2023版最新The Annotated Transformer翻译
原文地址:http://nlp.seas.harvard.edu/annotated-transformer/#hardware-and-schedule
0.Prelims
import os
from os.path import exists
import torch
import torch.nn as nn
from torch.nn.functional import log_softmax, pad
import math
import copy
import time
from torch.optim.lr_scheduler import LambdaLR
import pandas as pd
import altair as alt
from torchtext.data.functional import to_map_style_dataset
from torch.utils.data import DataLoader
from torchtext.vocab import build_vocab_from_iterator
import torchtext.datasets as datasets
import spacy
import GPUtil
import warnings
from torch.utils.data.distributed import DistributedSampler
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
# Set to False to skip notebook execution (e.g. for debugging)
warnings.filterwarnings("ignore")
RUN_EXAMPLES = True
一些公用辅助函数
def is_interactive_notebook():
return __name__ == "__main__"
def show_example(fn, args=[]):
if __name__ == "__main__" and RUN_EXAMPLES:
return fn(*args)
def execute_example(fn, args=[]):
if __name__ == "__main__" and RUN_EXAMPLES:
fn(*args)
class DummyOptimizer(torch.optim.Optimizer):
def __init__(self):
self.param_groups = [{"lr": 0}]
None
def step(self):
None
def zero_grad(self, set_to_none=False):
None
class DummyScheduler:
def step(self):
None
1.Background
Extended Neural GPU、ByteNet和ConvS2S的出现是为了减少序列计算量,他们都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。在这些模型中,关联来自两个任意输入或输出位置的信号所需的操作数量随着位置之间的距离而增长,对于ConvS2S呈线性增长,对于ByteNet则呈对数增长。 这使得学习远距离位置之间的依赖关系变得更加困难。在Transformer中,这被减少到恒定数量的操作,尽管由于平均注意力加权位置而降低了效果,我们用多头注意力来抵消这种影响。
自注意力(Self-attention),有时称为内部注意力,是一种将单个序列的不同位置相关联以计算序列表示的注意力机制。 自注意力已成功用于各种任务,包括阅读理解、抽象摘要、文本蕴涵和学习与任务无关的句子表示。 端到端记忆网络基于循环注意力机制而不是序列对齐循环,并且已被证明在简单语言问答和语言建模任务上表现良好。
然而,据我们所知,Transformer 是第一个完全依赖自注意力来计算其输入和输出表示,而不是使用序列对齐 RNN 或卷积的模型。
2.Model Architecture
大部分神经序列转换模型都有一个编码器-解码器结构。编码器把一个输入序列 ( x 1 , . . . , x n ) (x_1, ..., x_n) (x1,...,xn)映射到一个连续的表示$ z=(z_1, …, z_n) 中。解码器对 z 中的每个元素,生成输出序列 中。解码器对z中的每个元素,生成输出序列 中。解码器对z中的每个元素,生成输出序列(y_1, …, y_m)$,一个时间步生成一个元素。在每一步中,模型都是自回归的,在生成下一个结果时,会将先前生成的结构加入输入序列来一起预测。(自回归模型的特点)
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)
Transformer的编码器和解码器都使用self-attention堆叠和point-wise、全连接层。如图1的左、右两边所示。
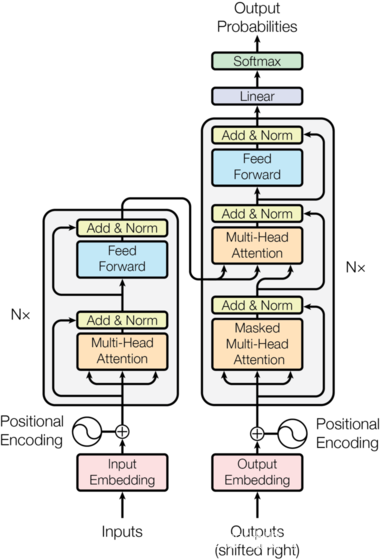
2.1 Encoder and Decoder
编码器由N = 6 个完全相同的层组成。
(1)Encoder
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
编码器的每个子层(Self Attention 层和 FFNN)都再接一个残差连接(cite)。然后是层标准化(layer-normalization) (cite)。
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
每个子层的输出是 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x + Sublayer(x)) LayerNorm(x+Sublayer(x)),其中 $Sublayer(x) $是子层本身实现的函数。 我们将dropout (cite) 应用于每个子层的输出,然后再将其添加到子层输入中并进行归一化。
为了便于进行残差连接,模型中的所有子层以及embedding层产生的输出的维度都为 d m o d e l = 512 d_{model}=512 dmodel=512
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
每一层都有两个子层。 第一层是一个multi-head self-attention机制(的层),第二层是一个简单的、全连接的前馈网络。
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
(2)Decoder
解码器也是由N = 6 个完全相同的层组成。
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
除了每个decoder层中的两个子层之外,decoder还有第三个子层,该层对encoder的输出执行multi-head attention。(即encoder-decoder-attention层,q向量来自上一层的输入,k和v向量是encoder最后层的输出向量memory)与encoder类似,我们在每个子层再采用残差连接,然后进行层标准化。
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
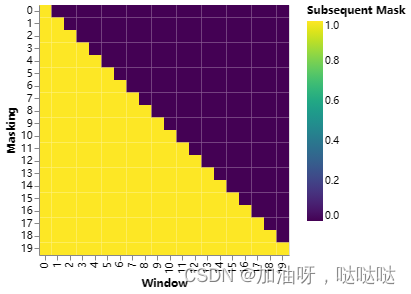
我们还修改decoder层中的self-attention子层,以防止在当前位置关注到后面的位置。这种掩码结合将输出embedding偏移一个位置,确保对位置 i i i的预测只依赖位置 i i i之前的已知输出。
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(torch.uint8)
return subsequent_mask == 0
下面的attention mask显示了每个tgt单词(行)允许查看(列)的位置。在训练时将当前单词的未来信息屏蔽掉,阻止此单词关注到后面的单词。
def example_mask():
LS_data = pd.concat(
[
pd.DataFrame(
{
"Subsequent Mask": subsequent_mask(20)[0][x, y].flatten(),
"Window": y,
"Masking": x,
}
)
for y in range(20)
for x in range(20)
]
)
return (
alt.Chart(LS_data)
.mark_rect()
.properties(height=250, width=250)
.encode(
alt.X("Window:O"),
alt.Y("Masking:O"),
alt.Color("Subsequent Mask:Q", scale=alt.Scale(scheme="viridis")),
)
.interactive()
)
show_example(example_mask)
(3)Attention
Attention功能可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。输出为value的加权和,其中每个value的权重通过query与相应key的兼容函数来计算。
我们将particular attention称之为“缩放的点积Attention”(Scaled Dot-Product Attention")。其输入为query、key(维度是 d k d_k dk)以及values(维度是 d v d_v dv)。我们计算query和所有key的点积,然后对每个除以 d k \sqrt{d_k} dk , 最后用softmax函数获得value的权重。
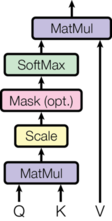
在实践中,我们同时计算一组query的attention函数,并将它们组合成一个矩阵$Q 。 k e y 和 v a l u e 也一起组成矩阵 。key和value也一起组成矩阵 。key和value也一起组成矩阵K 和 和 和V$。 我们计算的输出矩阵为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
两个最常用的attention函数是加法attention(cite)和点积(乘法)attention。除了缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1 ,点积Attention跟我们的平时的算法一样。加法attention使用具有单个隐层的前馈网络计算兼容函数。虽然理论上点积attention和加法attention复杂度相似,但在实践中,点积attention可以使用高度优化的矩阵乘法来实现,因此点积attention计算更快、更节省空间。
当 d k d_k dk的值比较小的时候,这两个机制的性能相近。当 d k d_k dk比较大时,加法attention比不带缩放的点积attention性能好 (cite)。我们怀疑,对于很大的 d k d_k dk值, 点积大幅度增长,将softmax函数推向具有极小梯度的区域。(为了说明为什么点积变大,假设 q q q和 k k k是独立的随机变量,均值为0,方差为1。那么它们的点积 q ⋅ k = ∑ i = 1 d k q i k i q \cdot k = \sum_{i=1}^{d_k} q_ik_i q⋅k=∑i=1dkqiki, 均值为0方差为 d k d_k dk)。为了抵消这种影响,我们将点积缩小 1 d k \frac{1}{\sqrt{d_k}} dk1 倍。
为什么Attention中除以** d \sqrt{d} d**** 这么重要?**
Attention的计算是在内积之后进行softmax,主要涉及的运算是 e q ⋅ k e^{q \cdot k} eq⋅k,我们可以大致认为内积之后、softmax之前的数值在 − 3 d -3\sqrt{d} −3d到 3 d 3\sqrt{d} 3d这个范围内,由于d通常都至少是64,所以 e 3 d e^{3\sqrt{d}} e3d比较大而 e − 3 d e^{-3\sqrt{d}} e−3d比较小,因此经过softmax之后,Attention的分布非常接近一个one hot分布了,这带来严重的梯度消失问题,导致训练效果差。(例如y=softmax(x)在|x|较大时进入了饱和区,x继续变化y值也几乎不变,即饱和区梯度消失)
相应地,解决方法就有两个:
1.像NTK参数化那样,在内积之后除以 d \sqrt{d} d,使q⋅k的方差变为1,对应 e 3 e^3 e3, e − 3 e^{−3} e−3都不至于过大过小,这样softmax之后也不至于变成one hot而梯度消失了,这也是常规的Transformer如BERT里边的Self Attention的做法
2.另外就是不除以 d \sqrt{d} d,但是初始化q,k的全连接层的时候,其初始化方差要多除以一个d,这同样能使得使q⋅k的初始方差变为1,T5采用了这样的做法。

Multi-head attention允许模型共同关注来自不同位置的不同表示子空间的信息,如果只有一个attention head,它的平均值会削弱这个信息。
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O \\ where ~ head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)
其中映射由权重矩阵完成:$W^Q_i \in \mathbb{R}^{d_{
{model}} \times d_k}
$, W i K ∈ R d model × d k W^K_i \in \mathbb{R}^{d_{\text{model}} \times d_k} WiK∈Rdmodel×dk, W i V ∈ R d model × d v W^V_i \in \mathbb{R}^{d_{\text{model}} \times d_v} WiV∈Rdmodel×dv和 W i O ∈ R h d v × d model W^O_i \in \mathbb{R}^{hd_v \times d_{\text{model}} } WiO∈Rhdv×dmodel。
在这项工作中,我们采用h=8个平行attention层或者叫head。对于这些head中的每一个,我们使用 $d_k=d_v=d_{\text{model}}/h=64 $,由于每个head的维度减小,总计算成本与具有全部维度的单个head attention相似。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)
(4)模型中Attention的应用
multi-head attention在Transformer中有三种不同的使用方式:
- 在encoder-decoder attention层中,queries来自前面的decoder层,而keys和values来自encoder的输出。这使得decoder中的每个位置都能关注到输入序列中的所有位置。这是模仿序列到序列模型中典型的编码器—解码器的attention机制,例如 (cite).
- encoder包含self-attention层。在self-attention层中,所有key,value和query来自同一个地方,即encoder中前一层的输出。在这种情况下,encoder中的每个位置都可以关注到encoder上一层的所有位置。
- 类似地,decoder中的self-attention层允许decoder中的每个位置都关注decoder层中当前位置之前的所有位置(包括当前位置)。 为了保持解码器的自回归特性,需要防止解码器中的信息向左流动。我们在缩放点积attention的内部,通过屏蔽softmax输入中所有的非法连接值(设置为 − ∞ -\infty −∞)实现了这一点。
2.2 基于位置的前馈网络
除了attention子层之外,我们的编码器和解码器中的每个层都包含一个全连接的前馈网络,该前馈网络分别且相同地应用于每个位置。网络包括两个线性变换,并在两个线性变换中间有一个ReLU激活函数。
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0, xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
Position就是序列中每个token,
Position-wise就是把MLP对每个token作用一次,且作用的是同一个MLP。
尽管两层都是线性变换,但它们在层与层之间使用不同的参数。另一种描述方式是两个内核大小为1的卷积。 输入和输出的维度都是 $d_{\text{model}}=512 内层维度是 内层维度是 内层维度是d_{ff}=2048$.(也就是第一层输入512维,输出2048维;第二层输入2048维,输出512维)
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))
2.3 Embeddings and Softmax
与其他序列转换模型类似,我们使用学习到的embedding将输入token和输出token转换为 d model d_{\text{model}} dmodel维的向量。我们还使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个token的概率。 在我们的模型中,两个嵌入层之间和pre-softmax线性变换共享相同的权重矩阵,类似于(cite)。在embedding层中,我们将这些权重乘以$\sqrt{d_{\text{model}}} $
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
2.4 位置编码
由于我们的模型不包含循环和卷积,为了让模型利用序列的顺序,我们必须加入一些序列中token的相对或者绝对位置的信息。为此,我们将“位置编码”添加到编码器和解码器堆栈底部的输入embeddinng中。位置编码和embedding的维度相同,也是 d model d_{\text{model}} dmodel, 所以这两个向量可以相加。有多种位置编码可以选择,例如通过学习得到的位置编码和固定的位置编码 (cite)。
在这项工作中,我们使用不同频率的正弦和余弦函数:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 p o s pos pos是位置, i i i 是维度。也就是说,位置编码的每个维度对应于一个正弦曲线。 这些波长形成一个从 2 π 2\pi 2π 到 10000 ⋅ 2 π 10000 \cdot 2\pi 10000⋅2π的集合级数。我们选择这个函数是因为我们假设它会让模型很容易学习对相对位置的关注,因为对任意确定的偏移k , P E p o s + k PE_{pos+k} PEpos+k可以表示为 P E p o s PE_{pos} PEpos的线性函数。
此外,我们会将编码器和解码器堆栈中的embedding和位置编码的和再加一个dropout。对于基本模型,我们使用的dropout比例是 P d r o p = 0.1 P_{drop}=0.1 Pdrop=0.1
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
位置编码将根据位置添加正弦波。波的频率和偏移对于每个维度都是不同的。
def example_positional():
pe = PositionalEncoding(20, 0)
y = pe.forward(torch.zeros(1, 100, 20))
data = pd.concat(
[
pd.DataFrame(
{
"embedding": y[0, :, dim],
"dimension": dim,
"position": list(range(100)),
}
)
for dim in [4, 5, 6, 7]
]
)
return (
alt.Chart(data)
.mark_line()
.properties(width=800)
.encode(x="position", y="embedding", color="dimension:N")
.interactive()
)
show_example(example_positional)
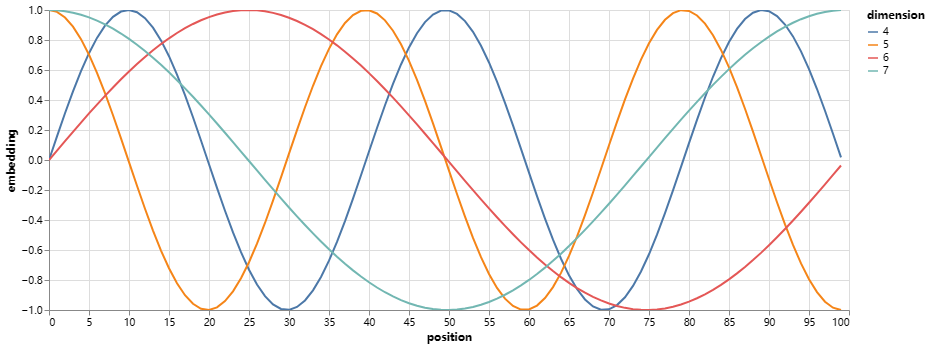
我们还尝试使用学习到的位置嵌入(cite)来代替,发现这两个版本产生了几乎相同的结果。 我们选择正弦版本是因为它可以让模型推断出比训练期间遇到的序列长度更长的序列长度。
2.5 完整模型
在这里,我们定义了一个从超参数到完整模型的函数。
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
2.6 Inference
在这里,我们用生成模型的预测。 我们尝试使用我们的transformer 来记住输入。 正如您将看到的那样,由于模型尚未训练,输出是随机生成的。 在下一个教程中,我们将构建训练函数并尝试训练我们的模型来记住从 1 到 10 的数字。
def inference_test():
test_model = make_model(11, 11, 2)
test_model.eval()
src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])
src_mask = torch.ones(1, 1, 10)
memory = test_model.encode(src, src_mask)
ys = torch.zeros(1, 1).type_as(src)
for i in range(9):
out = test_model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = test_model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
print("Example Untrained Model Prediction:", ys)
def run_tests():
for _ in range(10):
inference_test()
show_example(run_tests)
Example Untrained Model Prediction: tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
Example Untrained Model Prediction: tensor([[0, 3, 4, 4, 4, 4, 4, 4, 4, 4]])
Example Untrained Model Prediction: tensor([[ 0, 10, 10, 10, 3, 2, 5, 7, 9, 6]])
Example Untrained Model Prediction: tensor([[ 0, 4, 3, 6, 10, 10, 2, 6, 2, 2]])
Example Untrained Model Prediction: tensor([[ 0, 9, 0, 1, 5, 10, 1, 5, 10, 6]])
Example Untrained Model Prediction: tensor([[ 0, 1, 5, 1, 10, 1, 10, 10, 10, 10]])
Example Untrained Model Prediction: tensor([[ 0, 1, 10, 9, 9, 9, 9, 9, 1, 5]])
Example Untrained Model Prediction: tensor([[ 0, 3, 1, 5, 10, 10, 10, 10, 10, 10]])
Example Untrained Model Prediction: tensor([[ 0, 3, 5, 10, 5, 10, 4, 2, 4, 2]])
Example Untrained Model Prediction: tensor([[0, 5, 6, 2, 5, 6, 2, 6, 2, 2]])
3. Training
本节描述了我们模型的训练机制。
我们在这快速地介绍一些工具,这些工具用于训练一个标准的encoder-decoder模型。首先,我们定义一个批处理对象,其中包含用于训练的 src 和目标句子,以及构建掩码。
3.1 Batches and Masking
class Batch:
"""Object for holding a batch of data with mask during training."""
def __init__(self, src, tgt=None, pad=2): # 2 = <blank>
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if tgt is not None:
self.tgt = tgt[:, :-1]
self.tgt_y = tgt[:, 1:]
self.tgt_mask = self.make_std_mask(self.tgt, pad)
self.ntokens = (self.tgt_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
)
return tgt_mask
接下来我们创建一个通用的训练和评估函数来跟踪损失。我们传入一个通用的损失函数,也用它来进行参数更新。
3.2 Training Loop
class TrainState:
"""Track number of steps, examples, and tokens processed"""
step: int = 0 # Steps in the current epoch
accum_step: int = 0 # Number of gradient accumulation steps
samples: int = 0 # total # of examples used
tokens: int = 0 # total # of tokens processed
def run_epoch(
data_iter,
model,
loss_compute,
optimizer,
scheduler,
mode="train",
accum_iter=1,
train_state=TrainState(),
):
"""Train a single epoch"""
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
n_accum = 0
for i, batch in enumerate(data_iter):
out = model.forward(
batch.src, batch.tgt, batch.src_mask, batch.tgt_mask
)
loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens)
# loss_node = loss_node / accum_iter
if mode == "train" or mode == "train+log":
loss_node.backward()
train_state.step += 1
train_state.samples += batch.src.shape[0]
train_state.tokens += batch.ntokens
if i % accum_iter == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
scheduler.step()
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 40 == 1 and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]
elapsed = time.time() - start
print(
(
"Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (i, n_accum, loss / batch.ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0
del loss
del loss_node
return total_loss / total_tokens, train_state
3.3 Training Data and Batching
我们在包含约450万个句子对的标准WMT 2014英语-德语数据集上进行了训练。这些句子使用字节对编码进行编码,源语句和目标语句共享大约37000个token的词汇表。对于英语-法语翻译,我们使用了明显更大的WMT 2014英语-法语数据集,该数据集由 3600 万个句子组成,并将token拆分为32000个word-piece词表。
每个训练批次包含一组句子对,句子对按相近序列长度来分批处理。每个训练批次的句子对包含大约25000个源语言的tokens和25000个目标语言的tokens。
3.4 Hardware and Schedule
我们在一台配备8个 NVIDIA P100 GPU 的机器上训练我们的模型。使用论文中描述的超参数的base models,每个训练step大约需要0.4秒。我们对base models进行了总共10万steps或12小时的训练。而对于big models,每个step训练时间为1.0秒,big models训练了30万steps(3.5 天)。
3.5 Optimizer
我们使用Adam优化器,其中 β 1 = 0.9 \beta_1=0.9 β1=0.9, β 2 = 0.98 \beta_2=0.98 β2=0.98,并且 ϵ = 1 0 − 9 ϵ=10^{-9} ϵ=10−9。我们根据以下公式在训练过程中改变学习率:
l r a t e = d m o d e l − 0.5 ⋅ m i n ( s t e p _ n u m − 0.5 , s t e m _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) lrate = d^{-0.5}_{model}\cdot min(step\_num^{-0.5}, stem\_num \cdot warmup\_steps^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,stem_num⋅warmup_steps−1.5)
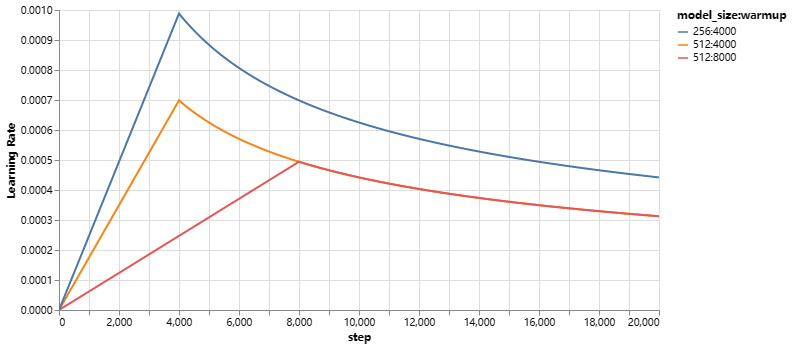
这对应于在第一次 w a r m u p _ s t e p s warmup\_steps warmup_steps步中线性地增加学习速率,并且随后将其与步数的平方根成比例地减小。我们使用 w a r m u p _ s t e p s = 4000 warmup\_steps=4000 warmup_steps=4000。
注意:这部分非常重要。需要使用此模型设置进行训练。
该模型针对不同模型大小和优化超参数的曲线示例。
def rate(step, model_size, factor, warmup):
"""
we have to default the step to 1 for LambdaLR function
to avoid zero raising to negative power.
"""
if step == 0:
step = 1
return factor * (
model_size ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5))
)
def example_learning_schedule():
opts = [
[512, 1, 4000], # example 1
[512, 1, 8000], # example 2
[256, 1, 4000], # example 3
]
dummy_model = torch.nn.Linear(1, 1)
learning_rates = []
# we have 3 examples in opts list.
for idx, example in enumerate(opts):
# run 20000 epoch for each example
optimizer = torch.optim.Adam(
dummy_model.parameters(), lr=1, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer, lr_lambda=lambda step: rate(step, *example)
)
tmp = []
# take 20K dummy training steps, save the learning rate at each step
for step in range(20000):
tmp.append(optimizer.param_groups[0]["lr"])
optimizer.step()
lr_scheduler.step()
learning_rates.append(tmp)
learning_rates = torch.tensor(learning_rates)
# Enable altair to handle more than 5000 rows
alt.data_transformers.disable_max_rows()
opts_data = pd.concat(
[
pd.DataFrame(
{
"Learning Rate": learning_rates[warmup_idx, :],
"model_size:warmup": ["512:4000", "512:8000", "256:4000"][
warmup_idx
],
"step": range(20000),
}
)
for warmup_idx in [0, 1, 2]
]
)
return (
alt.Chart(opts_data)
.mark_line()
.properties(width=600)
.encode(x="step", y="Learning Rate", color="model_size:warmup:N")
.interactive()
)
example_learning_schedule()
3.6 Regularization
Label Smoothing
在训练过程中,我们使用的label平滑的值为 ϵ l s = 0.1 \epsilon_{ls}=0.1 ϵls=0.1 (cite)。这让模型不易理解,因为模型学得更加不确定,但提高了准确性和BLEU得分。
我们使用KL div损失实现标签平滑。我们没有使用one-hot独热分布,而是创建了一个分布,we create a distribution that has confidence of the correct word and the rest of the smoothing mass distributed throughout the vocabulary。该分布具有对正确单词的“置信度”和分布在整个词汇表中的“平滑”质量的其余部分。
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.clone().detach())
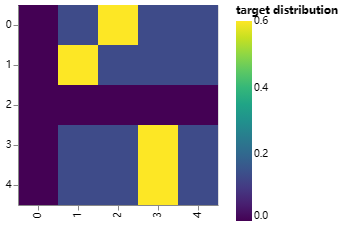
Here we can see an example of how the mass is distributed to the words based on confidence. 在这里,我们可以看到一个示例,说明质量如何根据置信度分配给单词。
# Example of label smoothing.
def example_label_smoothing():
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor(
[
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
]
)
crit(x=predict.log(), target=torch.LongTensor([2, 1, 0, 3, 3]))
LS_data = pd.concat(
[
pd.DataFrame(
{
"target distribution": crit.true_dist[x, y].flatten(),
"columns": y,
"rows": x,
}
)
for y in range(5)
for x in range(5)
]
)
return (
alt.Chart(LS_data)
.mark_rect(color="Blue", opacity=1)
.properties(height=200, width=200)
.encode(
alt.X("columns:O", title=None),
alt.Y("rows:O", title=None),
alt.Color(
"target distribution:Q", scale=alt.Scale(scheme="viridis")
),
)
.interactive()
)
show_example(example_label_smoothing)
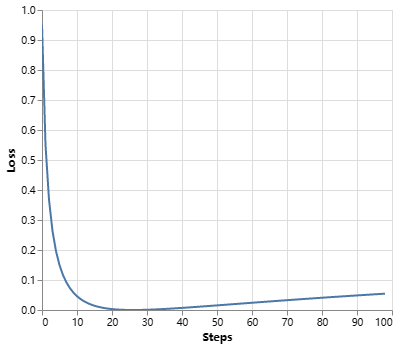
Label smoothing actually starts to penalize the model if it gets very confident about a given choice. 如果模型对给定的选择非常有信心,标签平滑实际上会开始惩罚模型。
def loss(x, crit):
d = x + 3 * 1
predict = torch.FloatTensor([[0, x / d, 1 / d, 1 / d, 1 / d]])
return crit(predict.log(), torch.LongTensor([1])).data
def penalization_visualization():
crit = LabelSmoothing(5, 0, 0.1)
loss_data = pd.DataFrame(
{
"Loss": [loss(x, crit) for x in range(1, 100)],
"Steps": list(range(99)),
}
).astype("float")
return (
alt.Chart(loss_data)
.mark_line()
.properties(width=350)
.encode(
x="Steps",
y="Loss",
)
.interactive()
)
show_example(penalization_visualization)
4.A First Example
我们可以从尝试一个简单的copy任务开始。给定来自小词汇表的一组随机输入符号symbols,目标是生成这些相同的符号。
4.1 Synthetic Data
def data_gen(V, batch_size, nbatches):
"Generate random data for a src-tgt copy task."
for i in range(nbatches):
data = torch.randint(1, V, size=(batch_size, 10))
data[:, 0] = 1
src = data.requires_grad_(False).clone().detach()
tgt = data.requires_grad_(False).clone().detach()
yield Batch(src, tgt, 0)
4.2 Loss Computation
class SimpleLossCompute:
"A simple loss compute and train function."
def __init__(self, generator, criterion):
self.generator = generator
self.criterion = criterion
def __call__(self, x, y, norm):
x = self.generator(x)
sloss = (
self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)
)
/ norm
)
return sloss.data * norm, sloss
4.3 Greedy Decoding
为简单起见,此代码使用贪婪解码预测翻译。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
out = model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ys
# Train the simple copy task.
def example_simple_model():
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
)
batch_size = 80
for epoch in range(20):
model.train()
run_epoch(
data_gen(V, batch_size, 20),
model,
SimpleLossCompute(model.generator, criterion),
optimizer,
lr_scheduler,
mode="train",
)
model.eval()
run_epoch(
data_gen(V, batch_size, 5),
model,
SimpleLossCompute(model.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)[0]
model.eval()
src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len)
print(greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0))
# execute_example(example_simple_model)
5.A Real World Example
现在我们考虑一个使用IWSLT德语-英语翻译任务的真实示例。这个任务比论文中考虑的WMT任务小得多,但这个任务也能说明整个(翻译)系统。我们还展示了如何使用多GPU处理,使任务能真正快速地训练。
5.1 Data Loading
我们将使用torchtext和spacy加载数据集来进行tokenization。
# Load spacy tokenizer models, download them if they haven't been
# downloaded already
def load_tokenizers():
try:
spacy_de = spacy.load("de_core_news_sm")
except IOError:
os.system("python -m spacy download de_core_news_sm")
spacy_de = spacy.load("de_core_news_sm")
try:
spacy_en = spacy.load("en_core_web_sm")
except IOError:
os.system("python -m spacy download en_core_web_sm")
spacy_en = spacy.load("en_core_web_sm")
return spacy_de, spacy_en
def tokenize(text, tokenizer):
return [tok.text for tok in tokenizer.tokenizer(text)]
def yield_tokens(data_iter, tokenizer, index):
for from_to_tuple in data_iter:
yield tokenizer(from_to_tuple[index])
def build_vocabulary(spacy_de, spacy_en):
def tokenize_de(text):
return tokenize(text, spacy_de)
def tokenize_en(text):
return tokenize(text, spacy_en)
print("Building German Vocabulary ...")
train, val, test = datasets.Multi30k(language_pair=("de", "en"))
vocab_src = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_de, index=0),
min_freq=2,
specials=["<s>", "</s>", "<blank>", "<unk>"],
)
print("Building English Vocabulary ...")
train, val, test = datasets.Multi30k(language_pair=("de", "en"))
vocab_tgt = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_en, index=1),
min_freq=2,
specials=["<s>", "</s>", "<blank>", "<unk>"],
)
vocab_src.set_default_index(vocab_src["<unk>"])
vocab_tgt.set_default_index(vocab_tgt["<unk>"])
return vocab_src, vocab_tgt
def load_vocab(spacy_de, spacy_en):
if not exists("vocab.pt"):
vocab_src, vocab_tgt = build_vocabulary(spacy_de, spacy_en)
torch.save((vocab_src, vocab_tgt), "vocab.pt")
else:
vocab_src, vocab_tgt = torch.load("vocab.pt")
print("Finished.\nVocabulary sizes:")
print(len(vocab_src))
print(len(vocab_tgt))
return vocab_src, vocab_tgt
if is_interactive_notebook():
# global variables used later in the script
spacy_de, spacy_en = show_example(load_tokenizers)
vocab_src, vocab_tgt = show_example(load_vocab, args=[spacy_de, spacy_en])
Finished.
Vocabulary sizes:
59981
36745
批处理对训练速度非常重要。我们希望有非常均匀的批次,绝对最小的填充。为此,我们必须对默认的torchtext批处理进行一些修改。此代码修补了torchtext的默认批处理,以确保我们通过搜索足够的句子来找到稳定的批处理。
5.2 Iterators
def collate_batch(
batch,
src_pipeline,
tgt_pipeline,
src_vocab,
tgt_vocab,
device,
max_padding=128,
pad_id=2,
):
bs_id = torch.tensor([0], device=device) # <s> token id
eos_id = torch.tensor([1], device=device) # </s> token id
src_list, tgt_list = [], []
for (_src, _tgt) in batch:
processed_src = torch.cat(
[
bs_id,
torch.tensor(
src_vocab(src_pipeline(_src)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
processed_tgt = torch.cat(
[
bs_id,
torch.tensor(
tgt_vocab(tgt_pipeline(_tgt)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
src_list.append(
# warning - overwrites values for negative values of padding - len
pad(
processed_src,
(
0,
max_padding - len(processed_src),
),
value=pad_id,
)
)
tgt_list.append(
pad(
processed_tgt,
(0, max_padding - len(processed_tgt)),
value=pad_id,
)
)
src = torch.stack(src_list)
tgt = torch.stack(tgt_list)
return (src, tgt)
def create_dataloaders(
device,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=12000,
max_padding=128,
is_distributed=True,
):
# def create_dataloaders(batch_size=12000):
def tokenize_de(text):
return tokenize(text, spacy_de)
def tokenize_en(text):
return tokenize(text, spacy_en)
def collate_fn(batch):
return collate_batch(
batch,
tokenize_de,
tokenize_en,
vocab_src,
vocab_tgt,
device,
max_padding=max_padding,
pad_id=vocab_src.get_stoi()["<blank>"],
)
train_iter, valid_iter, test_iter = datasets.Multi30k(
language_pair=("de", "en")
)
train_iter_map = to_map_style_dataset(
train_iter
) # DistributedSampler needs a dataset len()
train_sampler = (
DistributedSampler(train_iter_map) if is_distributed else None
)
valid_iter_map = to_map_style_dataset(valid_iter)
valid_sampler = (
DistributedSampler(valid_iter_map) if is_distributed else None
)
train_dataloader = DataLoader(
train_iter_map,
batch_size=batch_size,
shuffle=(train_sampler is None),
sampler=train_sampler,
collate_fn=collate_fn,
)
valid_dataloader = DataLoader(
valid_iter_map,
batch_size=batch_size,
shuffle=(valid_sampler is None),
sampler=valid_sampler,
collate_fn=collate_fn,
)
return train_dataloader, valid_dataloader
5.3 Training the System
def train_worker(
gpu,
ngpus_per_node,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
config,
is_distributed=False,
):
print(f"Train worker process using GPU: {gpu} for training", flush=True)
torch.cuda.set_device(gpu)
pad_idx = vocab_tgt["<blank>"]
d_model = 512
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
model.cuda(gpu)
module = model
is_main_process = True
if is_distributed:
dist.init_process_group(
"nccl", init_method="env://", rank=gpu, world_size=ngpus_per_node
)
model = DDP(model, device_ids=[gpu])
module = model.module
is_main_process = gpu == 0
criterion = LabelSmoothing(
size=len(vocab_tgt), padding_idx=pad_idx, smoothing=0.1
)
criterion.cuda(gpu)
train_dataloader, valid_dataloader = create_dataloaders(
gpu,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=config["batch_size"] // ngpus_per_node,
max_padding=config["max_padding"],
is_distributed=is_distributed,
)
optimizer = torch.optim.Adam(
model.parameters(), lr=config["base_lr"], betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, d_model, factor=1, warmup=config["warmup"]
),
)
train_state = TrainState()
for epoch in range(config["num_epochs"]):
if is_distributed:
train_dataloader.sampler.set_epoch(epoch)
valid_dataloader.sampler.set_epoch(epoch)
model.train()
print(f"[GPU{gpu}] Epoch {epoch} Training ====", flush=True)
_, train_state = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in train_dataloader),
model,
SimpleLossCompute(module.generator, criterion),
optimizer,
lr_scheduler,
mode="train+log",
accum_iter=config["accum_iter"],
train_state=train_state,
)
GPUtil.showUtilization()
if is_main_process:
file_path = "%s%.2d.pt" % (config["file_prefix"], epoch)
torch.save(module.state_dict(), file_path)
torch.cuda.empty_cache()
print(f"[GPU{gpu}] Epoch {epoch} Validation ====", flush=True)
model.eval()
sloss = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in valid_dataloader),
model,
SimpleLossCompute(module.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)
print(sloss)
torch.cuda.empty_cache()
if is_main_process:
file_path = "%sfinal.pt" % config["file_prefix"]
torch.save(module.state_dict(), file_path)
def train_distributed_model(vocab_src, vocab_tgt, spacy_de, spacy_en, config):
from the_annotated_transformer import train_worker
ngpus = torch.cuda.device_count()
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12356"
print(f"Number of GPUs detected: {ngpus}")
print("Spawning training processes ...")
mp.spawn(
train_worker,
nprocs=ngpus,
args=(ngpus, vocab_src, vocab_tgt, spacy_de, spacy_en, config, True),
)
def train_model(vocab_src, vocab_tgt, spacy_de, spacy_en, config):
if config["distributed"]:
train_distributed_model(
vocab_src, vocab_tgt, spacy_de, spacy_en, config
)
else:
train_worker(
0, 1, vocab_src, vocab_tgt, spacy_de, spacy_en, config, False
)
def load_trained_model():
config = {
"batch_size": 32,
"distributed": False,
"num_epochs": 8,
"accum_iter": 10,
"base_lr": 1.0,
"max_padding": 72,
"warmup": 3000,
"file_prefix": "multi30k_model_",
}
model_path = "multi30k_model_final.pt"
if not exists(model_path):
train_model(vocab_src, vocab_tgt, spacy_de, spacy_en, config)
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
model.load_state_dict(torch.load("multi30k_model_final.pt"))
return model
if is_interactive_notebook():
model = load_trained_model()
一旦训练,我们就可以对模型进行解码以生成一组翻译。这里我们简单地翻译验证集中的第一句话。这个数据集非常小,所以贪婪搜索的翻译结果相当准确。
6.Additional Components: BPE, Search, Averaging
以上内容主要涵盖了transformer模型本身,但其实还有四个附加功能我们没有涉及。不过我们在OpenNMT-py中实现了所有这些附加功能。
- BPE/Word-piece:我们可以使用一个库首先将数据预处理为子词单元。可以参见Rico Sennrich的subword-nmt 来实现。这些模型会将训练数据转换为如下所示:
▁Die ▁Protokoll datei ▁kann ▁ heimlich ▁per ▁E - Mail ▁oder ▁FTP ▁an ▁einen ▁bestimmte n ▁Empfänger ▁gesendet ▁werden - Shared Embeddings:当使用具有共享词汇表的 BPE 时,我们可以在源/目标/生成器之间共享相同的权重向量。 有关详细信息,请参阅(引用)。 要将其添加到模型中,只需执行以下操作:
if False:
model.src_embed[0].lut.weight = model.tgt_embeddings[0].lut.weight
model.generator.lut.weight = model.tgt_embed[0].lut.weight
- Beam Search:这有点太复杂了,无法在这里介绍。有关pytorch实现,请参阅OpenNMT-py。
- Model Averaging:论文对最后k个检查点进行平均以得到集成效果。如果我们有一堆模型,我们可以这样做:
def average(model, models):
"Average models into model"
for ps in zip(*[m.params() for m in [model] + models]):
ps[0].copy_(torch.sum(*ps[1:]) / len(ps[1:]))
7.Results
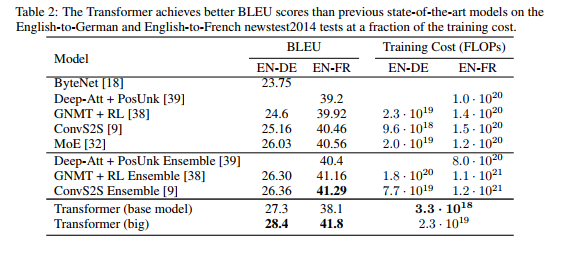
在WMT 2014 英语-德语翻译任务中,big transformer模型(表2中的Transformer (big)) 比之前报道的最佳模型(包括集成模型)高出2.0 BLEU以上, 新的最高BLEU分数为28.4。该模型的配置列于表3的底部,模型在8个P100 GPU上训练3.5天。即使是我们的基础模型,其表现也超过了之前的模型和集成模型,且模型训练成本比之前模型要小的多。
在WMT 2014英语-法语翻译任务中,我们的big model的BLEU得分达到41.0分,优于之前发布的所有单一模型,训练成本不到之前最先进模型的1/4。英语-法语翻译任务训练的Transformer (big)模型使用的丢弃率为Pdrop = 0.1,而不是0.3。
通过上一节讲的几个附加功能,OpenNMT-py在EN-DE WMT上得分可以达到26.9。下面,我将这些参数加载到我的代码重现中。
# Load data and model for output checks
def check_outputs(
valid_dataloader,
model,
vocab_src,
vocab_tgt,
n_examples=15,
pad_idx=2,
eos_string="</s>",
):
results = [()] * n_examples
for idx in range(n_examples):
print("\nExample %d ========\n" % idx)
b = next(iter(valid_dataloader))
rb = Batch(b[0], b[1], pad_idx)
greedy_decode(model, rb.src, rb.src_mask, 64, 0)[0]
src_tokens = [
vocab_src.get_itos()[x] for x in rb.src[0] if x != pad_idx
]
tgt_tokens = [
vocab_tgt.get_itos()[x] for x in rb.tgt[0] if x != pad_idx
]
print(
"Source Text (Input) : "
+ " ".join(src_tokens).replace("\n", "")
)
print(
"Target Text (Ground Truth) : "
+ " ".join(tgt_tokens).replace("\n", "")
)
model_out = greedy_decode(model, rb.src, rb.src_mask, 72, 0)[0]
model_txt = (
" ".join(
[vocab_tgt.get_itos()[x] for x in model_out if x != pad_idx]
).split(eos_string, 1)[0]
+ eos_string
)
print("Model Output : " + model_txt.replace("\n", ""))
results[idx] = (rb, src_tokens, tgt_tokens, model_out, model_txt)
return results
def run_model_example(n_examples=5):
global vocab_src, vocab_tgt, spacy_de, spacy_en
print("Preparing Data ...")
_, valid_dataloader = create_dataloaders(
torch.device("cpu"),
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=1,
is_distributed=False,
)
print("Loading Trained Model ...")
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
model.load_state_dict(
torch.load("multi30k_model_final.pt", map_location=torch.device("cpu"))
)
print("Checking Model Outputs:")
example_data = check_outputs(
valid_dataloader, model, vocab_src, vocab_tgt, n_examples=n_examples
)
return model, example_data
# execute_example(run_model_example)
7.1 Attention Visualization
就算使用贪婪解码,翻译效果看起来也不错。我们可以进一步将其可视化,以查看注意力的每一层发生了什么
def mtx2df(m, max_row, max_col, row_tokens, col_tokens):
"convert a dense matrix to a data frame with row and column indices"
return pd.DataFrame(
[
(
r,
c,
float(m[r, c]),
"%.3d %s"
% (r, row_tokens[r] if len(row_tokens) > r else "<blank>"),
"%.3d %s"
% (c, col_tokens[c] if len(col_tokens) > c else "<blank>"),
)
for r in range(m.shape[0])
for c in range(m.shape[1])
if r < max_row and c < max_col
],
# if float(m[r,c]) != 0 and r < max_row and c < max_col],
columns=["row", "column", "value", "row_token", "col_token"],
)
def attn_map(attn, layer, head, row_tokens, col_tokens, max_dim=30):
df = mtx2df(
attn[0, head].data,
max_dim,
max_dim,
row_tokens,
col_tokens,
)
return (
alt.Chart(data=df)
.mark_rect()
.encode(
x=alt.X("col_token", axis=alt.Axis(title="")),
y=alt.Y("row_token", axis=alt.Axis(title="")),
color="value",
tooltip=["row", "column", "value", "row_token", "col_token"],
)
.properties(height=400, width=400)
.interactive()
)
def get_encoder(model, layer):
return model.encoder.layers[layer].self_attn.attn
def get_decoder_self(model, layer):
return model.decoder.layers[layer].self_attn.attn
def get_decoder_src(model, layer):
return model.decoder.layers[layer].src_attn.attn
def visualize_layer(model, layer, getter_fn, ntokens, row_tokens, col_tokens):
# ntokens = last_example[0].ntokens
attn = getter_fn(model, layer)
n_heads = attn.shape[1]
charts = [
attn_map(
attn,
0,
h,
row_tokens=row_tokens,
col_tokens=col_tokens,
max_dim=ntokens,
)
for h in range(n_heads)
]
assert n_heads == 8
return alt.vconcat(
charts[0]
# | charts[1]
| charts[2]
# | charts[3]
| charts[4]
# | charts[5]
| charts[6]
# | charts[7]
# layer + 1 due to 0-indexing
).properties(title="Layer %d" % (layer + 1))
7.2 Encoder Self Attention
def viz_encoder_self():
model, example_data = run_model_example(n_examples=1)
example = example_data[
len(example_data) - 1
] # batch object for the final example
layer_viz = [
visualize_layer(
model, layer, get_encoder, len(example[1]), example[1], example[1]
)
for layer in range(6)
]
return alt.hconcat(
layer_viz[0]
# & layer_viz[1]
& layer_viz[2]
# & layer_viz[3]
& layer_viz[4]
# & layer_viz[5]
)
show_example(viz_encoder_self)
Preparing Data ...
Loading Trained Model ...
Checking Model Outputs:
Example 0 ========
Source Text (Input) : <s> Zwei Frauen in pinkfarbenen T-Shirts und <unk> unterhalten sich vor einem <unk> . </s>
Target Text (Ground Truth) : <s> Two women wearing pink T - shirts and blue jeans converse outside clothing store . </s>
Model Output : <s> Two women in pink shirts and face are talking in front of a <unk> . </s>

7.3 Decoder Self Attention
def viz_decoder_self():
model, example_data = run_model_example(n_examples=1)
example = example_data[len(example_data) - 1]
layer_viz = [
visualize_layer(
model,
layer,
get_decoder_self,
len(example[1]),
example[1],
example[1],
)
for layer in range(6)
]
return alt.hconcat(
layer_viz[0]
& layer_viz[1]
& layer_viz[2]
& layer_viz[3]
& layer_viz[4]
& layer_viz[5]
)
show_example(viz_decoder_self)
Preparing Data ...
Loading Trained Model ...
Checking Model Outputs:
Example 0 ========
Source Text (Input) : <s> Eine Gruppe von Männern in Kostümen spielt Musik . </s>
Target Text (Ground Truth) : <s> A group of men in costume play music . </s>
Model Output : <s> A group of men in costumes playing music . </s>
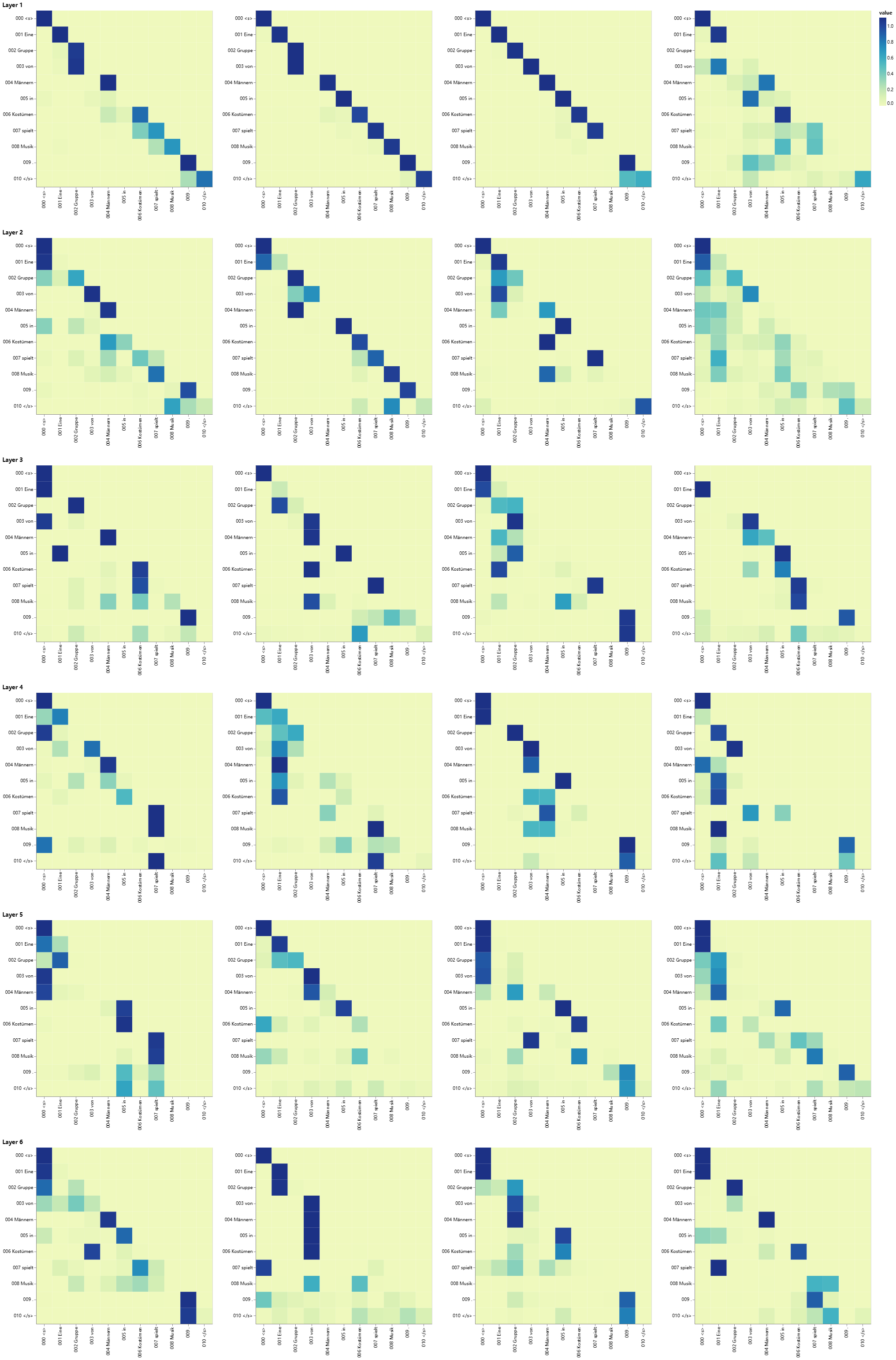
7.4 Decoder Src Attention
def viz_decoder_src():
model, example_data = run_model_example(n_examples=1)
example = example_data[len(example_data) - 1]
layer_viz = [
visualize_layer(
model,
layer,
get_decoder_src,
max(len(example[1]), len(example[2])),
example[1],
example[2],
)
for layer in range(6)
]
return alt.hconcat(
layer_viz[0]
& layer_viz[1]
& layer_viz[2]
& layer_viz[3]
& layer_viz[4]
& layer_viz[5]
)
show_example(viz_decoder_src)
Preparing Data ...
Loading Trained Model ...
Checking Model Outputs:
Example 0 ========
Source Text (Input) : <s> Ein kleiner Junge verwendet einen Bohrer , um ein Loch in ein Holzstück zu machen . </s>
Target Text (Ground Truth) : <s> A little boy using a drill to make a hole in a piece of wood . </s>
Model Output : <s> A little boy uses a machine to be working in a hole in a log . </s>
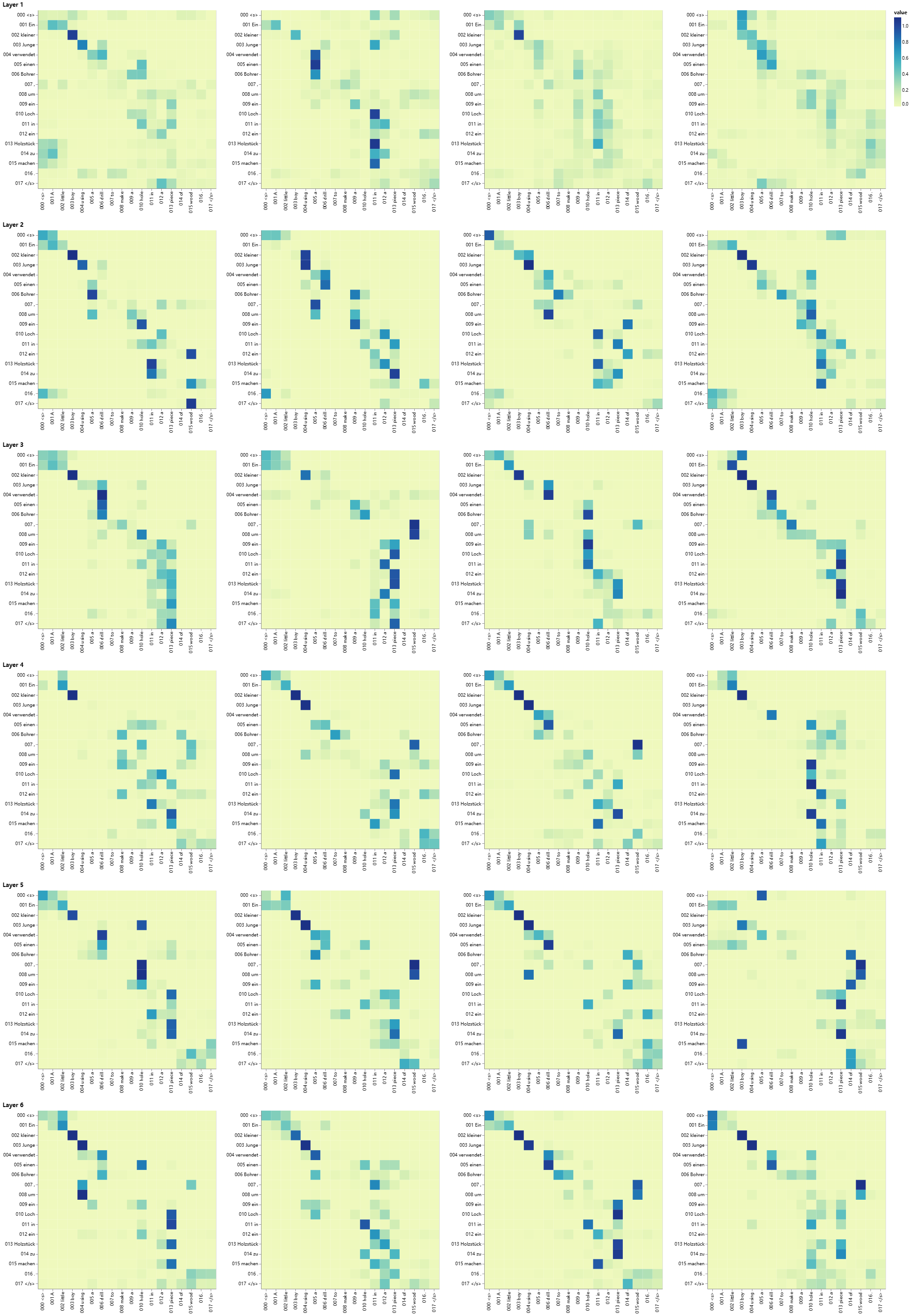
8.Conclusion
希望这段代码对未来的研究有用。 如果您有任何问题,请联系我们。