【读论文】THFuse
论文: https://www.sciencedirect.com/science/article/abs/pii/S0925231223000437
如有侵权请联系博主
介绍
一篇基于CNN和VIT的关于红外可视图像融合的论文,论文中提出了两分支的CNN提取模块的方法以及常规VIT和跨通道的VIT相结合的方法来提取特征,接下来一起来看看吧。
网络架构
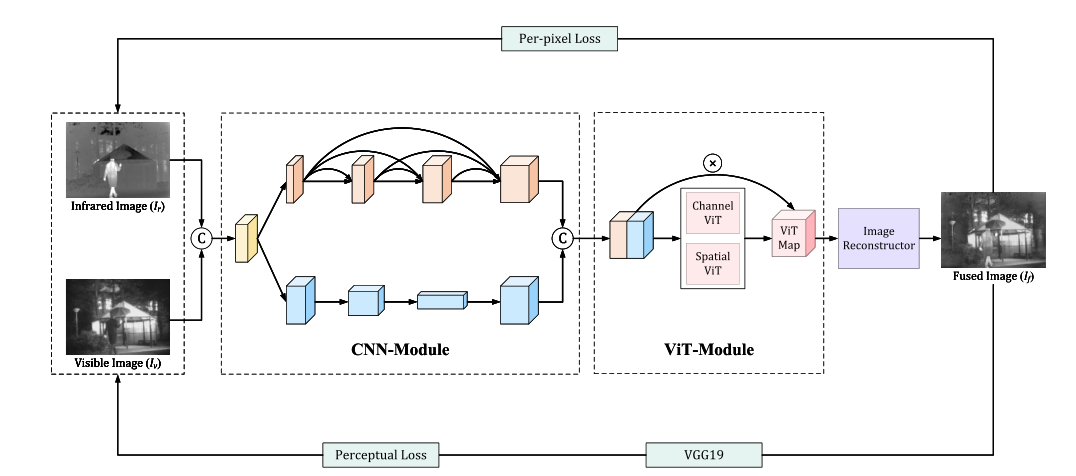
整体架构如上图所示,还是很简单明了的,大体就可以分为三块,分别是多分支CNN特征提取块,基于VIT的全局特征提取快和图像重建块,接下来我们一个个来看。
多分支CNN特征提取块
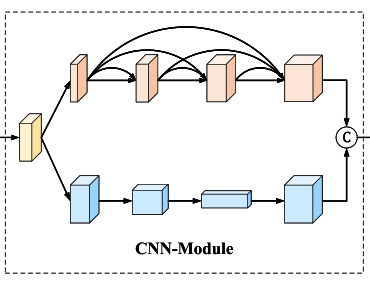
目前来看,虽然基于视觉的tranformer在各项任务中都获得了不错的效果,但是我们仍不能仅仅依靠tranformer来获取信息,CNN提取的局部信息也是十分重要的,因此作者在VIT模块之前仍是添加了一个CNN块。
整体的结构如上图所示,可以看到最开始有一个卷积层,主要的作用就是用来升维,图像数据被升维至16。而后处理后的数据被输入两个分支,分别是细节提取分支和结构特征提取分支,依次对应图中的上下两个分支。
细节提取分支采用densenet的结构用来提取细节特征,减少了卷积过程中细节的丢失,这里采用的卷积方式是有padding的卷积,即卷积之后图片大小是不会改变的,因此这一分支中没有上采样操作,避免了下采样时特征信息的丢失。
结构提取分支主要用于提取图像的结构信息,而图像的结构信息往往在更小尺度的特征信息中更加可以得以体现,因此该分支进行的卷积不采用padding的方式,并且每次卷积之后,特征信息都会减半。因为该分支输出的特征还是要和细节提取分支的特征进行拼接,因此还是需要对该分支的特征信息进行上采样至与原图同样大小,然后再与细节提取分支的特征进行拼接。
基于VIT的全局特征提取快
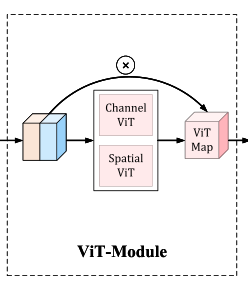
该模块还是很有意思的,首先先对两个分支生成的特征进行卷积操作,然后进入了包含了常规VIT和通道级的VIT的全局特征信息提取块中。我们熟悉的常规的VIT是先将图片划分为一个个的patch,然后每一个patch拉伸为一个向量,这些向量之间执行transformer中的操作。
而通道级的VIT则是在图像的通道间执行transformer中的操作,从而使得每一个通道中都包含其余通道中的信息。
图像重建块
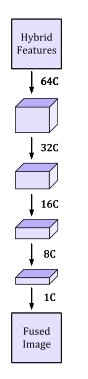
图像重建快看着有点长,其实很简单,就是将之前提取的特征一步步进行降维,最终降维至1时,就是融合图像了。
损失函数
论文中使用的损失函数可以分为两部分,第一部分就是像素级的损失,另一方面就是特征级别的损失,总体损失函数如下图所示。
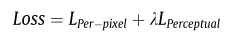
这里先来看下像素级的损失,该损失共有三部份组成,分别用来保证目标强度信息,结构损失以及纹理信息的损失。
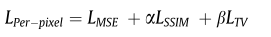
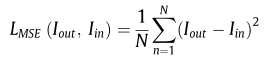
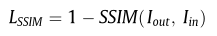
强度损失和结构损失如上,就不过多描述了,是我们熟悉的公式,主要是纹理信息这里

这里做了一个很有趣的处理,从这看的话我觉得是有点迷迷糊糊的,但是我们可以把这个公式拆一下
把第一部分拆开
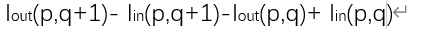
然后再稍稍换换位置
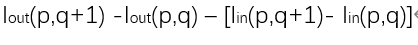
这时公式就变成了融合图像和原图像同一点上下两像素之间差值的比较,而我们知道图像中的梯度就是通过相邻像素值的差别来表述的,那我们就明白了,这个损失函数希望融合图像和原图像之间的梯度尽可能的相似,也就实现了保留梯度信息的目的。第二部分与这里同理。
作者这里也提到了该损失函数的另一作用,即抑制噪声,而我们清楚的知道出现噪声时梯度会出现明显的变化,即当融合图像中出现了原图像中本不存在的噪声,那么也会产生原图像中不存在的梯度,前面我们已经提到了该损失函数的作用就是使得融合图像和原图像之间的梯度尽可能的相似,那么从某种意义上来说也是抑制了噪声的出现。
接下来就是特征级别得损失,这一部分类似于AttentionFGAN提出的方法,这里作者采用预先训练好的VGG19来提取融合图像的特征,如下图,绿色线代表的是可视图像中的特征,红色的线代表的是融合图像中的特征,蓝色的线代表的是红外图像中的特征,作者认为纹理信息在浅层中比较突出,因此采用可视图像和融合图像中浅层特征去比较来突出纹理信息,并且作者认为深层信息中的目标信息比较突出,因此采用可视图像和融合图像中深层特征来去比较来突出纹理信息。
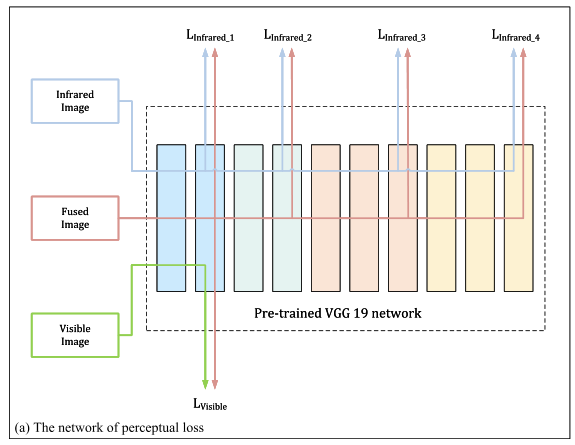
特征损失函数如下
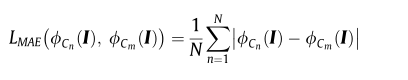
总结
整篇文章读下来很顺畅,有以下几个点我觉得很惊艳
- 采用了两个分支的CNN,用于提取结构信息和细节信息
- 首先就是用于通道级transformer
- 采用vgg19来重新获取融合图像和原图像特征来进行比对,从而使得融合图像中有更多的信息
读完了之后,收获很多,涨了很多新知识。
其他融合图像论文解读
==》读论文专栏,快来点我呀《==
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor