在Swin-Transformer一文中,有这样两个公式,分别为:
1. Transformer中提出的Multi-head Self-Attention模块(MSA)
2. Swin-Transformer中提出的Window Multi-head Self-Attention模块(W-MSA)
两者计算量即计算复杂度分别为:
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C Ω(MSA) = 4hwC^2 + 2(hw)^2C Ω(MSA)=4hwC2+2(hw)2C
Ω ( W − M S A ) = 4 h w C 2 + 2 M 2 h w C Ω(W-MSA) = 4hwC^2 + 2M^2hwC Ω(W−MSA)=4hwC2+2M2hwC
一、MSA模块计算量
Transformer中提出的多头自注意力模块运算公式为
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d k ) V Attention(Q,K,V)=Softmax(\frac {QK^T} {\sqrt{d_k} \quad})V Attention(Q,K,V)=Softmax(dkQKT)V
运算过程以及计算量如下图:
(注:图中黑色字体为矩阵维度,橙色字体为计算量)
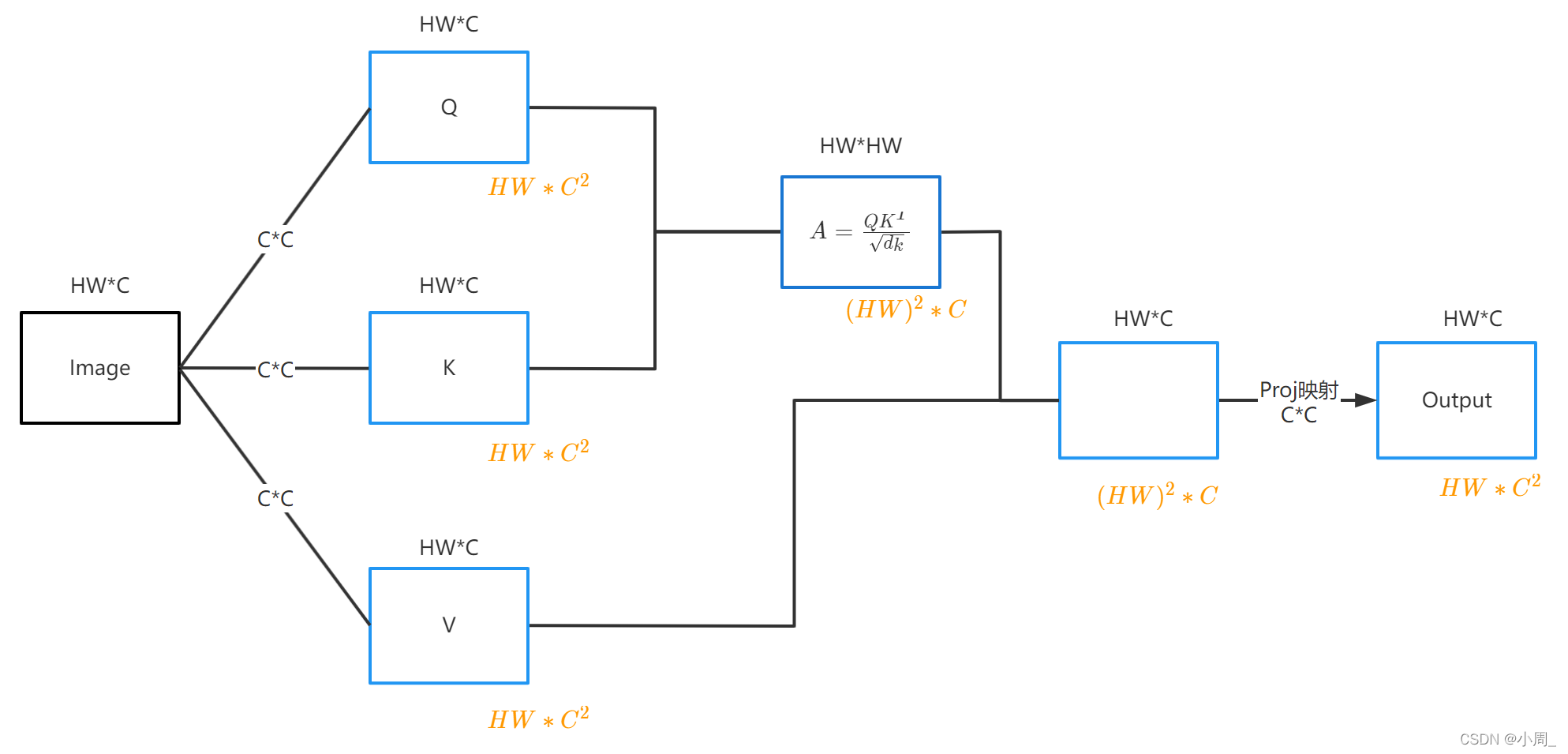 1. 首先,一张维度为H * W * C的图片,分别通过乘上一个CC的变换矩阵,分别变成QKV矩阵,维度仍为H * W * C。这样三个变换用到的计算量都为:HW * C^2,加起来为: 3 H W ∗ C 2 3HW*C^2 3HW∗C2
1. 首先,一张维度为H * W * C的图片,分别通过乘上一个CC的变换矩阵,分别变成QKV矩阵,维度仍为H * W * C。这样三个变换用到的计算量都为:HW * C^2,加起来为: 3 H W ∗ C 2 3HW*C^2 3HW∗C2
2. 然后做QK的转置,(HW * C) * (C * HW),得到的矩阵维度为HW * HW,计算量为: ( H W ) 2 ∗ C (HW)^2*C (HW)2∗C
3. 忽略根号dk和softmax的计算量,2中得到的 A矩阵 × V矩阵 ,结果的维度为HW * C,计算量为: ( H W ) 2 ∗ C (HW)^2*C (HW)2∗C
4. 因为是多头自注意力,所以在做完矩阵乘法后,需要矩阵拼接融合,做一个Proj映射,得到输出矩阵,维度和输入一样为HW * C,计算量为: H W ∗ C 2 HW*C^2 HW∗C2
5. 最后计算量加起来,为: Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C Ω(MSA) = 4hwC^2 + 2(hw)^2C Ω(MSA)=4hwC2+2(hw)2C
二、W-MSA模块计算量
W-MSA与MSA总体的计算过程是一致的,区别在于:W-MSA的长宽不再是H和W,而是 窗 口 : M ∗ M 窗口: M*M 窗口:M∗M并且有 H M ∗ W M 个 窗 口 需 要 计 算 \frac{H}{M}*\frac{W}{M}个窗口需要计算 MH∗MW个窗口需要计算
所以它的计算量为:
( h M ∗ w M ) ∗ ( 4 M 2 C 2 + 2 M 4 C ) = 4 h w C 2 + 2 M 2 h w C (\frac{h}{M}*\frac{w}{M})*(4M^2C^2+2M^4C)=4hwC^2+2M^2hwC (Mh∗Mw)∗(4M2C2+2M4C)=4hwC2+2M2hwC
分析
从他们公式可以看出区别主要在于两个公式的后半部分
带一点数进去就可以看出W-MSA在计算量上比MSA少很多,比如以原文中的一些参数设定为例:HW都为56,C为96,M为7
前者MSA为: 2 ∗ ( 56 ∗ 56 ) 2 ∗ 96 = 1888223232 2*(56*56)^2*96=1888223232 2∗(56∗56)2∗96=1888223232
后者为W-MSA为: 2 ∗ 7 2 ∗ 56 ∗ 56 ∗ 96 = 29503488 2*7^2*56*56*96=29503488 2∗72∗56∗56∗96=29503488
二者相差了64倍。
论文名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
原论文地址: https://arxiv.org/abs/2103.14030