| 模型 | 概述 |
|---|---|
| Transformer | 基于纯注意力机制的编码器和解码器 |
| BERT | 使用transformer的编码器拓展到更一般的NLP任务上,使用完形填空的自监督训练机制,不需要标号,通过预测一个句子中masked的词,从而获取对文本特征的抽取能力,扩展了transformer的应用 |
| ViT | 将transformer用到CV上面 |
| MAE | BERT的CV版本。基于ViT这篇文章,改成自监督训练方式,把整个训练拓展到没有标号的数据上面 |
论文链接:
Masked Autoencoders Are Scalable Vision Learners
一、标题
Masked:带掩码的,和BERT中的masked同样是完形填空的意思。
autoencoder:自编码器,auto不是自动的意思,而是“自”的意思。比如在机器学习里有一类模型叫做自回归模型。指的是标号(y)和样本(x)是来自同一个东西。
scalable:可拓展的,模型比较大
vision learners:视觉学习器,没有强调是classifier等等是表明这个模型适用性较为广泛,是一个backbone模型。比如在语言模型里面,我们用前面的词去预测下面一些词;在另一个样本中,预测词(y)也称为另一个样本x本身。
写论文通常会用的两个单词:scalable和efficient。
- scalable:模型比较大
- efficient:模型比较快
二、Introduction
在计算机视觉中用带掩码的自编码也不是很新鲜。比如denoising atuoencoder:在一个图片中增加很多噪音,通过去噪学习对这个图片的理解。但MAE是基于transformer的。
三、Related work
- BEitT
BERT在image上的应用。对每个patch给了一个离散的标号,在MAE中直接还原的是原始的像素信息。 - self-supervised learning
contrastive learning使用的是data augmentation
在相关工作中最好交代清楚自己工作和相关工作的区别。
四、Approach
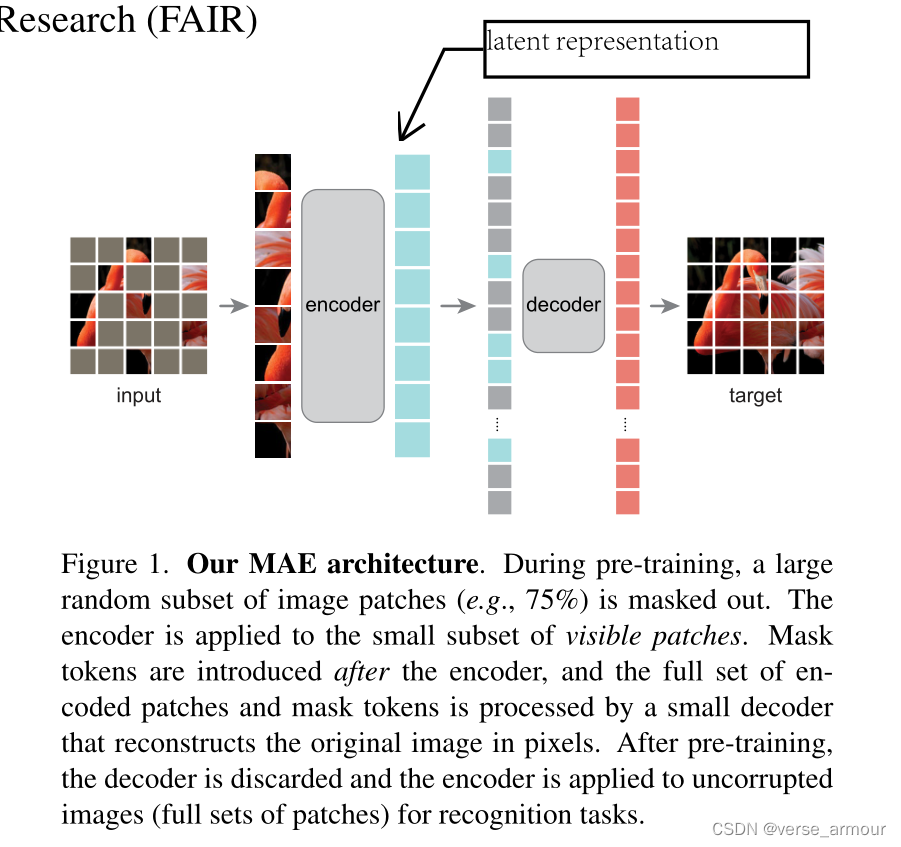
MAE是一个自编码器,看到部分的数据,能重构完整的原始信号。
将观察到的信号映射到一个潜在表示latent representation(语义空间上的一个表示)中,然后再用一个解码器将这个潜在表示去重构出原始的信号。
和经典的自编码器不一样,是一个非对称(asymmetric)的结构。masked token不会输入编码器,用来节省开销。
-
Masking
随机采样75%,使得任务比较困难,迫使模型去学习有用的信息。 -
MAE encoder
a ViT but applied only on visible, unmasked patches. 将没有被盖住的块输入ViT。 -
MAE decoder
解码器需要看到被盖住的块,也需要看到没有被盖住的块,这样才能重构。解码器不再是一个简单的线性层,而是另一个transformer,对被盖住的块需要输入位置编码。此外,解码器主要用于预训练阶段,将MAE用到别的任务时,是不需要解码器的,只需要用编码器对图片进行编码。(预测时应该把解码器拆出来,然后编码器作为特征提取器) -
Recontruction target
decoder的最后一层就是一个线性层。如果patch_size=16 * 16,那么这个线性层就会投影到长度为256的向量,再reshape到16*16就能还原出原始像素信息了。 损失函数使用的是MSE,只对被盖住的块做损失。也可以对要预测的像素做一次normalization,使其均值变0,方差变1,使得数值上更加稳定。 -
Simple implementation:简单实现
随机采样;decoder时,会将之前盖住的pacth生成和之前长度相同的向量(初始化),对所有的patch加上位置编码。再经过损失函数的训练就能训练出最终的向量,最后在经过reshape就可以重构像素信息。
通过shuffle和unshuffle,不需要任何稀疏操作(sparse operations),实现起来非常快,也不影响后面的ViT操作。
五、实验设计
所以MAE最终还是给一个classification任务做pre-training?
是的 预训练,最近一篇2D人体关键点检测的论文VITAE 也是用的MAE预训练,SOTA了 效果确实好
还可以只用两个transformer?
<-MAE只是用了Transformer论文中编码器块作为编码器和解码器的组成单元,MAE所用的自编码器的编码器、解码器概念和Transformer是不同的。
如何找idea
