一、K-近邻算法(KNN)
1、定义
KNN
K:就是一个自然数
N:nearest,最近的
N:neighbourhood,邻居
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
k = 1 容易受到异常点的影响
2、假设有一张北京地图,我不知道我在哪儿,目的是要知道我在北京的哪个区
这是一个分类问题
我不知道我在哪儿,但我知道我跟这几个人之间的距离,并且知道这5个人在哪个区

KNN核心思想:你的“邻居”来推断出你的类别
3、计算距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离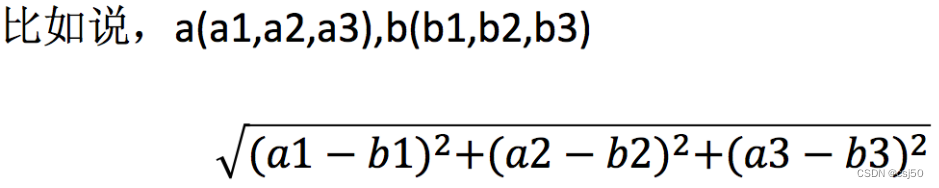
注意:二维空间则是d = sqrt((x2 - x1)^2 + (y2 - y1)^2)
其他距离公式:
曼哈顿距离—绝对值距离
闵可夫斯基距离
4、例子
电影类型分析,假设我们现在有一个训练集
现在有一个未知的电影,根据它的特征来判断是哪个类型的
我们可以利用K近邻算法的思想

k = 1时,匹配到(爱情片)
k = 2时,匹配到(爱情片)
k = 6时,无法确定。。。
5、分析
(1)当k值取值过小的时候,容易受到异常点的影响
(2)当k值取值过大的时候,容易分错,容易受到样本不均衡的影响
(3)当使用k-近邻算法,要做无量纲化的处理(标准化)
6、K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
n_neighbors:int,可选(默认= 5),就是k值,查询默认使用的邻居数
algorithm:{'auto','ball_tree','kd_tree','brute'},可选用于计算最近邻居的算法:'ball_tree'将会使用BallTree,'kd_tree'将使用KDTree,'auto'将尝试根据传递给fit方法的值来决定最合适的算法。(不同实现方式影响效率)
7、调用方法
(1)实例化KNeighborsClassifier分类器
(2)调用fit方法,将训练集的特征值和目标值给传进来,这样就相当于拿到模型了
(3)调用predict方法,拿到预测值,用预测值比对真实值
(4)也可以调用score方法,直接计算准确率
二、鸢尾花种类预测
1、数据集介绍
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集
Iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表
2、属性
sepal length:萼片长度(厘米)
sepal width:萼片宽度(厘米)
petal length:花瓣长度(厘米)
petal width:花瓣宽度(厘米)
class:Setosa山鸢尾、Versicolour变色鸢尾、Virginica维吉尼亚鸢尾
3、步骤
(1)获取数据
(2)数据集划分
(3)特征工程
标准化
(4)机器学习训练:KNN预估器流程
(5)模型评估
4、day02_machine_learning.py
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
def KNN_iris():
"""
用KNN算法对鸢尾花进行分类
"""
# 1、获取数据
iris = load_iris()
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 用训练集的平均值和标准差对测试集的数据来标准化
# 这里测试集和训练集要有一样的平均值和标准差,而fit的工作就是计算平均值和标准差,所以train的那一步用fit计算过了,到了test这就不需要再算一遍自己的了,直接用train的就可以
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == "__main__":
# 代码1:用KNN算法对鸢尾花进行分类
KNN_iris()
运行结果:
y_predict:
[0 2 0 0 2 1 1 0 2 1 2 1 2 2 1 1 2 1 1 0 0 2 0 0 1 1 1 2 0 1 0 1 0 0 1 2 1
2]
直接比对真实值和预测值:
[ True True True True True True False True True True True True
True True True False True True True True True True True True
True True True True True True True True True True False True
True True]
准确率为:
0.9210526315789473三、代码说明
1、我们用的鸢尾花数据集是一个表格数据,例如
2、在代码中获取的iris = load_iris()数据集,就包含了特征值iris.data和目标值iris.target
iris.data:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
[5.7 3.8 1.7 0.3]
[5.1 3.8 1.5 0.3]
[5.4 3.4 1.7 0.2]
[5.1 3.7 1.5 0.4]
[4.6 3.6 1. 0.2]
[5.1 3.3 1.7 0.5]
[4.8 3.4 1.9 0.2]
[5. 3. 1.6 0.2]
[5. 3.4 1.6 0.4]
[5.2 3.5 1.5 0.2]
[5.2 3.4 1.4 0.2]
[4.7 3.2 1.6 0.2]
[4.8 3.1 1.6 0.2]
[5.4 3.4 1.5 0.4]
[5.2 4.1 1.5 0.1]
[5.5 4.2 1.4 0.2]
[4.9 3.1 1.5 0.2]
[5. 3.2 1.2 0.2]
[5.5 3.5 1.3 0.2]
[4.9 3.6 1.4 0.1]
[4.4 3. 1.3 0.2]
[5.1 3.4 1.5 0.2]
[5. 3.5 1.3 0.3]
[4.5 2.3 1.3 0.3]
[4.4 3.2 1.3 0.2]
[5. 3.5 1.6 0.6]
[5.1 3.8 1.9 0.4]
[4.8 3. 1.4 0.3]
[5.1 3.8 1.6 0.2]
[4.6 3.2 1.4 0.2]
[5.3 3.7 1.5 0.2]
[5. 3.3 1.4 0.2]
[7. 3.2 4.7 1.4]
[6.4 3.2 4.5 1.5]
[6.9 3.1 4.9 1.5]
[5.5 2.3 4. 1.3]
[6.5 2.8 4.6 1.5]
[5.7 2.8 4.5 1.3]
[6.3 3.3 4.7 1.6]
[4.9 2.4 3.3 1. ]
[6.6 2.9 4.6 1.3]
[5.2 2.7 3.9 1.4]
[5. 2. 3.5 1. ]
[5.9 3. 4.2 1.5]
[6. 2.2 4. 1. ]
[6.1 2.9 4.7 1.4]
[5.6 2.9 3.6 1.3]
[6.7 3.1 4.4 1.4]
[5.6 3. 4.5 1.5]
[5.8 2.7 4.1 1. ]
[6.2 2.2 4.5 1.5]
[5.6 2.5 3.9 1.1]
[5.9 3.2 4.8 1.8]
[6.1 2.8 4. 1.3]
[6.3 2.5 4.9 1.5]
[6.1 2.8 4.7 1.2]
[6.4 2.9 4.3 1.3]
[6.6 3. 4.4 1.4]
[6.8 2.8 4.8 1.4]
[6.7 3. 5. 1.7]
[6. 2.9 4.5 1.5]
[5.7 2.6 3.5 1. ]
[5.5 2.4 3.8 1.1]
[5.5 2.4 3.7 1. ]
[5.8 2.7 3.9 1.2]
[6. 2.7 5.1 1.6]
[5.4 3. 4.5 1.5]
[6. 3.4 4.5 1.6]
[6.7 3.1 4.7 1.5]
[6.3 2.3 4.4 1.3]
[5.6 3. 4.1 1.3]
[5.5 2.5 4. 1.3]
[5.5 2.6 4.4 1.2]
[6.1 3. 4.6 1.4]
[5.8 2.6 4. 1.2]
[5. 2.3 3.3 1. ]
[5.6 2.7 4.2 1.3]
[5.7 3. 4.2 1.2]
[5.7 2.9 4.2 1.3]
[6.2 2.9 4.3 1.3]
[5.1 2.5 3. 1.1]
[5.7 2.8 4.1 1.3]
[6.3 3.3 6. 2.5]
[5.8 2.7 5.1 1.9]
[7.1 3. 5.9 2.1]
[6.3 2.9 5.6 1.8]
[6.5 3. 5.8 2.2]
[7.6 3. 6.6 2.1]
[4.9 2.5 4.5 1.7]
[7.3 2.9 6.3 1.8]
[6.7 2.5 5.8 1.8]
[7.2 3.6 6.1 2.5]
[6.5 3.2 5.1 2. ]
[6.4 2.7 5.3 1.9]
[6.8 3. 5.5 2.1]
[5.7 2.5 5. 2. ]
[5.8 2.8 5.1 2.4]
[6.4 3.2 5.3 2.3]
[6.5 3. 5.5 1.8]
[7.7 3.8 6.7 2.2]
[7.7 2.6 6.9 2.3]
[6. 2.2 5. 1.5]
[6.9 3.2 5.7 2.3]
[5.6 2.8 4.9 2. ]
[7.7 2.8 6.7 2. ]
[6.3 2.7 4.9 1.8]
[6.7 3.3 5.7 2.1]
[7.2 3.2 6. 1.8]
[6.2 2.8 4.8 1.8]
[6.1 3. 4.9 1.8]
[6.4 2.8 5.6 2.1]
[7.2 3. 5.8 1.6]
[7.4 2.8 6.1 1.9]
[7.9 3.8 6.4 2. ]
[6.4 2.8 5.6 2.2]
[6.3 2.8 5.1 1.5]
[6.1 2.6 5.6 1.4]
[7.7 3. 6.1 2.3]
[6.3 3.4 5.6 2.4]
[6.4 3.1 5.5 1.8]
[6. 3. 4.8 1.8]
[6.9 3.1 5.4 2.1]
[6.7 3.1 5.6 2.4]
[6.9 3.1 5.1 2.3]
[5.8 2.7 5.1 1.9]
[6.8 3.2 5.9 2.3]
[6.7 3.3 5.7 2.5]
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
iris.target:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]可以看到iris.data就是数据集的四个属性,iris.target就是属种,用0、1、2表示
3、train_test_split划分数据集
x_train:训练集的特征值
x_test:测试集的特征值
y_train:训练集的目标值
y_test:测试集的目标值
从后面的代码中可以看到,测试集为38个,则训练集为150-38=112个
4、然后是做特征工程标准化
对训练集的特征值做标准化,对测试集的特征值做标准化
5、实例化KNN分类器
调用fit方法,把标准化后的训练集的特征值,和训练集的目标值传进来,获得模型
6、调用predict方法,把标准化后的测试集的特征值传进来,获得这一行数据花的属种的预测
y_predict:
[0 2 0 0 2 1 1 0 2 1 2 1 2 2 1 1 2 1 1 0 0 2 0 0 1 1 1 2 0 1 0 1 0 0 1 2 1
2]7、再用预测的值和测试集的目标值直接对比,和计算准确率为92%,有几个预测错了
数据集划分不一样,预测的结果就不一样,可以试试random_state=22或23
8、疑问:是不是数据集越大,对同类记录预测的越准确?(大数据)
四、K-近邻算法小结
1、优点
简单,易于理解,易于实现,无需训练
2、缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大
必须指定K值,K值选择不当则分类精度不能保证
3、使用场景
小数据场景,几千~几万样本,具体场景具体业务去测试