文章目录
- 一、Transformer的结构是什么样的?
- 二、Transformer Decoder端的输入具体是什么?
- 三、Transformer中一直强调的self-attention是什么?self-attention的计算过程?为什么它能发挥如此大的作用?
- 四、 Transformer为什么需要进行Multi-head Attention?这样做有什么好处?Multi-head Attention的计算过程?
- 五、Transformer相比于RNN/LSTM,有什么优势?为什么?
- 六、Transformer是如何训练的?测试阶段如何进行测试呢?
- 七、Transformer中的Add&Norm模块,具体是怎么做的?
- 八、为什么说Transformer可以代替seq2seq?
- 九、Transformer中句子的encoder表示是什么?如何加入词序信息的?
- 十、self-attention公式中的归一化有什么作用?
Transformer
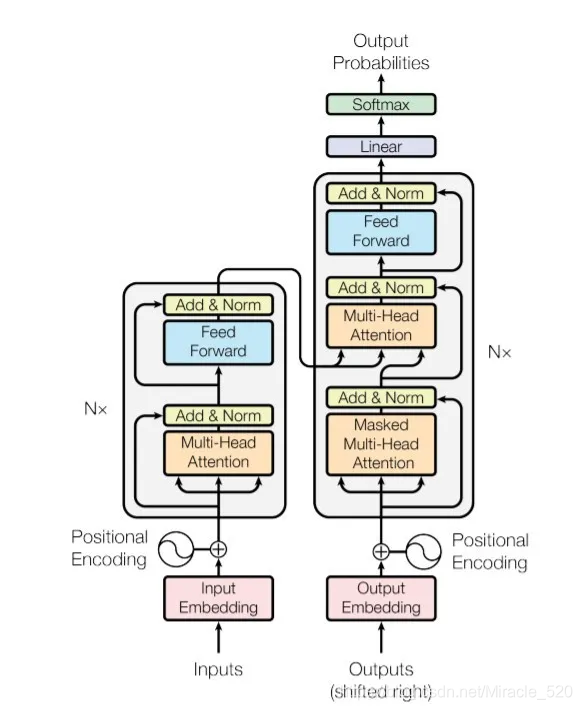
一、Transformer的结构是什么样的?
Transformer本身还是一个典型的encoder-decoder模型,如果从模型层面来看,Transformer实际上就像一个seq2seq with attention的模型,下面大概说明一下Transformer的结构以及各个模块的组成。
1.1 Encoder端&Decoder端总览
Encoder端由N(原论文中N=6)个相同的大模块堆叠而成,其中每个大模块又由两个子模块构成,这两个子模块分别为多头self-attention模块,以及一个前馈神经网络模块;
- Encoder端每个大模块接收的输入是不一样的,第一个大模块接收的输入是输入序列的embedding(embedding可以通过word2vec预训练得来),其余大模块接收的是其前一个大模块的输出,最后一个模块的输出作为整个Encoder端的输出。
Decoder端同样由N(原论文中N=6)个相同的大模块堆叠而成,其中每个大模块由三个子模块构成,这三个子模块分别为多头self-attention模块、多头Encoder-Decoder attention 交互模块,以及一个前馈神经网络模块。
- Decoder端第一个大模块训练时和测试时接收的输入是不一样的,并且每次训练时接收的输入也是不一样的(shifted right)。
- 在实际实现中,不会这样动态的输入,而是一次性把目标序列的embedding通通输入到第一个大模块中,然后在多头attention模块对序列进行mask即可。
- 测试时,先生成第一个位置的输出,有了这个之后,第二次预测时,再将其加入到输入序列,以此类推直至预测结束。
1.2 Encoder端各个子模块
1.2.1 多头self-attention模块
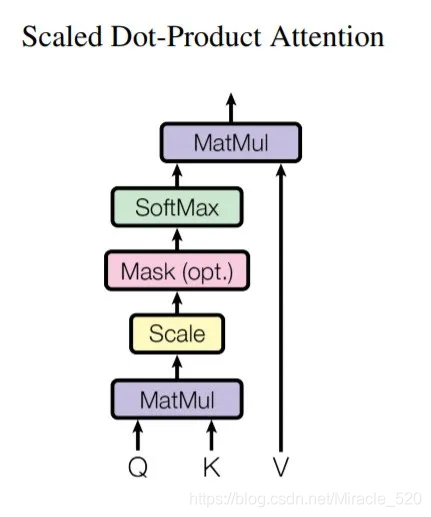
上述attention可以被描述为将query和key-value键值对的一组集合映射到输出,其中query,keys,values和输出都是向量,其中query和keys的维度均为dk,values的维度为dv(论文中dk=dv=dmodel/h=64),输出被计算为values的加权和,其中分配给每个values的权重由query与对应的key的相似函数计算得来。这种attention的形式被称为Scaled Dot-Product Attention。
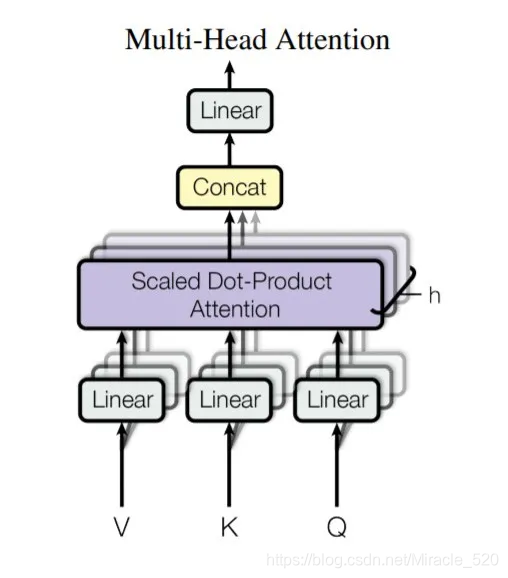
而多头self-attention模块,则是将Q,K,V通过参数矩阵映射后(给Q,K,V分别接一个全连接层),然后再做self-attention,将这个过程重复h(原论文中h=8)次,最后再将所有的结果拼接起来,再送入一个全连接层即可,图示如下:
1.2.2 前馈神经网络模块
前馈神经网络模块(即图示中的Feed Forward)由两个线性变换组成,中间有一个ReLU激活函数。
论文中前馈神经网络模块输入和输出的维度均为dmodel=512,其内层的维度dff=2048.
1.3 Decoder端各个子模块
1.3.1 多头self-attention模块
Decoder端多头self-attention模块与Encoder端的一致,但是Decoder端的多头self-attention需要做mask,因为它在预测时,是“看不到未来的序列的”,所以要将当前预测的单词(token)及其之后的单词(token)全部mask掉。
1.3.2 多头Encoder-Decoder attention 交互模块
多头Encoder-Decoder attention 交互模块的形式与多头self-attention模块一致,唯一不同的是其Q,K,V矩阵的来源,其Q矩阵来源于下面子模块的输出(对应到图中即为masked多头self-attention模块经过Add&Norm后的输出),而K,V矩阵则来源于整个Encoder端的输出,仔细想想其实可以发现,这里的交互模块就跟seq2seq with attention中的机制一样,目的就在于让Decoder端的单词(token)给与Encoder端对应的单词(token)“更多的关注(attention weight)”。
1.3.3 前馈神经网络模块
与Encoder端一致。
1.4 其他模块
1.4.1 Add&Norm模块
Add&Norm模块接在Encoder端和Decoder端每个子模块的后面,其中Add表示残差连接,Norm表示LayerNorm,因此Encoder端和Decoder端每个子模块实际的输出为:LayerNorm(x+Sublayer(x)),其中Sublayer(x)为子模块的输出。
1.4.2 Position Encoder
Position Encoding添加到Encoder端和Decoder端最底部的输入embedding。Position Encoding具有与Embedding相同的维度dmodel,因此可以对两者进行求和。
**需要注意的是,Transformer中的Position Encoding不是通过网络学习得来的,而是直接通过上述公式计算而来的,论文中也实验了利用网络学习Position Encoding,发现结果与上述基本一致,但是论文中选择了正弦和余弦函数版本。
二、Transformer Decoder端的输入具体是什么?
三、Transformer中一直强调的self-attention是什么?self-attention的计算过程?为什么它能发挥如此大的作用?
3.1 self-attention是什么?
self-attention也叫intra-attention,是一种通过自身和自身相关联的attention机制,从而得到一个更好的representation来表达自身,self-attention可以看成一般attention的一种特殊情况。在self-attention中,Q=K=V,序列中的每个单词(token)和该序列中其余单词(token)进行attention计算。
self-attention的特点在于无视词(token)之间的距离,直接计算依赖关系,从而能够学习到序列的内部结构,实现起来也比较简单。
3.2 关于self-attention的计算过程
3.3 self-attention为什么它能发挥如此大的作用?
self-attention是一种自身和自身相关联的attention机制,这样能够得到一个更好的representation来表达自身,在多数情况下,自然会对下游任务有一定的促进作用。
引入self-attention后会更容易捕获句子中长距离的相互依赖特征,因为如果是LSTM或者RNN,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
self-attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,self-attention对计算的并行性也有直接帮助。这是为何self-attention逐渐被广泛使用的主要原因。
四、 Transformer为什么需要进行Multi-head Attention?这样做有什么好处?Multi-head Attention的计算过程?
4.1 why Multi-head Attention
原因是将模型分为多个头,形成多个字空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。(也可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息)
五、Transformer相比于RNN/LSTM,有什么优势?为什么?
5.1 RNN系列的模型,并行计算能力很差
RNN系列的模型T时刻隐层状态的计算,依赖两个输入,一个是T时刻的句子输入单词Xt,另一个是T-1时刻的隐层状态的输出St-1,这是最能体现RNN本质特征的一点,RNN的历史信息是通过这个信息传输渠道往后传输的。而RNN的并行问题就出在这里,因为t时刻的计算依赖t-1时刻的隐层计算结果,而t-1时刻的计算依赖t-2时刻的隐层计算结果,如此下去就形成了所谓的序列依赖关系。
5.2 Transformer的特征抽取能力比RNN系列的模型更好
六、Transformer是如何训练的?测试阶段如何进行测试呢?
6.1 训练
Transformer训练过程与seq2seq类似,首先Encoder端得到输入的encoding表示,并将其输入到Decoder端做交互式attention,之后在Decoder端接收其相应的输入,经过多头self-attention模块之后,结合Encoder端的输出,再经过FFN,得到Decoder端的输出之后,最后经过一个线性全连接层,就可以通过softmax来预测下一个单词(token),然后根据softmax多分类的损失函数,将loss反向传播即可,所以从整体上来说,Transformer训练过程就相当于一个有监督的多分类问题。
需要注意的是,Encoder端可以并行计算,一次性将输入序列全部encoding出来,但Decoder端不是一次性把所有单词(token)预测出来的,而是像seq2seq一样一个接着一个预测出来的。
6.2 测试
测试阶段与训练阶段唯一不同的是Decoder端最底层的输入。
七、Transformer中的Add&Norm模块,具体是怎么做的?
八、为什么说Transformer可以代替seq2seq?
seq2seq最大的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失Encoder端的更多信息,而且这样一股脑的把改固定向量送入Decoder端,Decoder端不能够关注到其想要关注的信息。
Transformer不但对seq2seq模型这两点缺点有了实质性的改进(多头交互attention模块),而且还引入了self-attention模块,让源序列和目标序列首先“自关联”起来,这样的话,源序列和目标序列自身的embedding表示所蕴含的信息更加丰富,而且后续的FFN层也增强了模型的表达能力,并且transformer并行计算能力远远超过seq2seq系统的模型。
九、Transformer中句子的encoder表示是什么?如何加入词序信息的?
Transformer Encoder端得到的是整个输入序列的encoding表示,其中最重要的是经过了self-attention模块,让输入序列的表达更加丰富,而加入词序信息是使用不同频率的正弦和余弦函数。
十、self-attention公式中的归一化有什么作用?
首先说明做归一化的原因,随着dk的增大,q*k点积后的结果也随之增大,这样会将softmax函数推入梯度非常小的区域,使得收敛困难(可能出现梯度消失的情况),为了抵消这种影响,我们将点积缩放1/dk
