版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/tfcy694/article/details/87896016
标题:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
作者:Alec Radford等
链接:https://arxiv.org/pdf/1511.06434.pdf
摘要:
Intro
当时的CNN(LeNet、AlexNet等)主要用于监督学习,本文提出的DCGAN可以稳定训练,从而能够用于无监督学习。
本文的四个贡献:
- 提出了可以稳定训练的DCGAN架构。
- 使用了图像分类任务中的CNN作为判别器。
- 对卷积核进行可视化。
- 研究了生成器的一些性质。
相关工作
- 无监督学习:AE等。
- 图片生成模型:GAN、用于生成器的RNN和DeConvNet等。
- 可视化:ZF-Net
核心方法
- 使用stride conv代替最大池化的全卷积网络(the all convolutional net):分别在生成器和判别器中用于降采样和升采样。
- 取消全连接层,引入全局平均池化:增加了稳定性但是减慢收敛速度。
- Batch Normalization:能够使得学习过程更稳定,弥补初始化的无序性。
其它:
- 生成器中的前层使用ReLU激活,输出使用Tanh。
- 判别器使用LeakyReLU激活。
生成器架构:
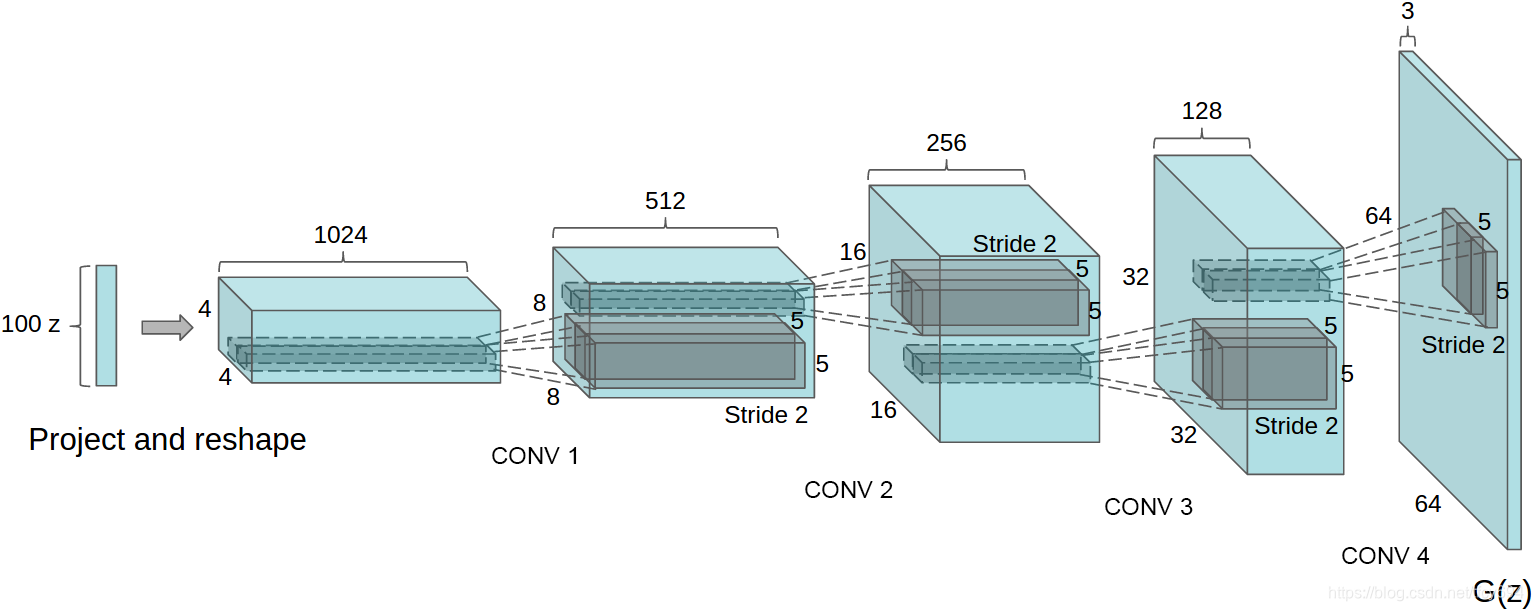
反卷积
之前在ZF-Net和FCN中见过,这里简单写一写自己的理解。deconv的主要作用是升采样(另一种常用升采样的方法是双线性插值)。比如:
对于
的feature map进行
卷积,得到的feature map是
,然后进行(
)填充,通过相同大小的反卷积核之后会得到原始的
特征。
很著名的那个动图介绍了deconv前后的形状变换,很简单,就不贴了。详细的矩阵计算见 https://blog.csdn.net/qq_37791134/article/details/84547562
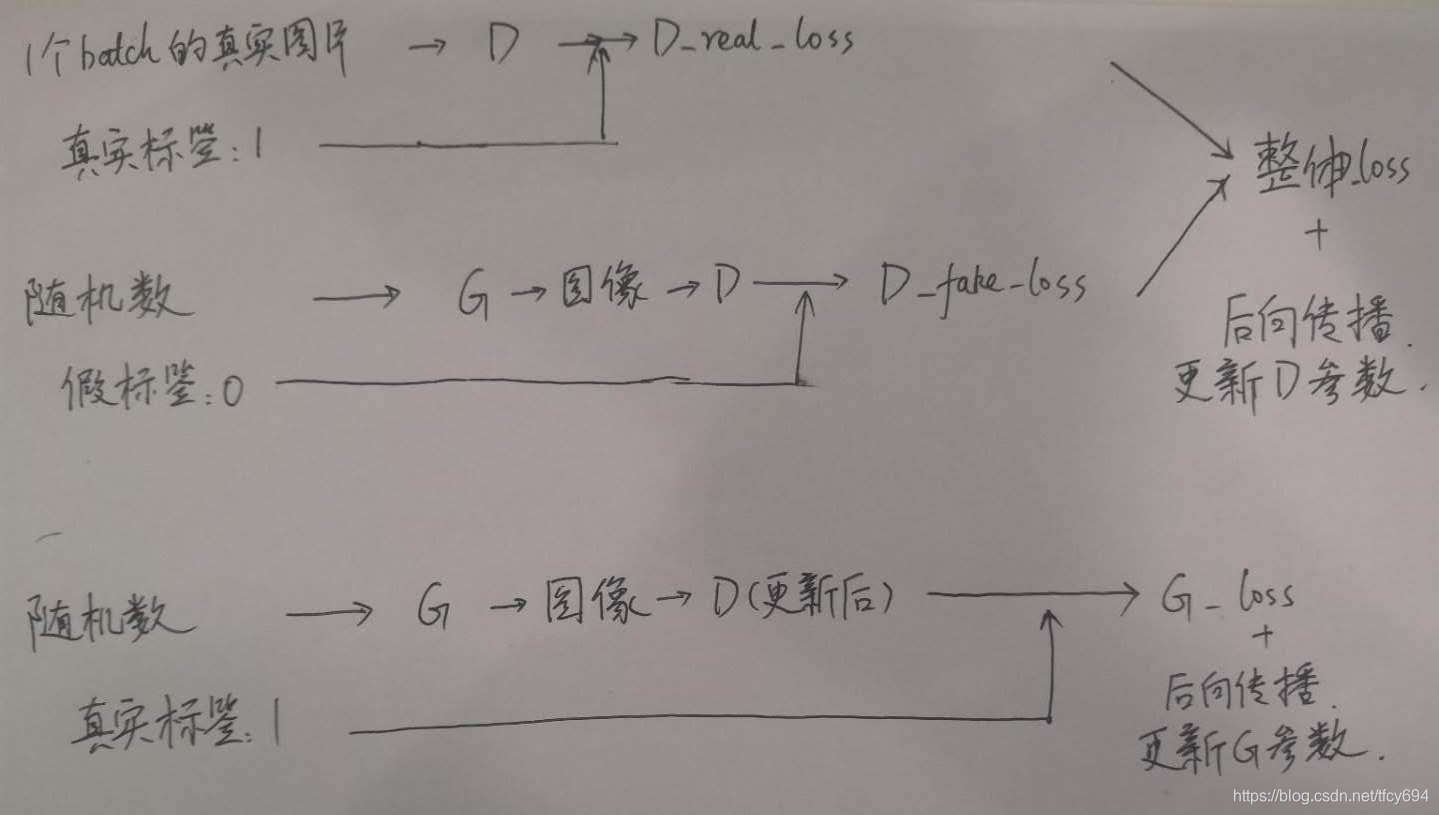
每一个batch的训练过程
每一个batch内分别对判别器具D和生成器G做一次后向传播。