Multi-Grained Vision Language Pre-Training: Aligning Texts with VisualConcepts多粒度视觉语言预训练: 文本与视觉概念的对齐
本文贡献
- 提出进行多粒度的视觉语言预训练,以处理文本和视觉概念之间的对齐问题。
- 提出通过定位图像中的视觉概念来优化模型(X-VLM),并同时将文本与视觉概念对齐,其中的对齐是多粒度的。
- 通过经验验证,我们的方法在微调中有效地利用了学到的多粒度对齐。 具有256×256图像分辨率的X-VLMbase在许多下游的V+L任务上比现有的最先进的方法取得了实质性的改进。
摘要
大多数现有的视觉语言预训练方法都依赖于通过目标检测器提取的以对象为中心的特征,并在提取的特征和文本之间进行细粒度的对齐。对于这些方法来说,学习多个对象之间的关系是具有挑战性的。为此,我们提出了一种称为X-VLM的新方法来进行“多粒度视觉语言预训练”。学习多粒度对齐的关键是在给定相关文本的情况下定位图像中的视觉概念,同时将文本与视觉概念对齐,其中对齐是多粒度的。实验结果表明,X-VLM有效地利用了学习到的多粒度对齐来执行许多下游视觉语言任务,并始终优于最先进的方法。
简介
现有的学习视觉语言对齐的方法可以分为两种,如图1,大多数检测图像中的对象,并将文本与细粒度(以对象为中心)的特征对齐。它们要么利用预训练好的对象检测器,或者在预训练过程中进行实时对象检测。其它方法不依赖于目标检测,而是只学习文本和图像的粗粒度特征之间的对齐。

图1:(a)现有的基于目标检测的方法,(b)将文本与整个图像对齐的方法,以及( c)我们的方法的比较。
多粒度模型X-VLM,由一个图像编码器、一个文本编码器和一个跨模式编码器组成,该编码器在视觉特征和语言特征之间进行交叉注意,以学习视觉-语言的排列。 X-VLM利用一个简单的混合注意力机制来实现图像编码器,因此编码器产生一个具有完全注意力的图像表示和具有局部注意力的区域/物体表示。X-VLM的学习是通过给定相关文本在图像中定位视觉概念来优化的,同时将文本与视觉概念对齐,例如通过对比损失、匹配损失和屏蔽语言建模损失,其中的对齐是多粒度的,如图1(c)所示。 在微调和推理中,如果没有输入图像中的边框注释,X-VLM仍然可以利用学习到的多粒度对齐方式来执行下游的V+L任务。
相关工作
现有的视觉语言预训练工作分为两类:细粒度和粗粒度。
大多数现有的方法属于细粒度方法,它依赖于物体检测。物体检测器首先确定所有可能包含物体的区域,然后对每个区域进行物体分类。然后,一幅图像由识别出的区域的几十个以物体为中心的特征来表示。 这种方法的挑战在于,基于以物体为中心的特征的VLMs不能代表多个区域中多个物体之间的关系。此外,事先定义物体的类别并不容易,这对学习VLMs是有帮助的。
粗粒度方法通过卷积网络或视觉transformer提取和编码整体图像特征建立VLMs。虽然以物体为中心的特征只与某些物体有关,但细粒度的特征对于学习VLMs似乎至关重要。为了解决这个问题,Huang在整体图像特征上采用在线聚类来获得更全面的表征,Kim使用更先进的视觉transformer,即Swin-Transformer进行图像编码,ALBEF结合了对比学习和动量蒸馏。然而,当训练语料库的数量级相同时,这些改进仍然无法缩小与精细化方法的差距。 与之前采用细粒度或粗粒度方法的工作不同,我们提出了多粒度的视觉语言预训练。
方法
X-VLM由一个图像编码器(I-trans)、一个文本编码器(T-trans)和一个跨模态编码器(X-trans)组成。所有编码器都是基于Transformer的。 我们重新制定了广泛使用的预训练数据集,以便一个图像可以有多个由边界框包围的区域,并且每个区域都与描述物体或区域的文本相关联,表示为(I,T,{(Vj,Tj)}N)。 请注意,有些图像没有相关的文本,即T是NaN,有些图像没有边界框,即N=0。这里,Vj是图像中的一个物体或区域,它与边界框bj=(cx,cy,w,h)相关,由该框的标准化中心坐标、宽度和高度表示。
图像编码器
我们提出了一个简单的混合注意力机制,它是基于图2所示的视觉transformer。它以较低的计算开销,在图像中产生多粒度的视觉概念表示。
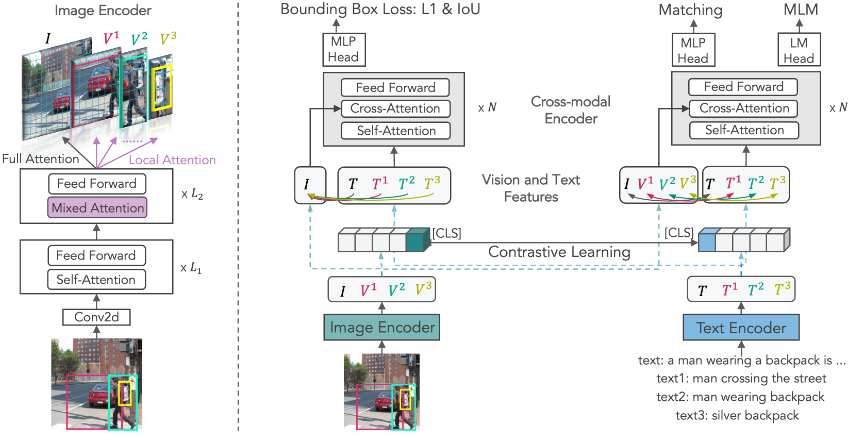
图2:提出的多粒度视觉语言预训练方法示意图
编码器首先将一幅图像分割成不重叠的16x16个块,并将所有块进行线性嵌入,得到{v01,…,v0NI}。对于一个256x256分辨率的图像,我们有NI=256。 我们把[CLS]的嵌入表示为v0cls,以代表整个图像。在第一个L1层,我们对所有块进行双向关注,即完全关注。 如果图像中有N个区域,我们将上下文的块表示{vL1cls,vL11,…,vL1NI}复制成N+1个副本,其中我们对一个副本应用完全注意,对其他副本在接下来的L2层应用局部注意。
一个区域Vj对应于一组图像块,我们把这些块表示为{pj1,…,pjM}。我们在L1+1到L1+L2转换层中加入自我注意掩码,以实现局部注意。
跨模态建模
如图2所示,我们在图像中定位视觉概念,给出相应的文本描述,同时将文本和视觉概念对齐,其中的对齐是多粒度的。
X-VLM的预训练目标: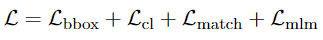
边界框预测(Bounding Box Prediction) 我们让模型预设视觉概念Vj的边界框bj,并给出全神贯注的图像表示和文本表示,其中bj=(cx,cy,w,h)。通过在同一图像中定位不同的视觉概念,我们期望该模型能更好地学习细粒度的视觉-语言排列方式。
对比学习(Contrastive Learning) 和 CLIP 类似,X-VLM 也使用了对比损失。我们从批内否定中预测(视觉概念,文本)对,表示(V,T)。 注意,视觉概念包括物体、区域和图像。随机采样N个图像文本对 (1 个 batch),(V,T) 为正样本,V和同一 batch 内的其他文本 Ti组成N−1个负样本。
匹配(Matching Prediction) 我们确定一对视觉概念和文本是否匹配。对于一个小批次中的每个视觉概念,对一个批次中的硬负面文本进行采样。我们还为每个文本抽取一个硬性负面的视觉概念。我们用跨模式编码器的输出[CLS]嵌入来预测匹配概率p^match。
屏蔽语言建模(Masked Language Modeling) 我们根据视觉概念来预测文本中的任务词。我们以25%的概率随机掩盖输入的标记,替换的标记是10%的随机标记,10%的不变标记,以及80%的[MASK]。我们使用跨模式编码器的输出结果,并附加一个线性层,然后是softmax预测。
实验
预训练数据集
遵循UNITER和其他现有工作,我们使用两个域内数据集COCO和Visual Genome(VG)以及两个域外数据集SBU Cap-tions和Conceptual Cap-tions(CC)构建我们的预训练数据。单一图像的总数量为4.0M,图像-文本对的数量为5.1M。遵循ALBEF,我们还利用了噪音更大的Con-ceptual 12M数据集(CC-12M),将图像总数增加到14M。图像注释来自COCO和VG,其中包含200K图像的250万个对象注释和370万个区域注释。
现有的方法通过训练物体检测器或使用区域注释来利用数据,并假设它们可以描述整个图像。相反,我们将物体标签作为物体的文本描述,并重新表述图像注释,使一幅图像有多个由边界框包围的区域,每个区域与一个文本相关联。由于大多数下游的V+L任务是建立在COCO和VG之上的,我们排除了所有也出现在下游任务的验证和测试集中的图像,以避免信息泄露。 我们还通过URL匹配排除了所有共同出现的Flickr30K图像,因为COCO和VG都来自Flickr,而且有一些重叠的地方。
实现细节
图像编码器是一个12层的ViTbase,有86M个参数,用Touvron等人在ImageNet-1k上预训练的权重进行初始化。 文本编码器和跨模态编码器分别是一个六层的BERTbase,共有124M个参数。 文本编码器使用BERTbase的前六层进行初始化,而跨模式编码器则使用最后六层进行初始化。对于文本输入,我们将最大的标记数设置为25。
X-VLMbase接受256×256分辨率的图像作为输入。图像编码器将一幅图像分割成16×16的重叠部分。 我们对前八层采用完全注意力,对最后四层采用混合注意力。在微调过程中,我们将图像分辨率提高到384×384,并对图像patches的位置嵌入进行相互推断。
我们在32个NVIDIA V100 GPU上用混合精度对模型进行了50次预训练。batch size被设置为3072,我们通过使一批图像中的一半包含边界框注释来对数据进行采样。 用400万张图片进行训练需要三天时间。 我们使用AdamW优化器,权重衰减为0.02。学习率在前1/5次迭代中从1e-5预热到1e-4,然后按照余弦计划衰减到1e-5次。
下游任务
图像-文本检索 有两个子任务:文本检索(TR)和图像检索(IR)。我们在MSCOCO和Flickr30K基准数据集上评估X-VLM。我们对Lcl和Lmatch进行了优化微调。 在推理中,我们首先对所有的图像和文本计算(I,T),然后取前k个候选者并计算pmatch(I,T)进行排名。按照ALBEF,MSCOCO的k被设置为256,Flickr30K的k被设置为128。
对图像-文本检索的评估
表1将X-VLM与SoTA方法在MSCOCO和Flickr30K上进行了比较。在4M的设定下,X-VLM以很大的优势胜过了之前所有基于以目标为中心的特征或整体图像特征的方法,显示了我们多粒度方法的有效性。此外,当用更多的实例(14M)进行训练时,X-VLM也以很大的幅度取得了新的SoTA结果,超过了所有现有的方法,包括用内部1.8B数据集训练的ALIGN。与X-VLM(4M)相比,X-VLM(14M)也获得了相当大的改进,这表明我们的方法在更多的网络数据中是可以扩展的。
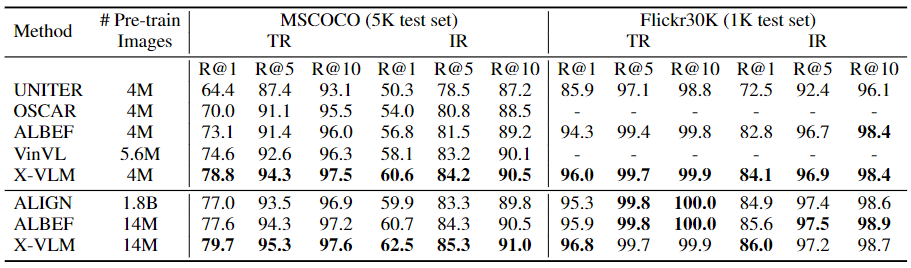
表1:MSCOCO和Flickr30K数据集的图像-文本检索结果。IR:图像检索,TR:文本检索
消融研究
表3提供了对X-VLM(4M)的消融研究结果。我们用R@1作为检索任务的评价指标,用Meta-Sum作为一般指标。 我们报告了两个Meta-Sum分数:一个是所有分数的总和,另一个是用*标记的,不包括有监督的RefCOCO+的结果。首先,我们评估了不同粒度的视觉概念的有效性,即无对象和无区域。结果表明,不使用这两种概念的训练会损害性能,这说明学习多粒度对齐的必要性。 此外,我们可以观察到,与对象相比,无区域使性能下降得更厉害。此外,消融研究表明,边界盒预测是X-VLM的一个重要组成部分,因为没有边界盒损失会导致最低的Meta-Sum。 特别是对于RefCOCO+来说,下降了3.6%(指标的平均值)。 如表3所示,混合注意力机制也带来了性能上的提高。
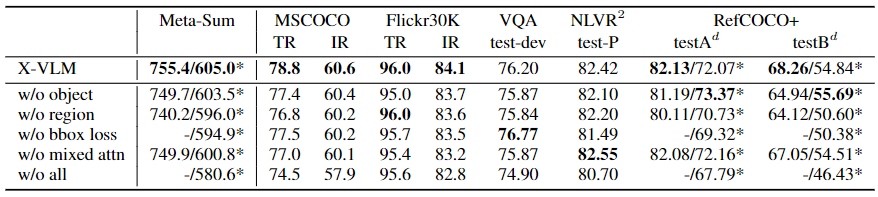
表3:对X-VLM的消融研究:w/o object是指没有对象概念的训练;w/o region是指没有区域概念的训练;w/o bbox loss是指没有边界盒预测;w/o mixed attn是指完全应用局部注意力来获得精细的概念表征;w/o all代表去除上述所有组件。
有了混合注意力,编码图像上下文信息的物体或区域表示就更加准确。混合注意力也是一种高效的实现方式,它可以节省50%的GPU内存。总的来说,尽管X-VLM中的不同组件在各种下游的V+L任务中表现不同,但它们都有助于提高整体性能和/或高效的实现。
我们还报告了 "不包括所有 "的结果。虽然在4M的设置中,只有5.0%的图像有密集的注释,但X-VLM可以利用这些数据,大大改善下游V+L任务的性能(Meta-Sum从580.6到605.2)。如上所述,当用更多的图像-文本对进行训练时,X-VLM(14M)仍然可以比X-VLM(4M)取得相当大的改进。值得注意的是,在14M设置中,只有1.4%的图像有注释。结果表明,我们的X-VLM方法可以扩展到大规模数据。我们还可以看到,细粒度的视觉概念,例如物体,比图像的多样性要少得多。但是,它们仍然是图像的组成部分,对学习视觉语言对齐有重大影响。
结论
现有的视觉语言模型要么利用细粒度的以物体为中心的图像特征,要么利用粗粒度的图像的整体特征。 虽然有效,但这两种方法仍有一些缺点。在本文中,我们将现有的数据集重构为图像/区域/物体-文本对,并提出了X-VLM,一种新的方法来进行多粒度的视觉语言预训练。模型的训练是通过定位图像中的视觉概念来驱动的,并将文本和相关的视觉概念对齐,其中对齐是多粒度的。在许多V+L任务上的实验表明,X-VLM实现了对现有SoTA方法的实质性改进。
推荐阅读:X-VLM