本文首发于微信公众号 CVHub,不得以任何形式转载到其它平台,仅供学习交流,违者必究!
Title: Class-Aware Adversarial Transformers for Medical Image Segmentation
Paper: https://arxiv.org/pdf/2201.10737v5.pdf | Accepted by NeurlIPS 2022
Author: Chenyu You et al. (耶鲁大学 & 德州大学 & 牛津大学)
本文主要还是围绕 Transformer 在医学图像分割领域的应用,方法都是比较常规的,对于需要发论文找 Idea 的同学建议可以多看看这些文章,比较适合入门级发表,下面笔者简单为大家剖析下,大家只需要 get 到人家那个点就行了,精度提升其实这些都没啥意义,懂的自然懂。u1s1,这年头 Transformer 真的是 “杀疯了”,你现在做个啥任务不套个 变形金刚 你都不好意思丢给 reviewer 了。有趣的是,现在引用 CNNs 的人反而都演变为 Rethinking or Revisiting了? 哈哈哈~~~
这玩意挺简单的,就是一个编解码架构结合对抗训练,对于不知道如何找点发论文的同学是一篇不错的借鉴思路,例如,换个GAN架构?或者堆个其他Transformer模块?再不行做成实时语义分割或者扩展到3D和视频序列?有精力的再加点噪声(Diffusion)?没卡(钱)的换个弱监督或者域自适应?数学工程能力好点的集成点图卷积或者传统算法进去?

实在不行我换到显著性检测或者其他方向上做做行不行?

什么?话说到这份上了,你还写不出一篇顶会顶刊出来?

好了,废话不多说,直接上图把,毕竟有图有真相:
今天没什么时间写了,下面重点解读下方法部分。
Methods
Overall
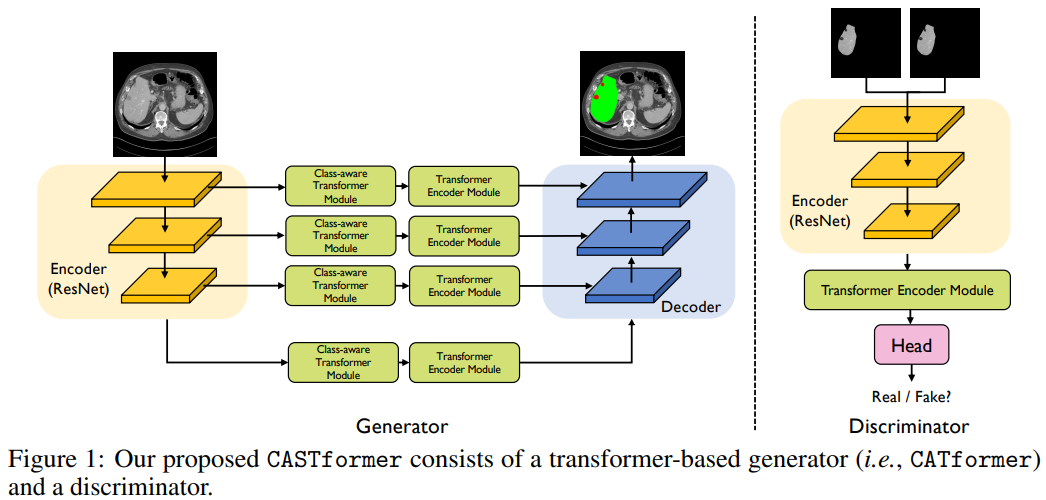
如上图所示,网络是基于生成对抗方式训练的,自然而然会包含一个生成器Generator和一个判别器Discriminator。其中,Generator 是一个基于 Transformer 网络的标准 Encoder-Decoder 架构,a.w.a CASTformer,共包含四个组件(从左往右):
- 编码器(特征提取器)模块
- 类感知Transformer模块
- Transformer编码器模块
- 解码器模块
其中,生成器部分共包含四个阶段和四个并行子网,所有阶段共享一个相似的架构,其中包含补丁嵌入层、类感知层以及多个 Transformer 编码器层。
笔者建议:设计网络结构的时候建议按照这种模块化的思路设计,一方面整体架构清晰易懂,另一方面消融实验也比较好做。
Encoder
编码器部分作者采用的方式是 CNN+Transformer 的组合来生成多尺度特征图,这样做有两个优势:
- 使用
CNNs主干有助于Transformer在下游视觉任务中表现更好; Transformer提供高分辨率特征图以及并行的中低分辨率特征图,可以获得更好的表征。
如此一来,便可以利用 Transformer 构建特征金字塔,并将多尺度特征图用于下游的医学分割任务。通过构建多层级的特征图,模型能够更好的构建不同分辨率下的空间局部上下文信息。
Hierarchical Feature Representation
按经验看,人脑视觉机理高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图。抽象层面越高,存在的可能猜测就越少。
在深度学习中,网络的学习机理亦是如此,浅层特征注重空间细节,高层特征注重语义信息。因此,本文,或者说是绝大多数深度学习网络,几乎都是考虑这种分层式的特征表示架构,从而获取不同层级所需的上下文。
Class-aware Transfomer
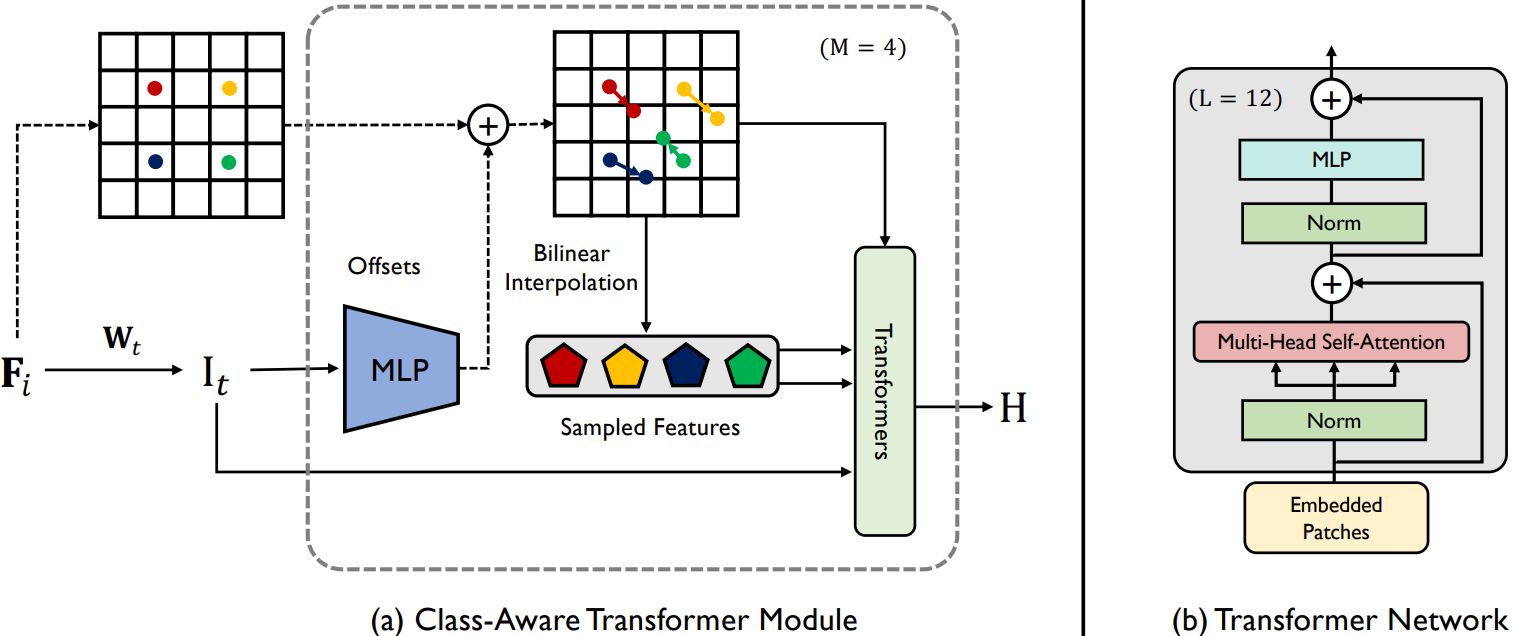
(a)
Class-aware Transfomer模块和(b)Transfomer网络。
Class-aware Transfomer 旨在自适应地关注对象的有用区域(例如潜在的解剖特征和结构信息)。
Class-aware Transfomer 模块属于一种迭代优化过程,其原理如下:
- 获取
token序列 I M , 1 I_{M,1} IM,1,其中 ( n × n ) (n × n) (n×n) 和 M M M 是每个特征图上的样本数和总迭代次数 数; - 对于给定的给定特征图
F_{1},通过将它们与最后一步的估计偏移向量相加来迭代更新其采样位置; - 采用双线性插值获取最终的采样特征;
最后,再同中间特征一同作为 Transfomer 模块的输入,输出结构化特征序列。
Transformer Encoder Module
Transformer 编码器模块(TEM)旨在通过从输入图像块嵌入的完整序列中聚合全局上下文信息来对远程上下文信息进行建模。在具体的实现中,Transformer 编码器模块遵循原始 ViT 中的架构,由多头自注意力(MSA)和多层感知机(MLP)块组成。
Decoder Module
解码器旨在根据四个不同分辨率的输出特征图生成分割掩码。在实现中,作者并没有设计需要高计算需求的解码器模块,而是参考 Segformer 合并了一个轻量级的纯 MLP 解码器,这种简单的设计能够更有效地产生强大的表示。
解码器设计思路如下:
- 多尺度特征的通道维度通过
MLP层进行统一; - 所有特征图统一上采样到
1/4并将其全部连接在一起; - 利用
MLP层融合级联特征,然后根据融合特征预测多类分割掩码。
Discriminator Network
判别器部分比较简单,作者直接采用 ImageNet-1k 数据集上预训练好的 R50+ViT-B/16 混合权重。一般来说,使用预训练权重对于数据量有限的任务时非常重要滴。紧接着,简单地应用两层多层感知器来预测类感知图像的类别。
判别器试图在真实样本和假样本之间进行分类,Generator 和 Discrimitor 通过试图达到 minimax 博弈的平衡点来相互竞争。使用这种结构使鉴别器能够对远距离上下文依赖性进行建模,从而更好地评估医学图像的保真度,这也从本质上赋予了模型对解剖视觉模态(分类特征)的更全面的理解。
Loss Function
损失函数部分主要包含两部分,生成器部分是一个标准的医学图像分割网络,同样的也应用了 CE + Dice 损失的组合方式,这也是绝大多数医学图像分割常标配的方式。对抗训练则应用了 WGAN-GP loss。
BCE loss 大家都比较熟悉,主要问题是会受到样本不均衡的影响;而 Dice loss 比较适用于样本极度不均的情况,但是在一般的情况下,使用 Dice 损失会对反向传播造成不利的影响,反而容易使训练变得不稳定。因此,通常都会结合两者一起使用。
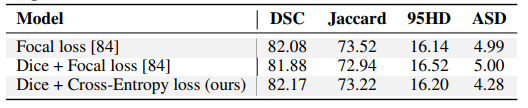
关于损失函数这块有不清楚的同学,也可以查阅公众号历史文章《一文看尽深度学习中的各种损失函数》。
Experiments
Dataset
- Synapse
- LiTS
- MP-MRI
Metrics
- Dice coefficient (Dice)
- Jaccard Index (Jaccard)
- 95% Hausdorff Distance (95HD)
- Average Symmetric Surface Distance (ASD)
Implementation Details
- Optimizer: AdamW
- LR: 5 e − 4 5e^{-4} 5e−4
- BatchSize: 6
- Epochs: 300
- Resolution: 224×224
- PatchSize: 14
- Hardware: 1 * NVIDIA GeForce RTX 3090 GPT with 24GB of memory
Results
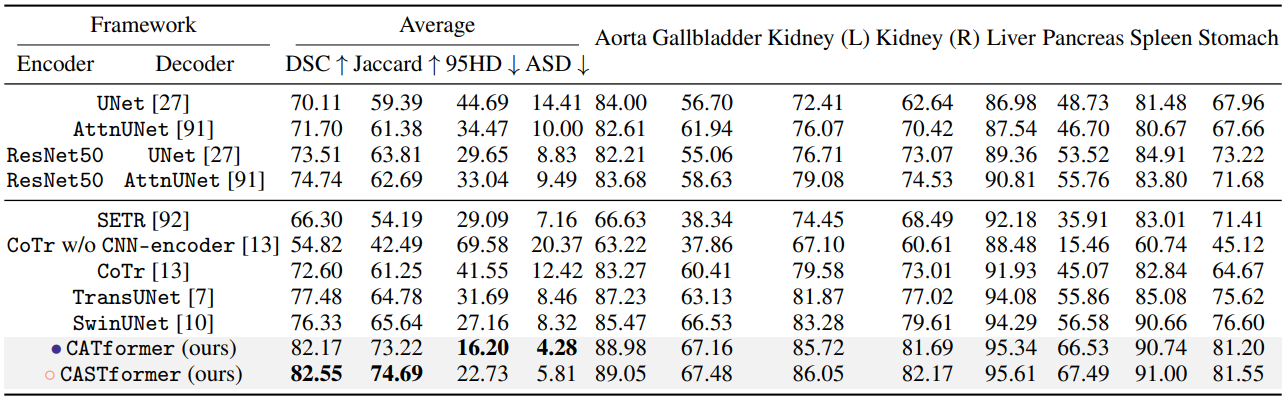
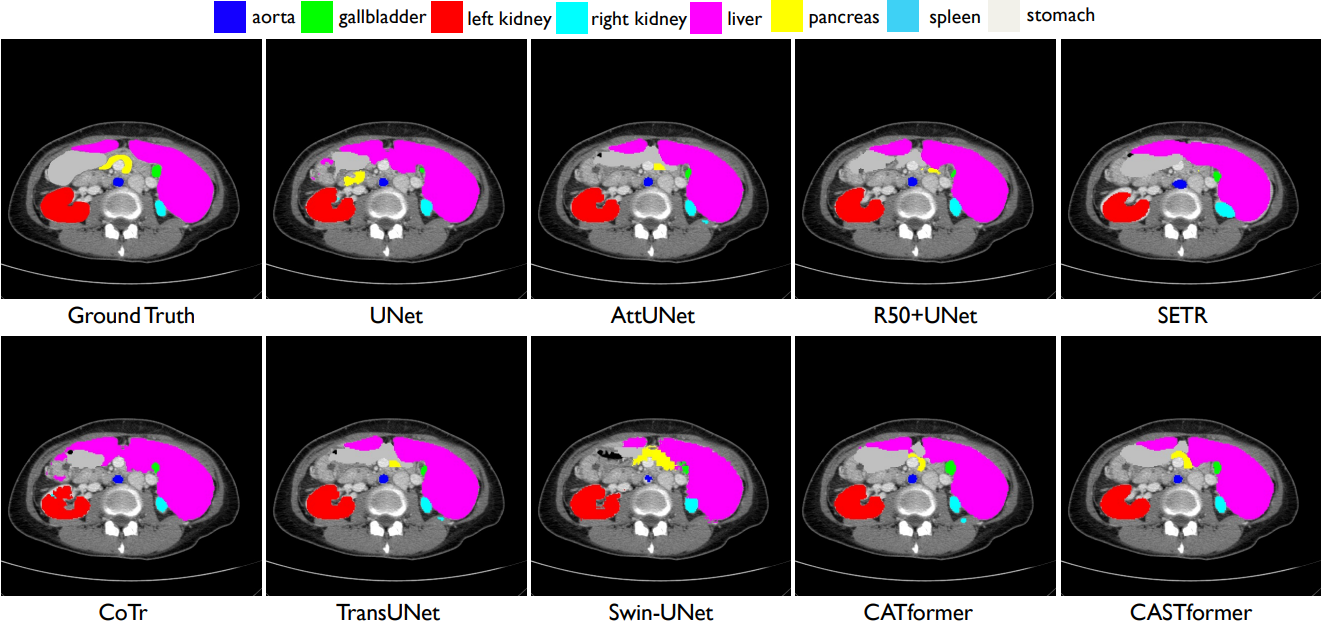
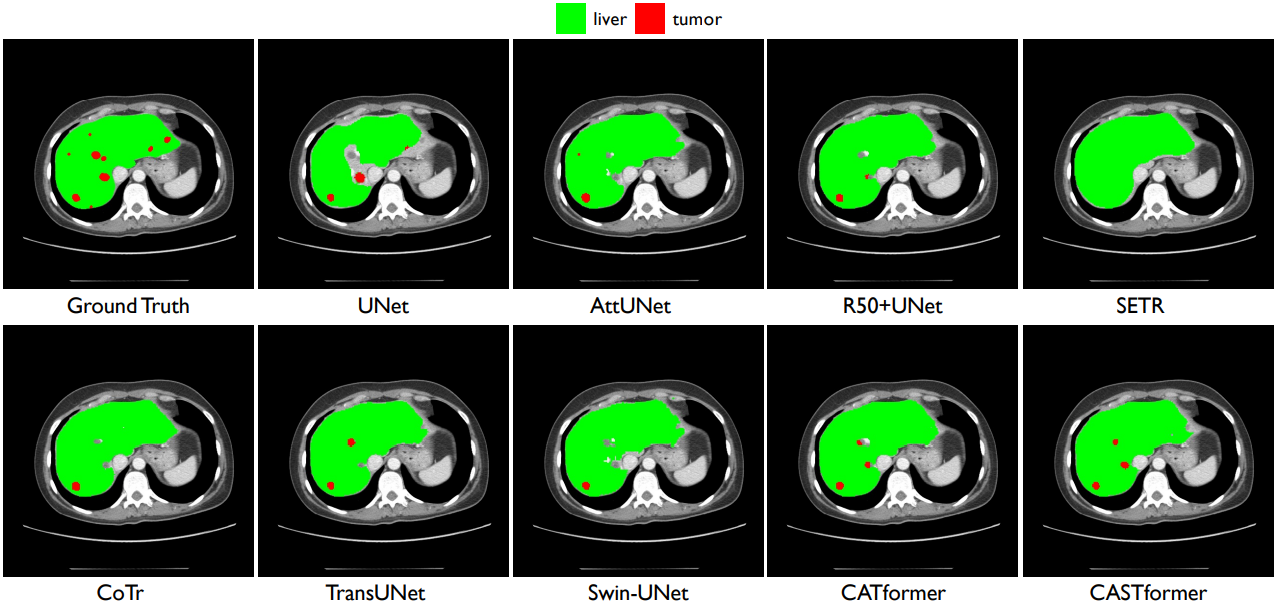

可以看出,CASTformer 通过精细的解剖特征和不同器官的边界信息实现了优异的分割性能。
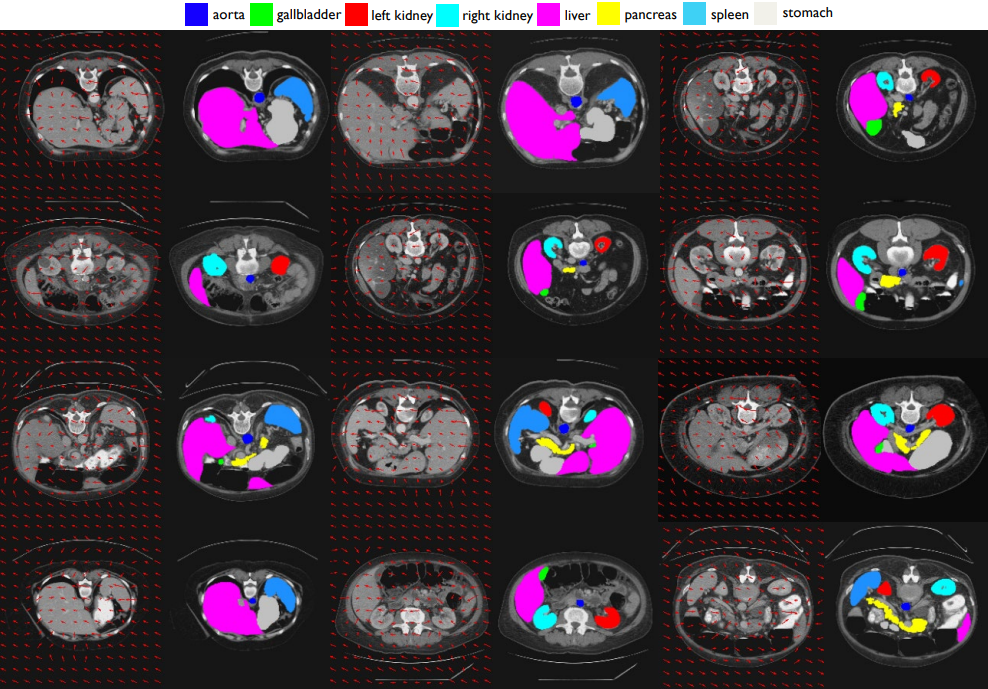
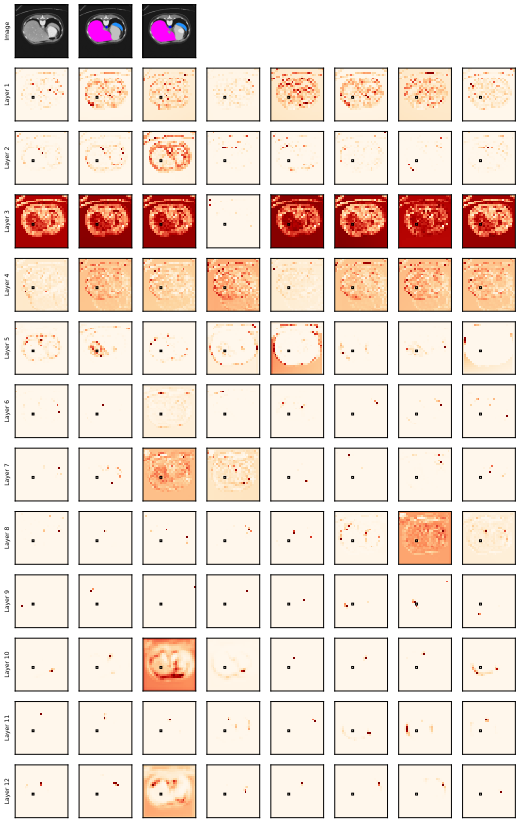
上图黑框表示的是 Query Patch。第一行为输入图像、GT和预测标签。
Conclusion
在这项工作中,作者结合 CNN+Transformer 设计了一种简单而有效的混合网络结构 CASTformer 并用于 2D 的医学图像分割。CASTformer 通过整合多尺度金字塔结构以捕获丰富的全局空间信息和局部多尺度上下文信息。此外,进一步的应用生成对抗训练的策略用于提高分割性能,使基于 Transformer 的判别器能够捕获低级解剖特征和高级语义。最后,通过在Synapse、LiTS、MP-MRI三个主流的医学数据集上的广泛实验验证了本文方法的有效性。整体而言,笔者认为,CASTformer 为医学领域的迁移学习提供了一个崭新的视角,并初步为理解神经网络行为提供了新的见解。
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号:cv_huber,一起探讨更多有趣的话题!