请问,优秀的多模态融合论文有哪些? - 知乎先给结论,我个人推荐ALBEF和BLIP,原因两点:端到端模型,单塔和双塔统一。刚入门小白勉强答一下。以前…![]() https://www.zhihu.com/question/519588362/answer/2380401897为什么Transformer适合做多模态任务? - 知乎Transformer是多模态里重要一环,但不是所有任务的唯一方案或最佳方案。多模态任务目前主要有Align和Fuse…
https://www.zhihu.com/question/519588362/answer/2380401897为什么Transformer适合做多模态任务? - 知乎Transformer是多模态里重要一环,但不是所有任务的唯一方案或最佳方案。多模态任务目前主要有Align和Fuse…![]() https://www.zhihu.com/question/441073210/answer/2237611847多模态论文串讲·下【论文精读·49】_哔哩哔哩_bilibili更多论文:https://github.com/mli/paper-reading, 视频播放量 63271、弹幕量 119、点赞数 1918、投硬币枚数 1273、收藏人数 871、转发人数 211, 视频作者 跟李沐学AI, 作者简介 ,相关视频:Transformer论文逐段精读【论文精读】,多模态论文串讲·上【论文精读·46】,InstructGPT 论文精读【论文精读·48】,GPT,GPT-2,GPT-3 论文精读【论文精读】,如何读论文【论文精读·1】,GAN论文逐段精读【论文精读】,如何做好文献阅读及笔记整理,CLIP 改进工作串讲(上)【论文精读·42】,如何找研究想法 1【论文精读】,第1集 热血重燃!16名顶尖AI程序员助力科技反诈
https://www.zhihu.com/question/441073210/answer/2237611847多模态论文串讲·下【论文精读·49】_哔哩哔哩_bilibili更多论文:https://github.com/mli/paper-reading, 视频播放量 63271、弹幕量 119、点赞数 1918、投硬币枚数 1273、收藏人数 871、转发人数 211, 视频作者 跟李沐学AI, 作者简介 ,相关视频:Transformer论文逐段精读【论文精读】,多模态论文串讲·上【论文精读·46】,InstructGPT 论文精读【论文精读·48】,GPT,GPT-2,GPT-3 论文精读【论文精读】,如何读论文【论文精读·1】,GAN论文逐段精读【论文精读】,如何做好文献阅读及笔记整理,CLIP 改进工作串讲(上)【论文精读·42】,如何找研究想法 1【论文精读】,第1集 热血重燃!16名顶尖AI程序员助力科技反诈 https://www.bilibili.com/video/BV1fA411Z772/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22BLIP - a Hugging Face Space by SalesforceDiscover amazing ML apps made by the community
https://www.bilibili.com/video/BV1fA411Z772/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22BLIP - a Hugging Face Space by SalesforceDiscover amazing ML apps made by the community![]() https://huggingface.co/spaces/Salesforce/BLIPblip中有两个关键词,一个是bootstrapping,一个是unified,第一个bootstrapping是从数据集角度出发的,假如你有一个从网页上爬取的很嘈杂的数据集,先用它训练一个模型,接下来再通过一些方法去得到一些更干净的数据,然后再用这些更干净的数据去train更好的模型。第二点是unified,目前的两个方向,一个是understanding,image-text retrieval,VQA等任务,一个是generation生成式,image captioning这种从图像生成文字的任务。
https://huggingface.co/spaces/Salesforce/BLIPblip中有两个关键词,一个是bootstrapping,一个是unified,第一个bootstrapping是从数据集角度出发的,假如你有一个从网页上爬取的很嘈杂的数据集,先用它训练一个模型,接下来再通过一些方法去得到一些更干净的数据,然后再用这些更干净的数据去train更好的模型。第二点是unified,目前的两个方向,一个是understanding,image-text retrieval,VQA等任务,一个是generation生成式,image captioning这种从图像生成文字的任务。
1.引言
有2个动机,一个从模型出发,一个从数据出发。从模型侧,最近的方法一条路是使用了transformer encoder的一些模型,包括clip,ALBEF,另外一条路使用了encoder,decoder结构,比如说SimVLM,encoder only没法直接用到text generation中,没有解码器,当然也不是完全不行,可以加一些其他模块来实现,对于encoder decoder来说,又很难去做image text retrieval,因此作者提了一个统一的架构。从数据侧,目前表现出色的clip,albef和simVLM,都是在大规模的从网上爬取的noisy的image text对上预训练的,当数据量足够大时会弥补一些noisy数据的影响,也就说加大数据是能够得到提升的,blip说使用这种noisy数据训练不是最优解,去掉noisy数据,是可以让模型更好的利用图像文本对信息,作者提出了captioner和filter模块,captioner就是给定一张图,生成相应文字,这种就得到了大量合成数据,同时再训练一个filter,判断图像和文本是否是一对,不是就从数据集中删除。
2.模型
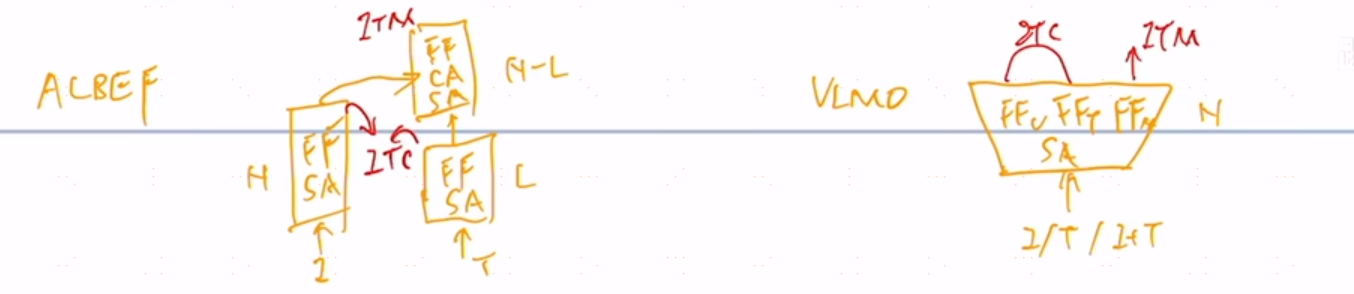
ALBEF将模型分成了三个结构,一个是视觉编码器,一个是文本编码器,一个是多模态编码器,图像侧是一个N层的transformer的encoder,文本侧是一个L层encoder,在得到对应的图像文本特征之后,先做一个(ITC)image text contrasting,这个对比学习的loss把图像和文本特征学好,然后文本特征继续输入self-attention layer中,然后图像特征通过cross-attention layer进来,和文本特征进行融合,经过N-L层的多模态编码器之后,得到多模态特征,去做image text matching,为什么把文本这侧要把一个N层的transformer encoder拆成L层和N-L层,因为作者还想维护这个计算量不变,和clip一样,左边一个12层transformer encoder,右边也是一个12层的transformer decoder,不想增加多模态融合计算量,多模态融合这部分又比较重要,相对来说,文本侧不那么重要,将12层分成两部分。VLMO觉得拆来拆去太麻烦,不够灵活,设计了一个(MOE)mixer of expert,只有一个网络,self-attention都是共享参数层,根据模态不同而改变的地方是feed forward network,有feed forward network,feed forward attacks和feed forward multi model,来区别不同的模态,去训练不同的expert,这样在训练是一个模型,权重都是共享的,在推理时,根据不同的任务去选择这个模型中的某一个部分去推理,VLMO证明self-attention是可以共享参数的,和模态关系不大。
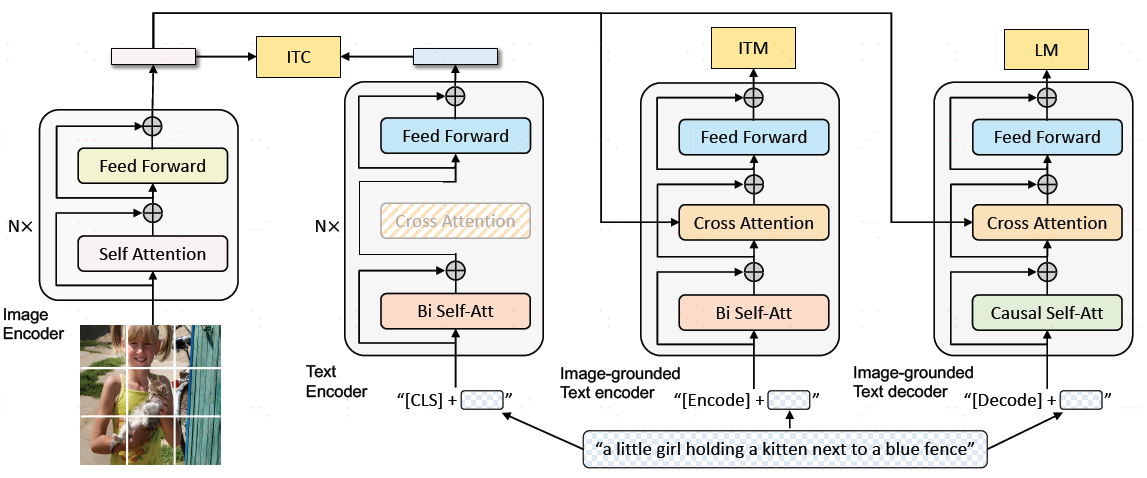
blip包含了4个部分,图像侧是完整的N层vit模型,文本侧有3个模型分别来计算3个不同的目标函数,根据目标函数不同,去选择一个大模型中的不同部分,这三个模型的模块根据颜色不同来共享参数,颜色相同的模块都是共享参数的,也就是说只有一个模型在训练。对于第一个文本模型,也是N层,它的目标是根据输入文本,去做一个understanding这么一个分类任务,得到文本特征之后,就和视觉特征做ITC loss。第二个文本模型,叫Image grounded text encoder,它是一个多模态编码器了,借助图像的信息去完成一些多模态任务,去做ITM loss,图像侧信息通过cross-attention来融合文本特征,这块就是ALBEF,比第一个模块多了cross-attention模块,这里的SA和FFN是一样的。第三个模型是一个decoder,decoder的输入输出行驶和bi SA是有区别的,输入不是完整的句子是mask掉的,训练时如果看到完整的句子,肯定能生成,这样训练就没有难度了,它必须像gpt模型一样训练,把后面的句子都mask,通过前面的信息去推测后面的句子长什么样,所以第一层用的是causal的self-attention,和bi self-attention是不共享参数,当然如果硬要用self-attention也可以,但是性能会下降,除此之外,cross-attention和ffn都是和前面共享参数的。总结一下就是对于图像,有一个VIT,对于文本有三个模型,一个标准的text encoder,一个image grounded text encoder和image grounded text decoder,image grounded text encoder有一个新的cross-attention,decoder有一个新的causal self-attention,剩下的部分都是共享参数的,选择第一个和第二个模型,计算ITC loss,选择第一个和第三个模型,计算ITM Loss,选择第一个和第四个模型,计算LM loss,从目标函数上,blip有三个目标函数。对于三个文本模型来说,他们对应的token不一样,第一个用的是cls token,第二个用的encoder,第三个用的是decoder,但是这些模型都不好训练,每做一次training iteration,图像侧只做一次forward,文本侧做三次forward,分别通过三个模型得到对应特征,然后计算对应的目标函数。当然训练中也会有很多技巧,比如在算ITC时,用到了momentum encoder去做更好的knowledge distillation,在算ITM loss,利用ITC loss计算similarity score去做hard negative mining,每次用最难的负样本去算ITM,从而增加loss的有效性。作者blip这种模型结构叫做Mixture of Encoder and Decoder,MED。
3.数据
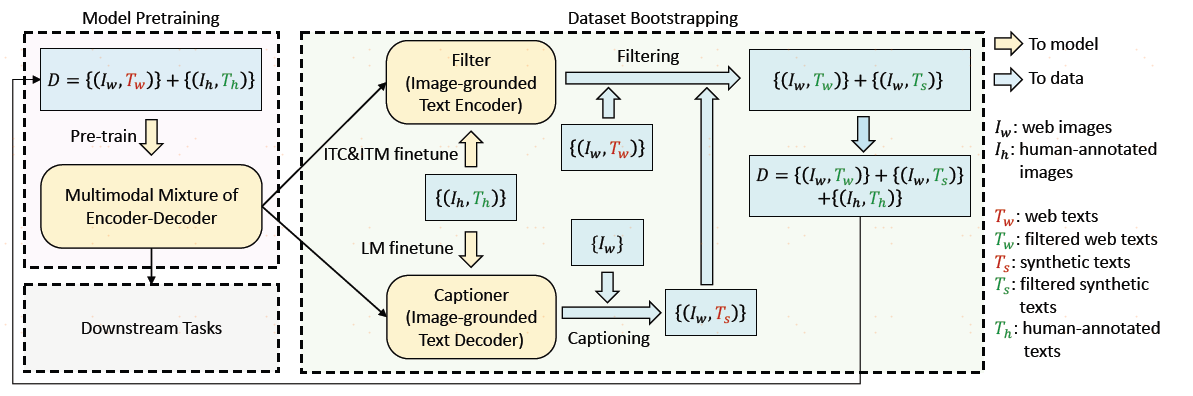
blip的第二个共享,Cap filter model,出发点就是从网上爬取的很多数据,可能有一些手工标注的数据集,像clip的训练就没有用到手工标注数据集,只用了从网上爬下来的400m,对于数据集来说,图文对不匹配,也就是上面红色的Tw不好,绿色是Th,是coco手工标注的,文本匹配的。filter模型是判断图像文本之间相似度,相似高的就匹配,不高的就不匹配,filter模型是如何训练的?把提前训练的blip模型,把图像模型和两个文本模型,分别做ITC和ITM的两个文本模型拿出来,在coco数据集上做很快的微调,微调之后的模型就叫filter,使用image text matching计算分数,通过filter作者将原始爬下来的noisy数据变成了clean的文本对,就是绿色的Tw,到这里filter的任务就完成了。captioner是因为作者在训练出来decoder之后,发现blip的decoder很好,有时候它生成出来的句子要比原始的图像文本对要很多,即使原来的图文对是一个match,但是新生成出来的文本更加匹配,质量更高,因此作者想能不能使用生成的句子去做训练,作者也是在coco数据上把已经训练好的image grounded text decoder微调了一下,得到了captioner,使用captioner给图片生成新的句子,当然Ts的质量可高可低,最终通过captioner和filter来获取数据。最终再拿新的数据去训练blip,发现新blip的效果更好。
laion团队的laion 400m和openai的clip 400m数据集对齐,又推出了更大的laion 2/5 billion数据,这些数据中的噪声相当大,于是从laion 5b中用blip模型和2个clip中欧filtering和captioning,得到laion 6b数据集。