线性分类器,对于非线性可分的数据,SVM引入核方法(kernel trick)使它实质上成为非线性分类器。SVM 有两种解释
- 求解间隔最大的分类平面,这种情况可以转化为一个求解凸二次规划的问题,一般转换为对偶问题求解;
- Hinge Loss,通过经验风险最小化,采取 Hinge Loss 来求得损失函数,最终对损失函数求极值即可。
本文主要讲解的是二次规划转对偶求解的方式,Hinge Loss解释参考支持向量机之Hinge Loss 解释,下面步入正题,首先引入线性可分的概念。
线性可分

超平面一般会写成,表明w,x都为列向量。
最大化几何间隔提出目标函数
一般来说,训练样本距离分类超平面的远近可以表示分类预测的确信程度,下图中点 C 的类别为 -1 确信程度要明显高于点 A 。
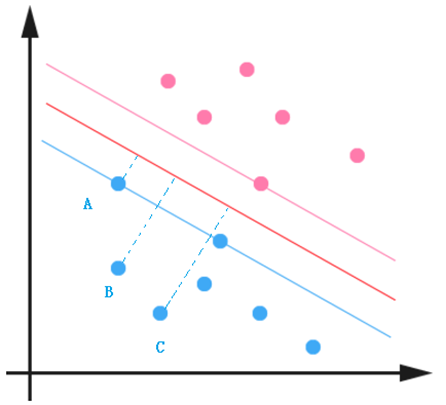
该确信程度可以用样本到超平面的距离来表示,该距离便是常说的几何距离(点到直线的距离)。样本点 到分类平面
的几何距离如下所示:

分子要取绝对值(距离为正值),分母为 L2 范数:,训练样例中若
,则对应的标签为
,反之,若
,则有
,所以将几何间隔写作如下形式:
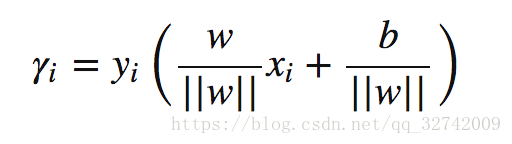
合并一下就是这个东西。
函数间隔:
且整个数据集的函数间隔为:
这里之所以引入函数间隔,是因为其是可以自由缩放大小的,比如对于分类超平面 ,若左右同时扩大
倍,
,分类平面不会发生任何改变,但是对于点
的函数间隔为:
在函数间隔也扩大了 倍的情况下,分类超平面没与几何间隔(超平面没变,点没变,几何间隔当然不变)却没变。
所以并不会对我们的优化函数产生一丝影响,因为优化目标是最大化几何间隔的,也就是说缩放分类超平面参数不会对最终的结果产生影响,进一步可将几何间隔化成含有函数间隔的形式:
由于函数间隔不受scale的影响,我们指定,则有
,即
最终我们得到目标函数
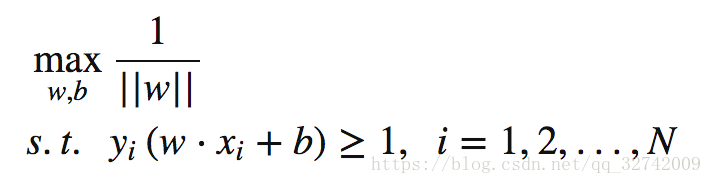
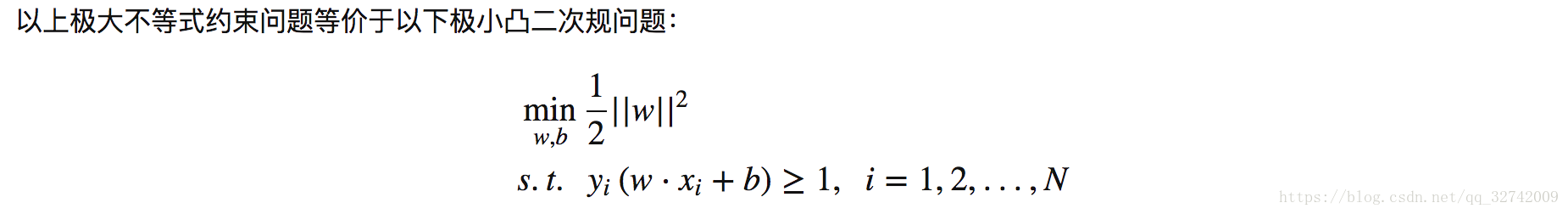
Algorithm 1.1
综上,提炼出线性可分情况下 SVM 的学习算法,算法1.1:

线性可分 SVM 中到分类超平面的距离为
,因为之前我们在不影响结果的情况下,人为设定最小函数间隔
,也就是说离超平面最近的点函数间隔为 1,这些点也就是之后要提到的支持向量support vector。
接下来主要讲解如何求解算法1.1中的不等式约束二次规划问题,二次规划是一个凸优化问题,求解该问题需要许多最优化算法的知识,之前写过三篇文章,算是 SVM 的基础,只要这两篇搞懂,SVM 就是浮云,本节许多结论不去细说。均来自之前的博文。
拉格朗日乘子法、KKT条件、对偶变换
现在回到之前的优化目标,也即原始问题:
这里把不等式约束优化写成了常见的 的形式,接下来首先构造拉格朗日函数(无约束问题):
有下式成立:
这个证明在前一篇对偶理论中有讲到,稍微再提一嘴,,如果满足不等式约束则必定有
,即只有当
的时候
才会不等于0,其它时候都为0,为取到函数最大。如果
了,那么
就会取到正无穷大,此时函数无解,符合题意。
目标函数化为:
转化为对偶问题:
在SVM中引入对偶的好处为:
- 对偶问题必为凸优化问题.;
- 对偶问题是原始问题的下界,当满足一定条件,两者等价;
- 引入对偶问题之后,可以自然而然的引入核函数。
满足KKT条件(这里没有等式约束):
故原问题与对偶问题具有强对偶性。原问题的最优解与对偶问题的最优解相同。
求解KKT条件1有:
将结果代入对偶函数中有:
现在大功告成,只要求解对偶问题得到 ,然后根据 KKT 条件得到
,就可以完美的解得原始问题的最优解了,经过以上几步,便得到了最终的线性可分支持向量机学习算法,算法1.2:
Algorithm 1.2

但Data Mining的书上写的是先将KKT条件与联立,然后采用优化算法求解。SMO算法还没了解过,这两种方式应该都大同小异吧。
这里顺便明确给出支持向量的定义:根据KKT条件:
的样本点
即为间隔边界上的支持向量,且
;
- 对于非支持向量,即
,一定有
。
至此,关于线性可分情况下的二分类 SVM 全部推到完成,但是有一个问题:当数据中存在一些异常值(outlier),去除这些 outlier 后数据是线性可分的,这种情况下要引入关于异常值的处理。
下一篇会讲基本线性可分的SVM。
参考文章: