论文: https://ieeexplore.ieee.org/document/9103116/
如有侵权请联系博主
介绍
好久没有读过使用GAN来实现图像融合的论文了,正好看到一篇2021年的论文,很感兴趣。
论文中介绍了一种基于多尺度和SE注意力用于可视图像与红外图像融合的方法,网络架构基于GAN,有点类似DDcGAN的结构,也是有两个辨别器。接下来咱们一起来看看吧。
网络架构
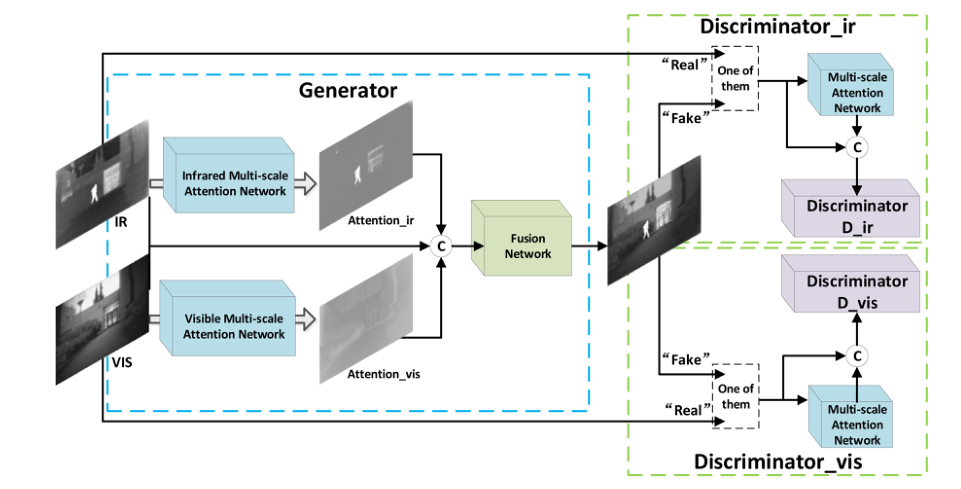
网络的总体架构如上图所示,先来简单看一下,可以认为整个网络由四个组件购成,分别是一个用于提取红外图像中目标信息的网络,一个用于提取可视图像中背景信息的网络和两个用来分辨输入的图像是融合图像还是红外/可视图像。
提取红外图像目标信息的网络

单看这一部分,我相信除了作者谁也不知道这是干啥的,不过还好还有下面这张图
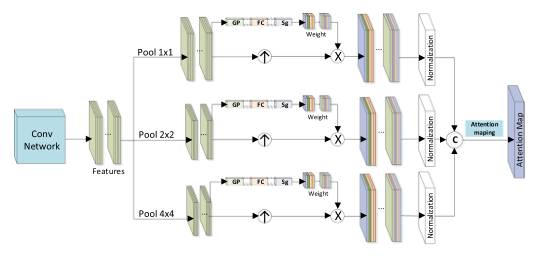
上图就是红外多尺度注意力网络的网络结构,可以看到,整个网络中包含三个尺度的基于注意力的特征提取模块,从上到下,依次为原图像信息,2x2池化之后产生的图像数据和4x4池化之后产生的图像数据。
我们来仔细看一下上面这张图,还是有很多细节的。
依据我们之前所知道的,每一个尺度的图像特征信息的高和宽应该是不同的,那为什么这里直接最后可以把提取到的三个尺度特征信息进行通道维度上的相连呢?
这是因为在SE注意力计算权重之后,并不是权重直接与原尺度特征进行相乘,而是与原尺度特征上采样之后的特征进行相乘,这里的上采样自然是将三个尺度的特征信息信息上采样到同一个高与宽。
作者在文中给出了SE注意力的计算公式。计算公式如下
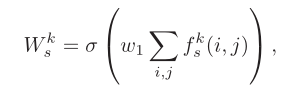
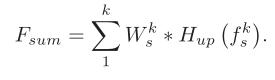
最终将各尺度提取的特征连接在一起就是提取到的红外特征。
可视特征注意力网络与红外的结构以及原理相同。
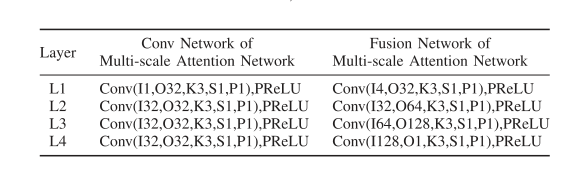
生成器的网络结构如下表所示,包含多尺度特征提取的网络结构和一个融合网络结构。
辨别器
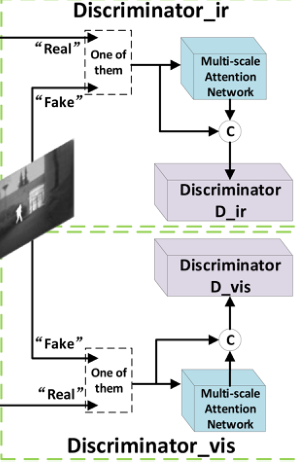
因为两个辨别器的结构大致相同,这里就统一来讲。
类似于DDcGAN的结构,这里也是使用两个辨别器,分别是用来判断是融合图像还是红外图像,是融合图像还是可视图像。
看到上面网络结构之后,你会发现怎么又多了两个多尺度注意力网络?
作者在这里的解释是他希望每个辨别器都可以更加关注应该关注的区域而不是整张图像。那么怎么理解呢
以红外/融合图像辨别器为例,**这里作者希望辨别器更加关注红外图像中的目标信息特征而并非背景信息和全部信息。**同样,可视/融合图像辨别器也是如此。而SE注意力块恰好可以根据目标损失函数进行调整权重,即增大我们想要的特征信息的权重,减小哪些不想要的特征信息的权重。
这样就比较清晰了,辨别器的输入就是多尺度注意力块的输出和原图信息进行相连之后的信息。
辨别器的结构如下表所示,由卷积层Conv和全卷积FC构成。

损失函数
生成器损失函数
先来看下生成器整体的损失函数,三个部分,对抗损失,内容损失和注意力损失。
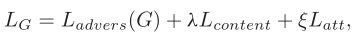
先来看下内容损失,还是我们熟悉的公式,是为了保证融合图像的目标强度信息与可视图像中的相似。
因为毕竟是2021年的论文,没有考虑到可视图像中的显著目标信息,和我们现在经常看到的损失不是很一致。
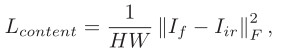
再来看下注意力损失函数,个人认为是本文的亮点
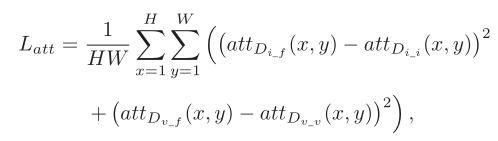
这里att代表的是经过SE注意力处理之后产生的特征信息,在前面我们已经提到了加入SE块的原因就是像生成我们希望注意到的特征信息而并非全局信息,同理这里的att也就是网络认为我们想要注意到的内容。
例如在红外与融合图像鉴别器中,我们肯定希望通过输入图像的显著目标信息来判断输入图像是可视图像还是融合图像。那么怎么判断呢?
就是通过输入图像产生的att进行判断,当融合图像的att与红外图像的att相似度越高时,就说明融合图像包含的红外目标信息更丰富。 同理,可视图像也是如此。
最后就是对抗损失
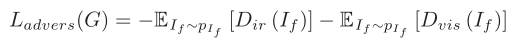
Dir是红外辨别器认为图像是红外图像的概率,Dvis是可视辨别器认为图像是可视图像的概率,我们希望生成器生成的融合图像可以骗过两个辨别器,即两个辨别器认为融合图像是可视/红外图像的概率越高越好,即Dir和Dvis越大越好,带上一个负号就是整体越小越好。
辨别器损失函数
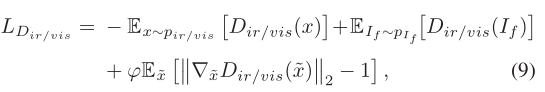
辨别器的损失函数相对来说简单些,即识别来自红外/可视图像中的数据为红外/可视的概率越高越好,识别来自融合图像的数据为红外/可视的概率越低越好,但是这里的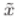 确实不知道是啥意思。。。。。。。麻烦大佬们解答一下。
确实不知道是啥意思。。。。。。。麻烦大佬们解答一下。
总结
整篇文章让我最惊艳的有两个点,第一个就是在多尺度特征提取那里加入了SE块,从而挑选我们想要的特征;另一个就是在损失函数这里,尤其是注意力损失那个地方,通过我们希望注意的区域的特征的对比来判断融合图像中是否包含了可视的纹理信息和红外图像中的目标信息。
其他融合图像论文解读
==》读论文专栏,快来点我呀《==
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] AttentionFGAN: Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks