Transformer 中的 Attention
Introduction
这篇文章为论文的读书笔记
论文原文:Transformer:Attention is all you need
这篇论文是谷歌 17 年在机器翻译任务中提出的一种新的序列转换模型" Transformer “。传统的序列转换模型是用 RNN 和 CNN 做的,为了使这些模型表现的更好,通常还加入了 Attention,也就是注意力机制。本文提出的 Transformer 模型,完全摒弃了 RNN 和 CNN 的结构,而是只依赖于 Attention 机制,并且这种模型反而能够表现的更好,并且减少了训练时间,那么 Transformer 的工作原理是什么,从下面讲起。
Encoder-Decoder
Transformer 的整个模型是这样子的,很复杂,我们一步一步的分解来看。
首先将这个模型看成是一个黑箱操作,在机器翻译中,就是输入一种语言,输出另一种语言
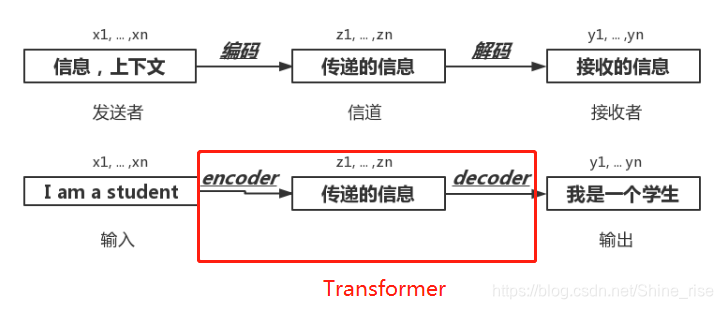
类似于通信系统中,发送者将上下文信息,采用能在空气中传播的信号传给接收者,这个过程就是广义上的编码,然后接收者根据事先约定好的信息,将这些信号还原成发送者的信息。
机器翻译中,将一种语言,这里是英语,也就是 x1…xn 的输入序列,通过 Encoder 编码器转换成中间序列 z1…zn ,然后再通过 Decoder 解码器产生输出序列 y1…yn ,翻译成汉语。这就是 Encoder-Decoder 框架
六个 Encoder 和六个 Decoder 组合起来就形成了 Transformer 的结构
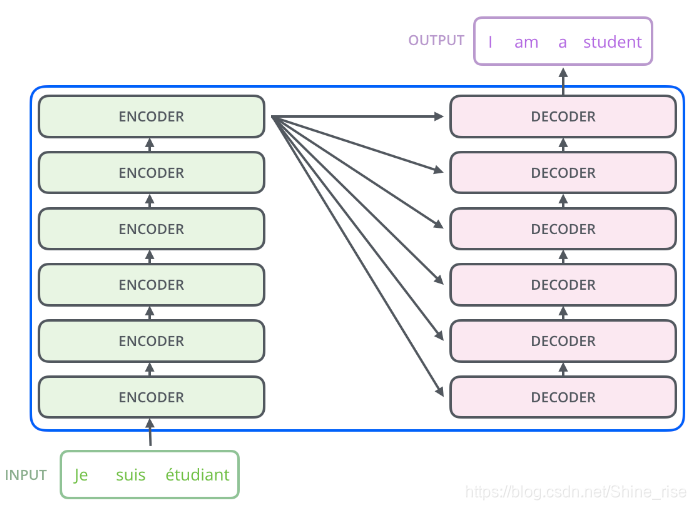
所有的编码器和解码器在结构上都是相同的,但它们没有共享参数。每个编码器都可以分解成两个子层
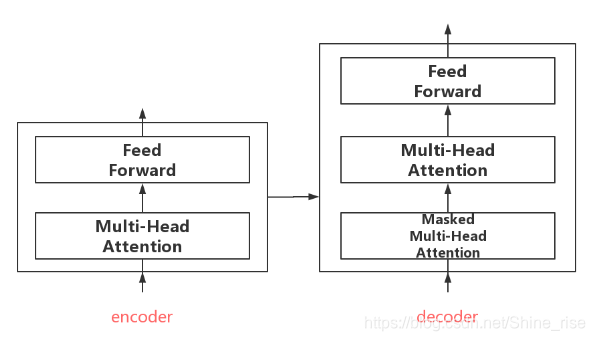
从编码器中输入的句子首先会经过一个自注意力层( Self-Attention ),这层帮助编码器在对每个单词编码时关注输入句子的其他单词,然后再经过一层前馈神经网络层。解码器中也有类似编码器中自注意力层和前馈神经网络层,除此之外,还插入了第三个子层,对编码器的输出执行 Encoder-Decoder Attention。Self-Attention 到底是什么,接下来进行介绍。
Attention
从宏观看
Attention 正如它的翻译“注意力”,类似于人的注意力机制,我们在第一次见一个陌生人时,第一关注的肯定是他的脸,然后才是身体的其他部位。这个图形象化的表明了人在看到一份报纸时,更多的会把注意力文本的标题以及文章的首句等位置。
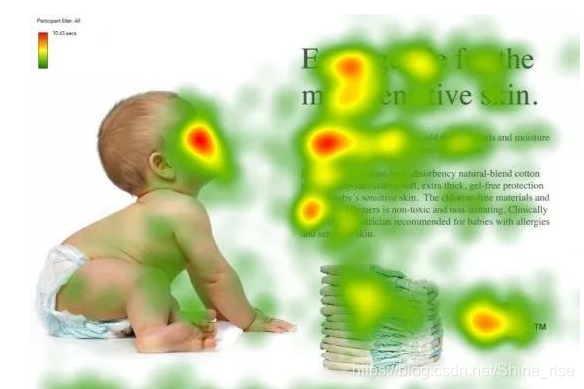
深度学习中的 Attention 机制,和人的选择性视觉注意力机制是类似的。
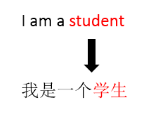
在机器翻译中,如果不使用注意力机制,“ I am a student ”,这句话翻译成汉语时,每个英文单词对翻译过来的“学生”这个中文单词的影响因子,也可以简单的理解为对它的贡献(权重),是一样的。很明显这里不太合理,事实上应该是“ student ”这个单词,在翻译时,对“学生”的影响最大。这样就引入了 Attention 机制,也就是为每个单词加入了一个 Weight (权重)机制,体现英文单词对于翻译当前中文单词的不同的影响程度。这是通俗的注意力的意思。
本论文中使用到的 Self-Attention 模型,不是在由英语翻译成中文中加入的权重,而是在同一个英语句子内单词间产生的联系。例如,在翻译 The animal didn’t cross the street because it was too tired 时,“ it ”在这个句子是指什么呢?它指的是 street 还是这个 animal 呢?这对于人类来说是一个简单的问题,但是对于算法则不是。模型在处理单词“it”的时候,自注意力机制会允许“ it ”与“ anima l”建立联系。随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。也就是在 Self-Attention 中,输出序列也就是输入序列

当我们在编码器5中编码 “ it ” 这个单词时,注意力机制的部分会去关注“ The Animal ”,将它的表示的一部分编入 “ it ” 的编码中。

从微观看
微观上看,如何计算自注意力:
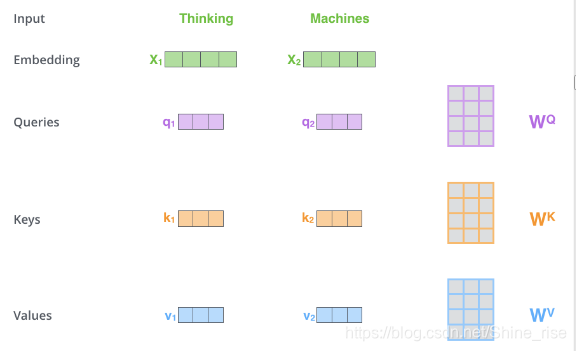
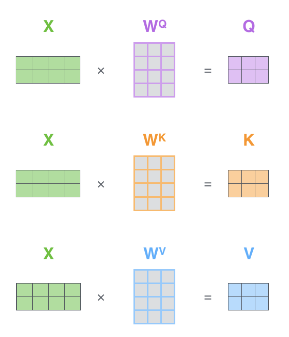
第一步,得到查询向量(query)、键向量(key)、值向量(value)。
输入序列中的单词通过词嵌入算法得到的词向量 X (维数为 512),分别乘以三个权重矩阵
,
,
得到 query , key , value 三个向量。其中 query, key , value 的维数相同,都为 64。
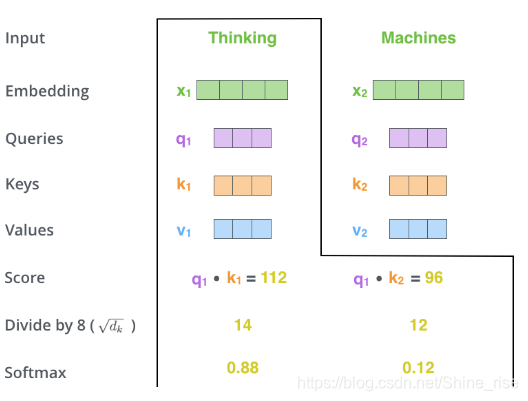
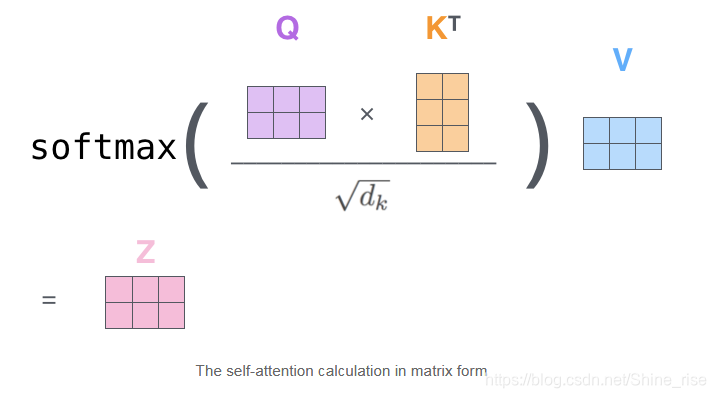
第二步, query 向量, key 向量的点积,除以 key 向量的维数的开方,经过 softmax 得到权值。
第三步,对所有单词的表示(即 value 向量)进行加权求和,得到输出Z,Z也就是一个注意力头
注:1.在实际计算中,将每个单词的 query 向量, key 向量, value 向量,拼到一起变成查询矩阵 Q 、键矩阵 K 、值矩阵 V 。
2.除以
和 softmax 的操作都是为了使梯度更稳定,防止梯度消失。论文中将这种自注意力机制定义为“ Scaled Dot-Product Attention ”,这里的 Scaled 就是指缩放因子
。
如何理解这三个向量和他们的计算?
正如 query, key , value 这三个单词的原本的意思,Attention 机制就是将所有单词的表示(V)加权求和,权重就是该词的表示(K)与被编码词表示(Q)的点积并通过 Softmax 得到的。例如在翻译“ I am a student ”这个句子时,翻译到" I "的时候,我们就需要查询 整个英语句子对“I” 这个单词哪个影响最大,于是将“ I ”这个词的查询向量,分别乘以整个句子的每一个单词的键向量,得到的权重,再乘以每一个单词的值,这就将该单词,与所有单词对它的影响联系了起来。
Multi Head Attention
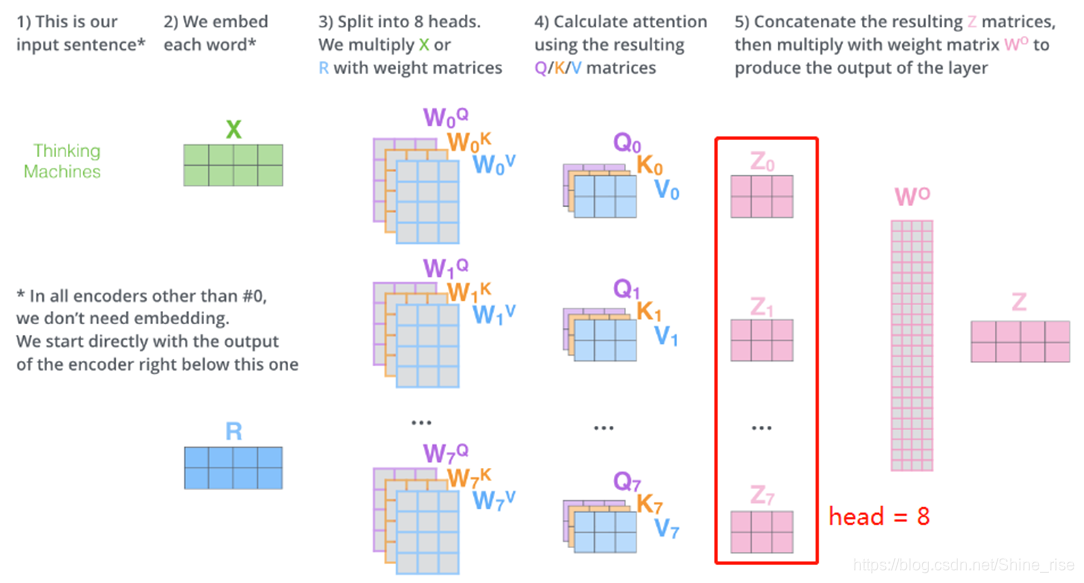
上文中输出了一个 Z ,也就是一个注意力头,而该论文中使用的 Multi Head Attention ,是一种多头的注意力机制,该机制扩展了模型专注于不同位置的能力。
首先,给出了注意力层的多个“表示子空间”,“多头”注意机制,论文中是 head = 8,我们有多个查询/键/值权重矩阵集( Transformer 使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中,得到 8 个不同的查询向量/键向量/值向量,经过加权求和得到的八个 zi (这里用 z0 , z1 , z2 ,…, z7 表示),拼到一起,乘以一个额外的权重矩阵,得到最终的 Z 矩阵。
Transformer
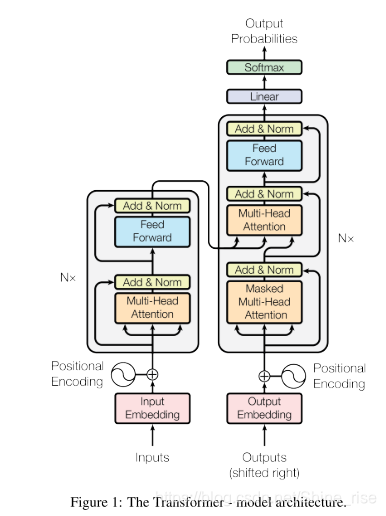
该结构图就是开头我们提到的 Transformer 的整体结构
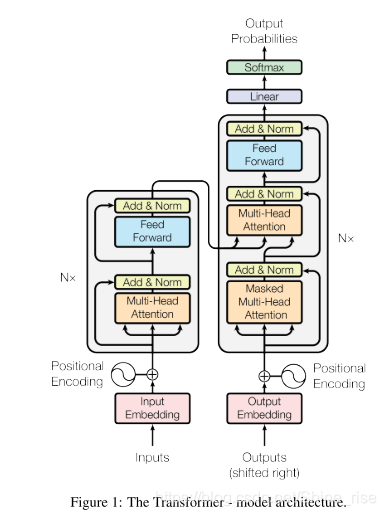
首先,在 Encoder 的 Self-Attention 中,Q 、K 、V 都来自同一个地方(相等),他们是上一层 Encoder 的输出。对于第一层 Encoder ,它们就是 Word Embedding 和 Positional Encoding 相加得到的输入。
在 Decoder 的 Self-Attention 中, Q 、K 、V 都来自于同一个地方(相等),它们是上一层 Decoder 的输出。对于第一层 Decoder ,它们就是 Word Embedding 和 Positional Encoding 相加得到的输入。但是对于 Decoder ,我们不希望它能获得下一个 Time Step (即将来的信息),因此我们需要进行 Sequence Masking 。
在 Encoder-Decoder Attention 中, Q 来自于 Decoder 的上一层的输出, K 和 V 来自于 Encoder 的输出, K 和 V 是一样的。
