Paper name
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Paper Reading Note
URL: https://arxiv.org/abs/2201.12086
TL;DR
- ICML 2022 文章,提出了BLIP,一种新的 Vision-Language Pre-training (VLP) 框架,同时提出了一种图像文本对的数据集清洗方法
Introduction
背景
- 大多数现有的预训练模型仅在基于理解的任务或基于生成的任务中表现出色
- 此外,通过使用从网络收集的有噪声的图像-文本对放大数据集,在很大程度上提高了性能,这是次优的监督来源
本文方案
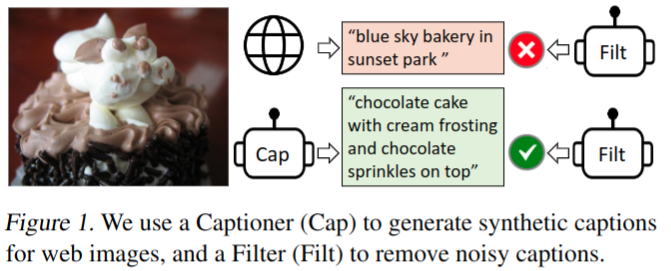
-
提出了BLIP,一种新的 Vision-Language Pre-training (VLP) 框架,它可以灵活地转移到视觉语言理解和生成任务中
- 通过引导 caption 来有效地利用有噪声的网络数据,其中 captioner 生成合成 caption,filter 去除有噪声的 caption
-
在广泛的视觉语言任务上取得了最先进的结果,例如图像文本检索(平均+2.7%recall@1)、图像字幕(CIDEr中+2.8%)和VQA(VQA得分+1.6%)
-
本文主要贡献
- Multimodal mixture of Encoder-Decoder (MED):一种有效的多任务预训练和灵活迁移学习的新模型体系结构。MED 既可以作为单模态编码器,也可以作为基于图像的文本编码器,或基于图像的文字解码器。该模型与三个视觉语言目标联合预训练:图像文本对比学习、图像文本匹配和图像条件语言建模
- Captioning and Filtering (CapFilt):一种从噪声图像文本对中学习的新数据集增强方法。将预先训练的 MED 微调为两个模块:一个用于生成给定网络图像的合成 caption 的 captioner,以及一个用于从原始网络文本和合成文本中去除噪声 caption 的 filter
Dataset/Algorithm/Model/Experiment Detail
实现方式
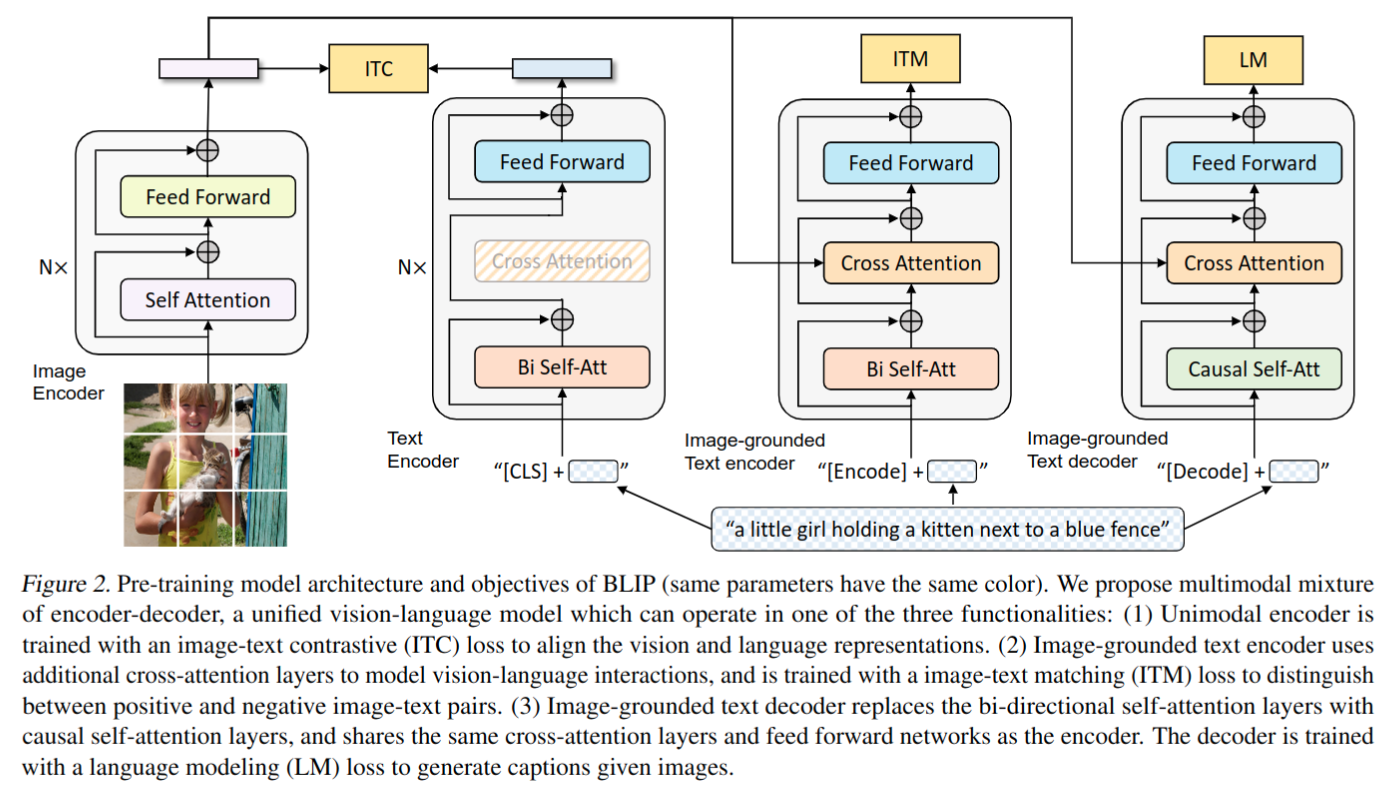
模型结构
- 提出 multimodal mixture of encoder-decoder (MED):
- Unimodal encoder:
- text encoder 是 BERT
- image encoder 使用 ViT
- Image-grounded text encoder
- 通过在自关注(SA)层和前馈网络(FFN)之间为文本编码器的每个 transformer 块插入一个附加的交叉关注(CA)层来注入视觉信息。特定于任务的[Encode]标记被附加到文本,[Encode]的输出嵌入被用作图像-文本对的多模态表示
- Image-grounded text decoder
- 用因果自关注层替换基于图像的文本编码器中的双向自关注层。[Decode]标记用于表示序列的开始,序列结束标记用于表示其结束
- Unimodal encoder:
Pre-training Objectives
- 联合优化了三个目标,包括两个基于理解的目标和一个基于生成的目标,每个图像-文本对只需要一次前向通过计算量较大的视觉转换器,三次前向通过文本转换器
- Image-Text Contrastive Loss (ITC):集成 ALBEF 中的 ITC 损失。通过鼓励正面图像文本对具有相似的表示,负面图像文本相反,对齐视觉变换器和文本变换器的特征空间
- Image-Text Matching Loss (ITM):旨在学习图像-文本多模态表示,捕捉视觉和语言之间的细粒度对齐。ITM是一个二分类任务,给定其多模态特征,其中模型使用ITM头(线性层)来预测图像文本对是正(匹配)还是负(不匹配)
- Language Modeling Loss (LM):旨在生成给定图像的文本描述。优化交叉熵损失,该损失训练模型以自回归方式最大化文本的可能性
CapFilt
- 背景
- 有标注数据集类似 COCO 这样包含图像与文本的数据集较少
- 网络收集的图片文本对一般准确性较差
- 提出 Captioning and Filtering (CapFilt),一种提高文本语料库质量的新方法
- 基于两个子模型清洗网络数据集
- captioner:对给定的网络图片生成 captions,基于 LM 损失训练
- filter:移除有噪声的图片文本对,基于 ITC and ITM 损失训练;去除原始web文本Tw和合成文本Ts中的噪声文本,如果 ITM 头预测文本与图像不匹配,则认为文本有噪声,移除该文本
- 以上两个模型基于 MED 初始化,分别在 COCO 上 finetune
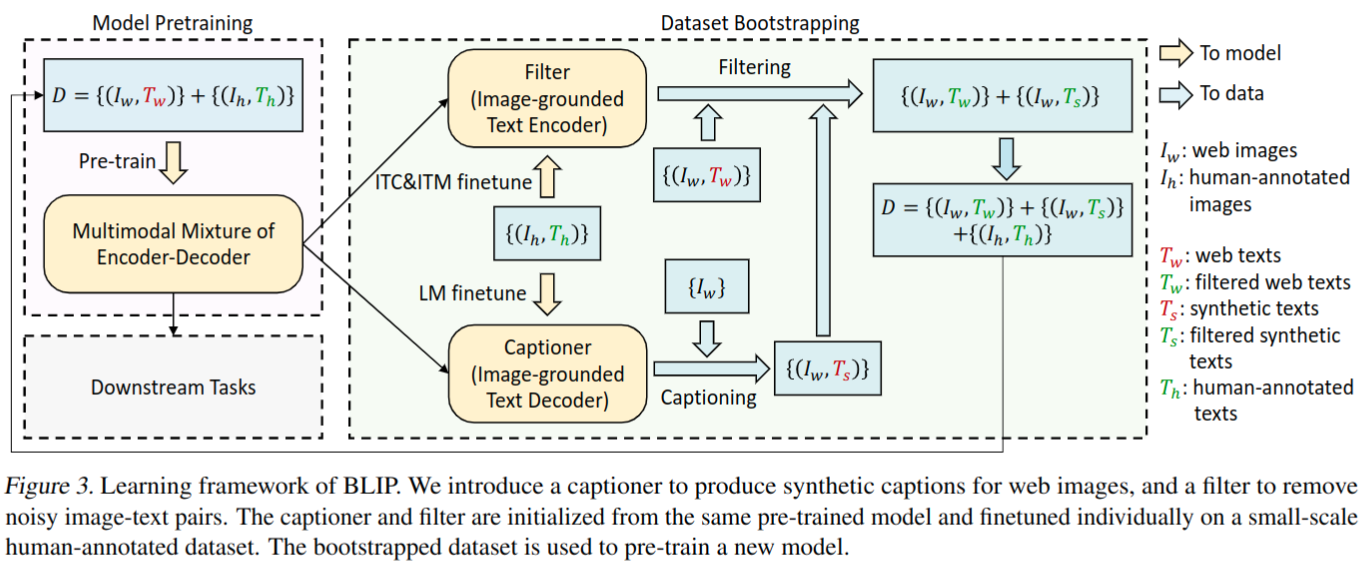
- 基于两个子模型清洗网络数据集
- 将清洗后的网络数据与 COCO 等标注数据合并后用于模型 pretrain
实验结果
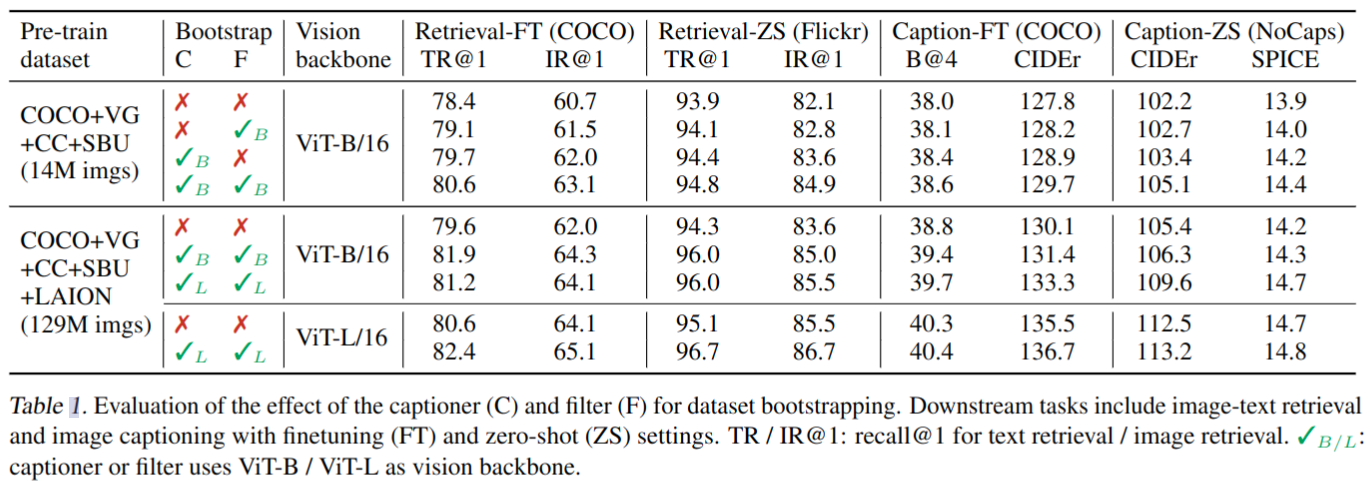
Effect of CapFilt
- 清洗数据集后有明显涨点,训练数据量更大精度更高(即便不清洗数据也是一样结论)
- caption 示例,前两个看起来能过滤掉与图像不想关的网络文本

Diversity is Key for Synthetic Captions
- 使用 nucleus sampling 来生成合成 caption,nucleus sampling 是一种随机解码方法,其中每个 token 从一组累积概率质量超过阈值 p (p = 0.9) 的 tokens 中采样;与 beam search 方法(旨在以最高概率生成 caption 的确定性解码方法)相比,nucleus sampling 精度更高,原因可能是 nucleus sampling 产生的结果更多变

与 SOTA 模型对比
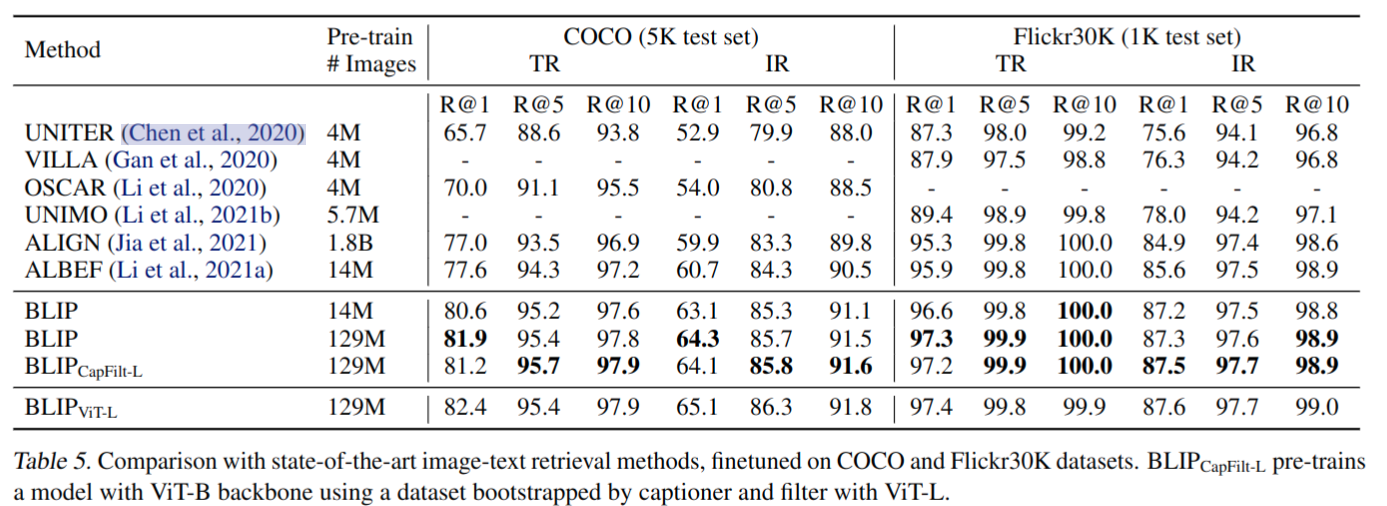
- Image-Text Retrieval
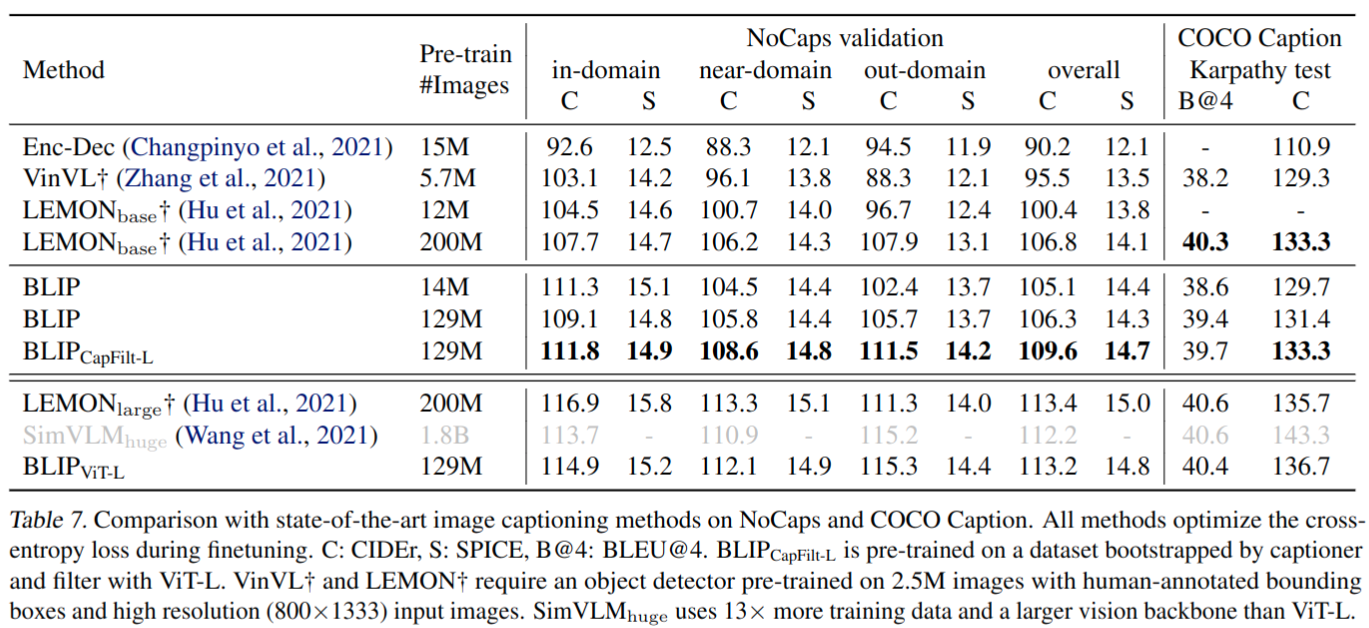
- Image Captioning
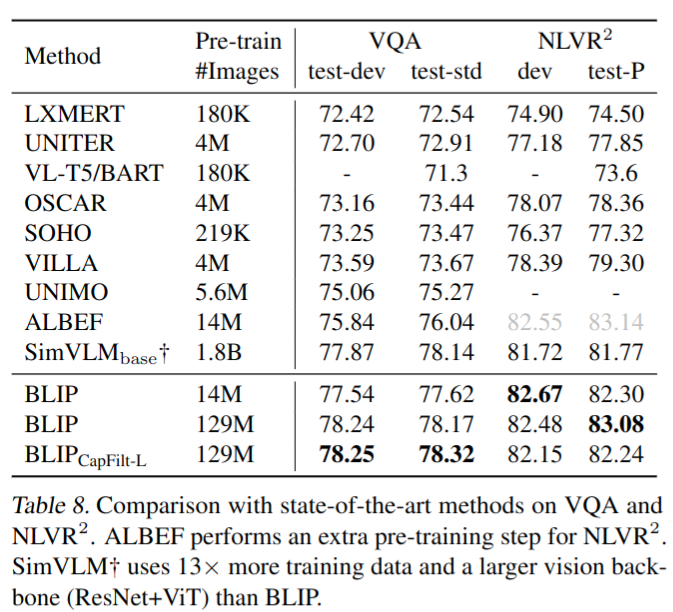
- Visual Question Answering (VQA)
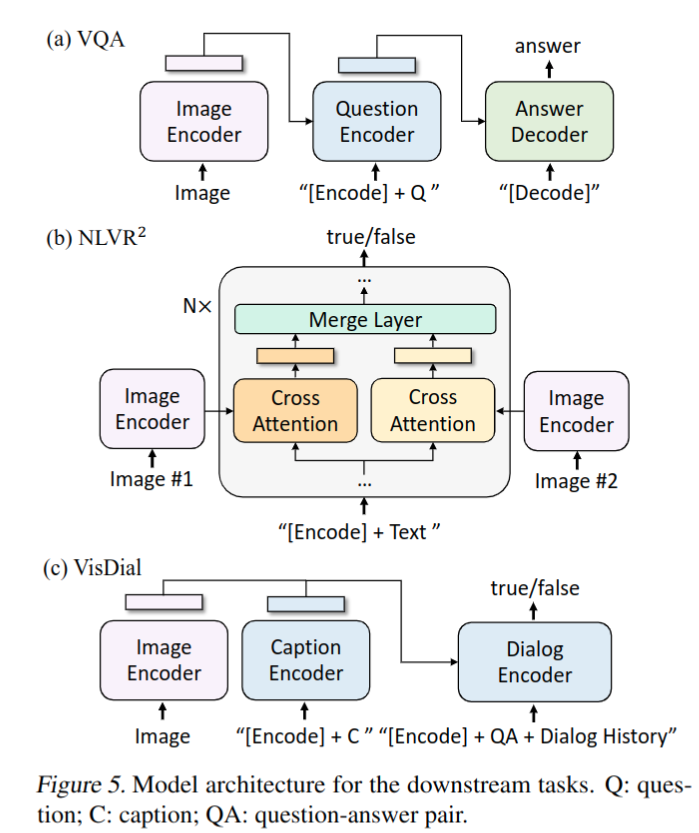
- 在微调过程中,重新排列预训练的模型,其中图像问题首先被编码为多模态嵌入,然后被提供给答案解码器;基于 LM 损失进行 finetune
Thoughts
- 训练 loss 与技巧主要是继承之前工作,主要创新点在融合多模态数据的模型结构设计和数据集清洗上