
论文链接:https://arxiv.53yu.com/pdf/2110.09419.pdf
代码链接:https://github.com/sarthmit/Compositional-Attention
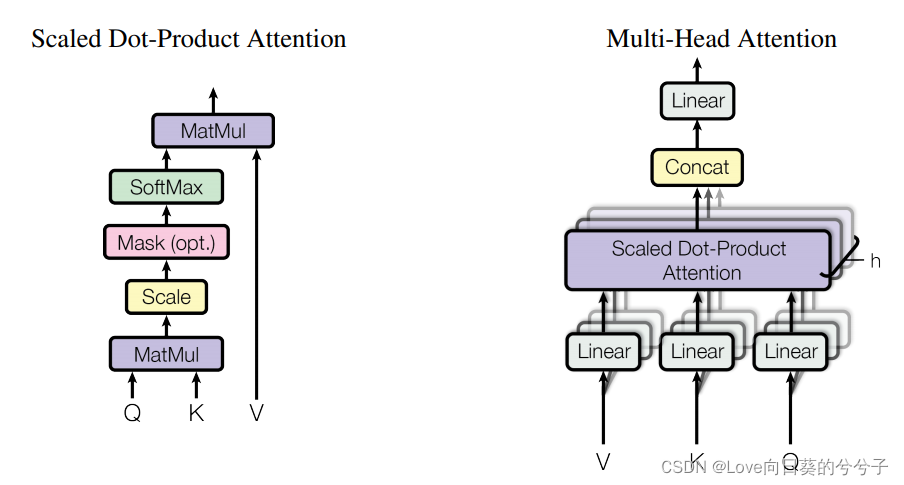
(图片来自论文《attention is all you need》)
- 标准multi-head self-attention
1)Key-Value Attention
给定一组query和key-value对,key值关注计算每个query和key集之间的缩放余弦相似度度量。这个相似度分数决定了对应query的输出中每个值的贡献(权重)。
给定输入 X ∈ R N × d X\in R^{N \times d} X∈RN×d,经过线性转换分别得到query,key和value,公式如下,
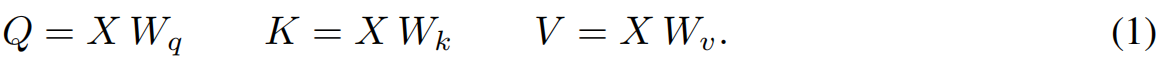
对于每个query,使用缩放余弦相似度(称为缩放点积)计算每个key的相似度得分,以给出用于软组合值的注意权重
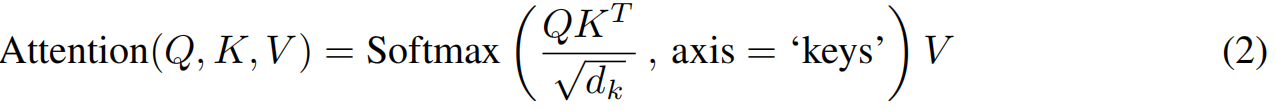
2)多头注意机制
将多个(如 h h h)独立的key-value attention机制并联起来,提供了模型联合注意不同位置的能力,从而提高了模型的表征能力。由这些多个头产生的输出被连接在一起,然后使用一个可学习矩阵线性投影回输入维度:
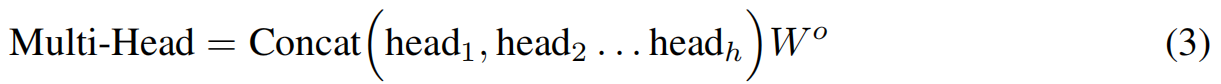
其中每个 h e a d i = A t t e n t i o n ( Q i , K i , V i ) {head}_i = Attention(Q_i, K_i, V_i) headi=Attention(Qi,Ki,Vi)。
1. 动机
由上可知,标准的multi-head self-attention,每个头都学习query-key(搜索)和value(检索)之间的严格映射,这会出现两个问题:
1)导致在某些任务中学习了冗余参数
2)阻碍了泛化
2. 方法
为了解决上述问题,本文提出一种Compositional Attention替代标准的head结构,其中搜索和检索操作可以灵活组合:query-key搜索机制不再绑定到一个固定值检索矩阵,而是从多个组合注意头可访问的值矩阵共享池中动态选择。
- Search和Retrieval组件
1)Search
搜索由query矩阵和key矩阵参数化,即分别为 W q W_q Wq和 W k W_k Wk。这些参数定义了元素对 x j x_j xj和 x k ∈ X x_k \in X xk∈X之间兼容性度量的概念
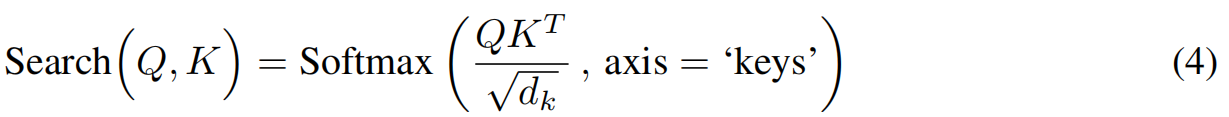
其中 Q = X W q Q = XW_q Q=XWq, K = X W k K = XW_k K=XWk,上面的计算给出了一个元素 x j x_j xj与其他元素 x k x_k xk在搜索参数定义的兼容性度量下的兼容性。
2) Retrieval
检索由一个value矩阵 W v W_v Wv参数化,该value矩阵描述了 X X X中输入元素中与下游任务相关且需要访问的特征类型:
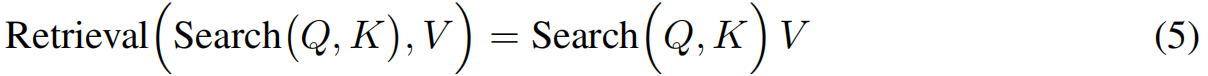
其中 V = X W v V=XW_v V=XWv。注意,每个retrieve都定义了从输入 x k x_k xk中访问的属性类型,并且可以将任何Search结果作为其输入。
3)multi-head attention作为搜索和检索的刚性配对
根据上面的定义,可以看到标准的多头注意力是如何构成搜索和检索的刚性配对的,从而在优化时学习固定属性对的端到端功能。实际上,h个头由h个不同的搜索-检索对组成,第i个检索仅在第i个搜索中执行。因此,多头注意力相当于公式4和5的一个特殊情况

- 刚性关联的缺点
假设这种刚性映射并不总是理想的,有时会导致冗余参数的容量和学习能力下降,从而失去了更好的系统泛化的机会。我们注意到,与每个头关联的搜索定义了一个特征(由query-key矩阵 W q W_q Wq和 W k W_k Wk定义),该特征是根据目标之间的兼容性来计算的。此外,每个头部的检索允许模型从搜索目标中访问特定的特征(由值矩阵 W v W_v Wv定义)。在此之后,将展示两种类型的冗余:
(a) 搜索冗余,它会导致冗余query-key矩阵的学习;
(b)检索冗余,它会导致冗余值矩阵的学习。
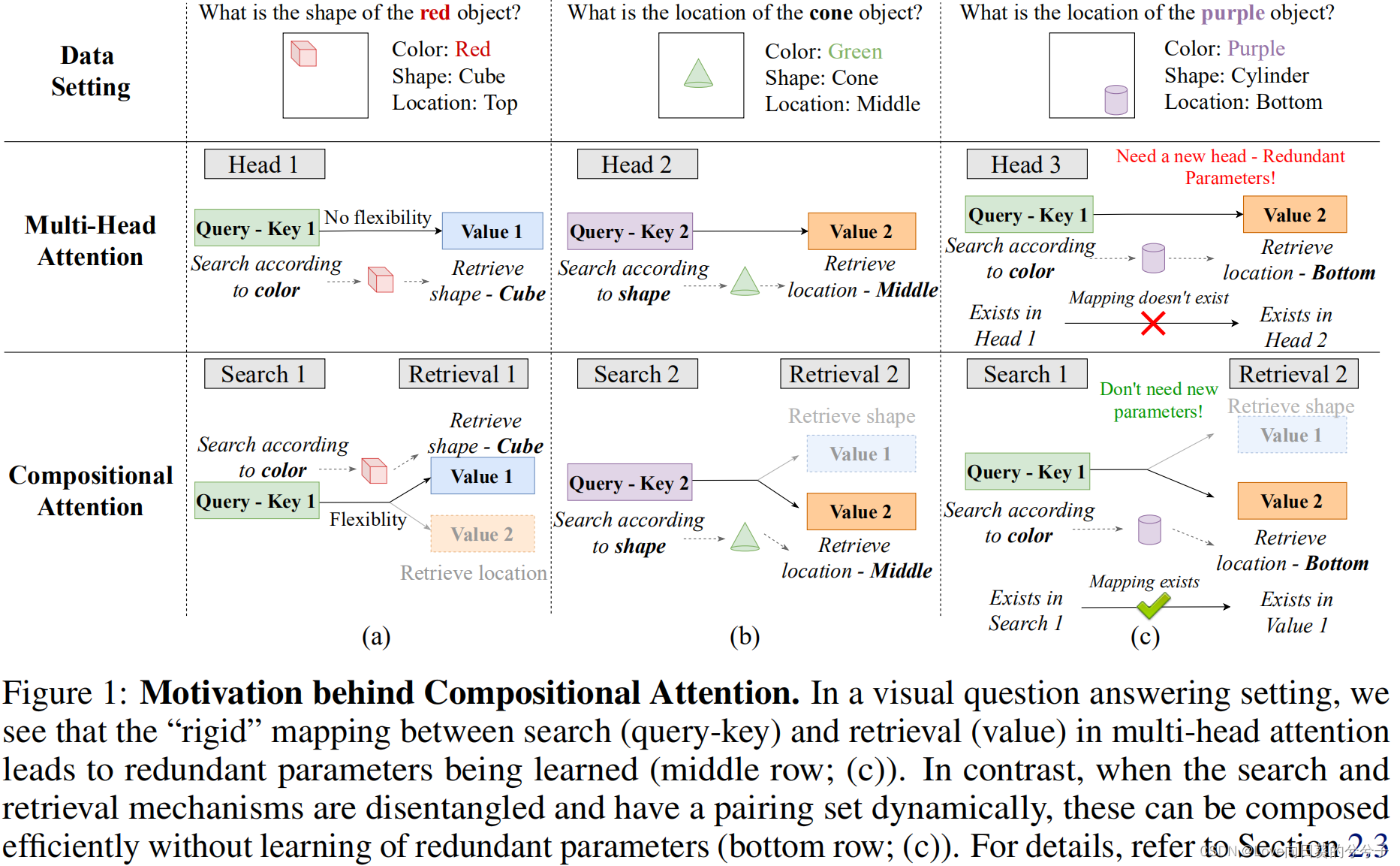
我们使用上图1中所示的一个简单示例来共同强调这两个冗余,其中三个具有属性(形状、颜色和位置)的目标是不同问题的主题。在(a)中,模型需要学习根据颜色进行搜索,并相应检索形状信息;在(b)中,模型需要根据形状进行搜索,并检索位置信息。在这个任务中,标准的多头注意(中间一排)应该学习两个头,分别代表(a)和(b)。要回答©中的问题,模型必须根据颜色进行搜索并检索位置。Head 1学习到的(a)是根据颜色进行搜索,Head 2学习到的(b)是根据位置进行检索,但是没有办法将它们组合起来。因此,需要另一个head来获得对head 1的搜索和对head 2的检索。这导致了参数冗余,并错过了更有效地分解知识的机会,因为这些学习到的知识已经单独存在于head 1和head 2中。
图1中的场景看起来非常理想化,因为multi-head attention可能不会限制单个特征上的搜索/检索,并且能够进行更细致的软组合。虽然这可能是简单示例的情况,但它突出的是刚性学习关联的危险,它限制了习得知识片段的重新组合,导致冗余参数,并可能限制OoD的泛化,无论模型学习了什么。在接下来的内容中,我们建议通过允许 S × R S \times R S×R这样的配对来缓解这个基本的限制, S S S表示搜索类型的数量, R R R表示检索类型的数量。 - compositional attention
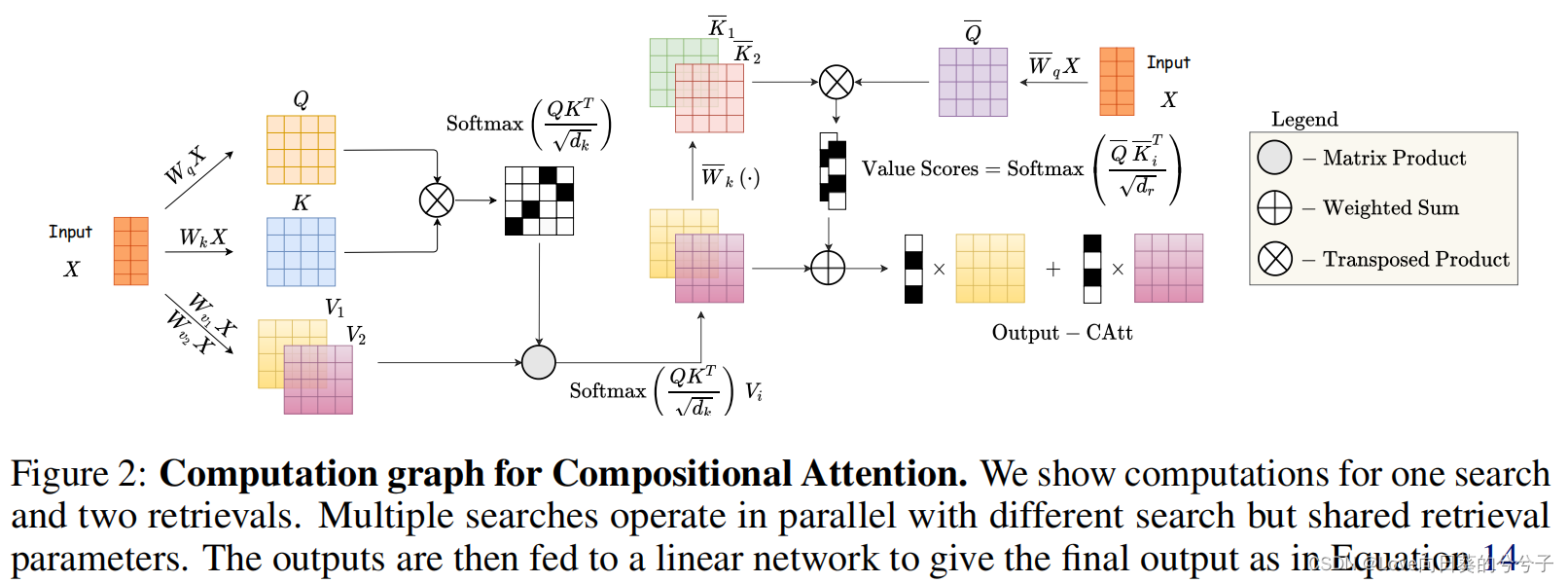
提出了一种新的注意机制,该机制放宽了静态的搜索-检索对,以支持更灵活和动态的映射。为了做到这一点,这里放弃了head的概念,取而代之的是独立和重组的搜索和检索,如上述所定义的那样。核心创新在于这两个组件的组合方式:使用query-key attention检索。
与head类似,首先定义 S S S并行搜索机制。也就是说,我们有 S S S个不同的query-key参数化 W q i W_{q_i} Wqi和 W k i W_{k_i} Wki。每次搜索的输出定义如公式4所示,本质上,对于每个搜索 i i i,可以得到
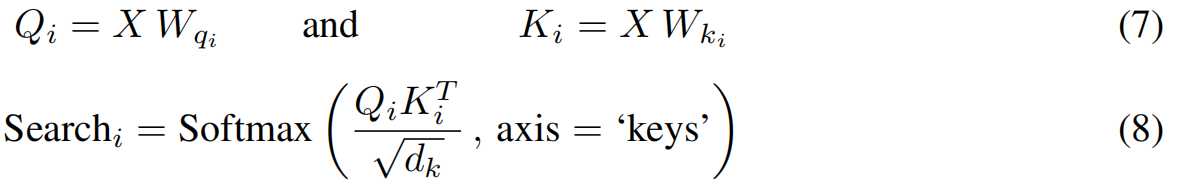
接着,定义了 R R R种不同的检索机制,对应于 R R R种不同的 W v j W_{v_j} Wvj矩阵。这些矩阵用于从输入中获得不同的属性。形式上被总结为

其中 V j V_j Vj突出显示了对不同属性的访问。然后,对应于每个搜索,完成所有可能的检索。与式5相似,定义为

这个步骤为我们提供了每个搜索的所有假设检索,在这个步骤中,每个搜索需要实例化一个检索。这个实例化是通过使用检索queries Q ‾ i \overline{Q}_i Qi和检索keys K ‾ i j \overline{K}_{ij} Kij计算的二级注意机制完成的,它们可以通过如下获得:
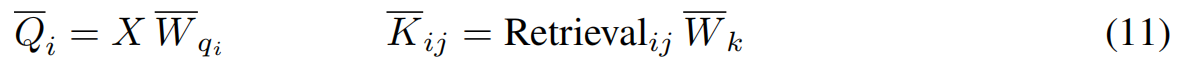
其中,参数 W ‾ q i ∈ R d × d r \overline{W}_{q_i} \in R^{d \times d_r} Wqi∈Rd×dr是 i i i索引的每个搜索的不同矩阵,与 W ‾ k \overline{W}_k Wk一起,用于驱动搜索和检索之间的配对。我们将矩阵 Q i Q_i Qi从 R d × d r R^{d \times d_r} Rd×dr传播到 R N × 1 × d r R^{N \times 1 \times d_r} RN×1×dr,并定义 K ‾ i ∈ R N × R × d r \overline{K}_i \in R^{N \times R \times d_r} Ki∈RN×R×dr如下:
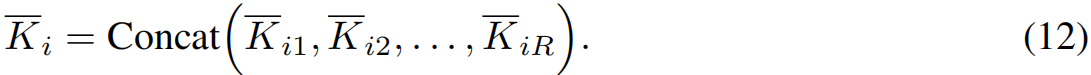
因此,通过这些检索query和key,每次搜索所需的实例化都是按
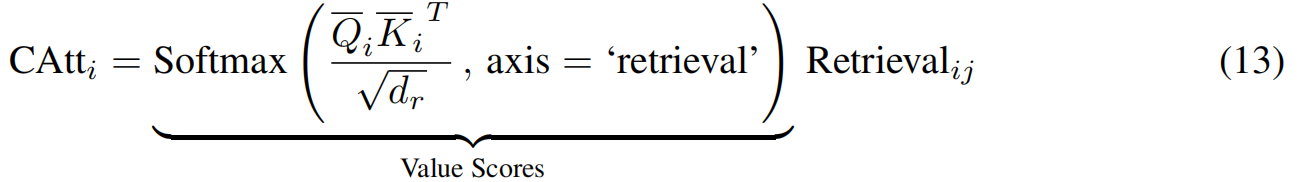
其中转置是在最后两个轴上。因此,对于每个搜索 i i i, softmax对所有可能的检索给出注意权重,并通过这种软注意机制实例化获胜检索。最后,类似于多头注意,这些并行搜索的输出是通过连接它们并通过一个线性网络来组合的
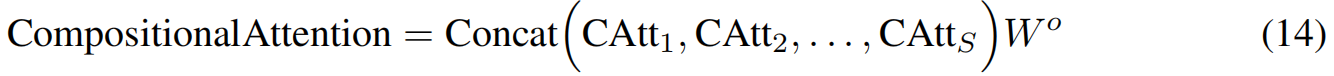
其中 W o ∈ R S d v × d W^o \in R^{Sd_v \times d} Wo∈RSdv×d。注意,在这个机制中,每次搜索的检索选择不是固定的,而是由 Q ‾ i \overline{Q}_i Qi和 K ‾ i \overline{K}_i Ki分别动态调节的。图2给出了计算图的可视化描述。
composition Attention允许模型具有:
(a) 不同的搜索次数和检索次数,分别为 S S S和 R R R;
(b) 每个搜索的共享检索次数的动态选择;
(c) S × R S \times R S×R(Search – Retrieval)对的表示能力。因此,这里强调composition Attention可以解开搜索和检索的纠缠,并解决多头注意的冗余。
3. 部分实验结果
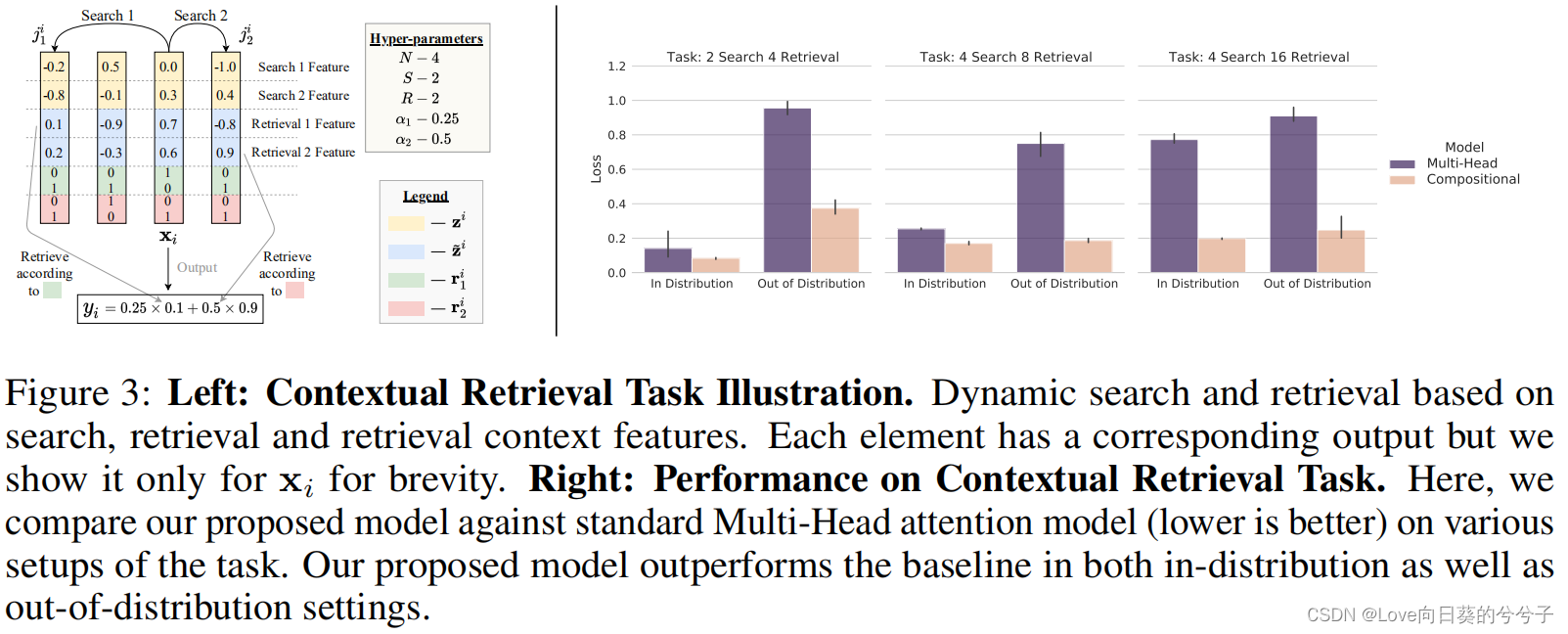
- 检索任务

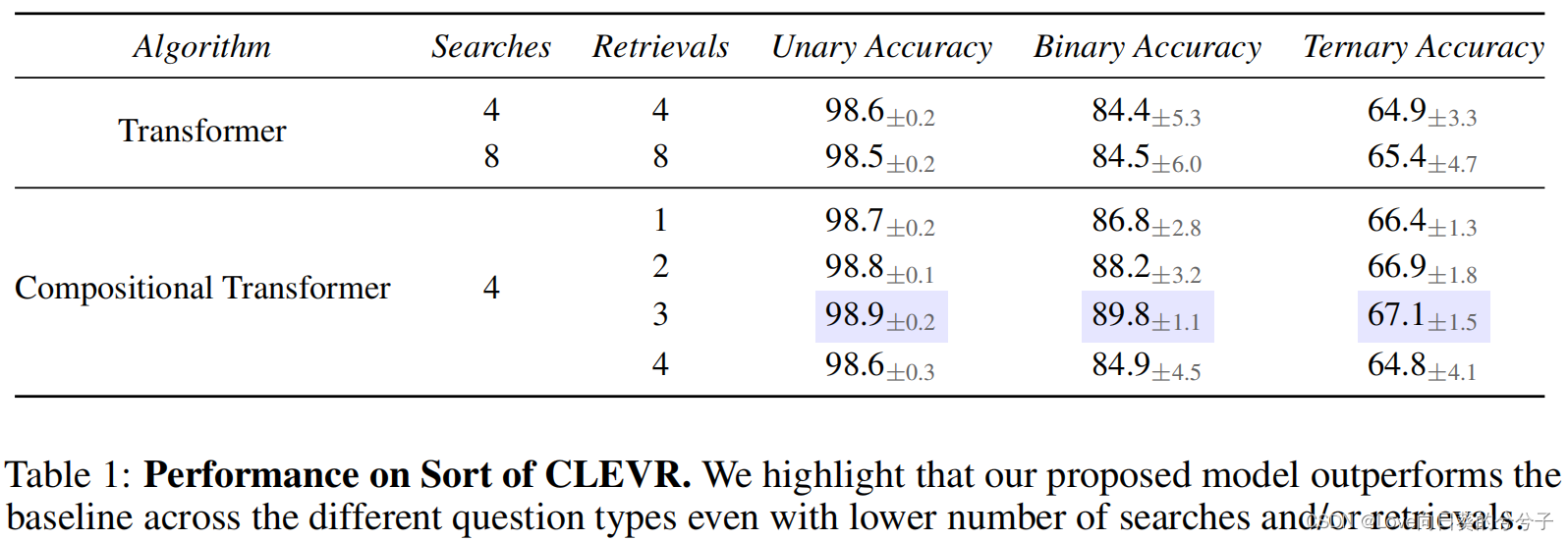
- 关系推理
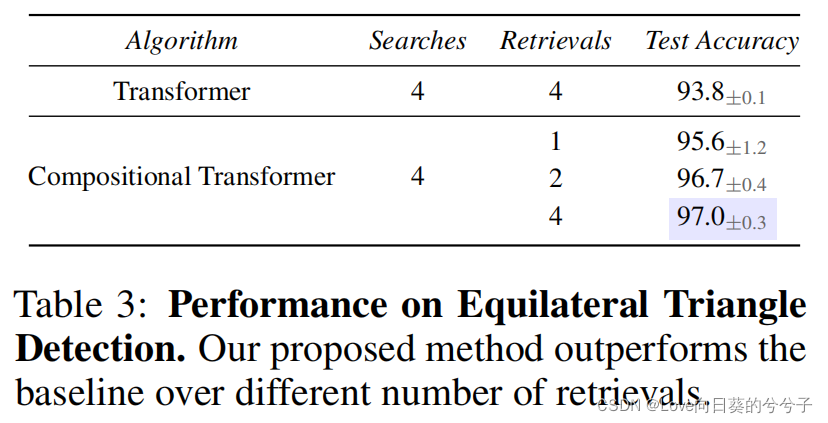
- 等边三角形检测
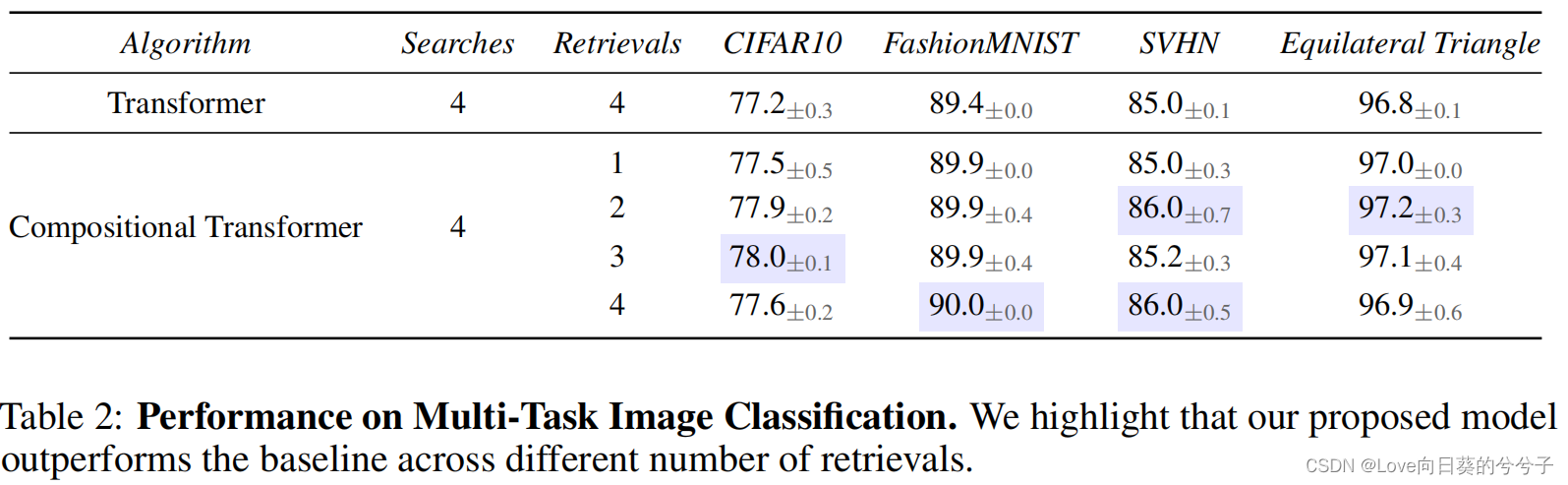
- 多任务图像分类
- ESBN任务中的逻辑推理

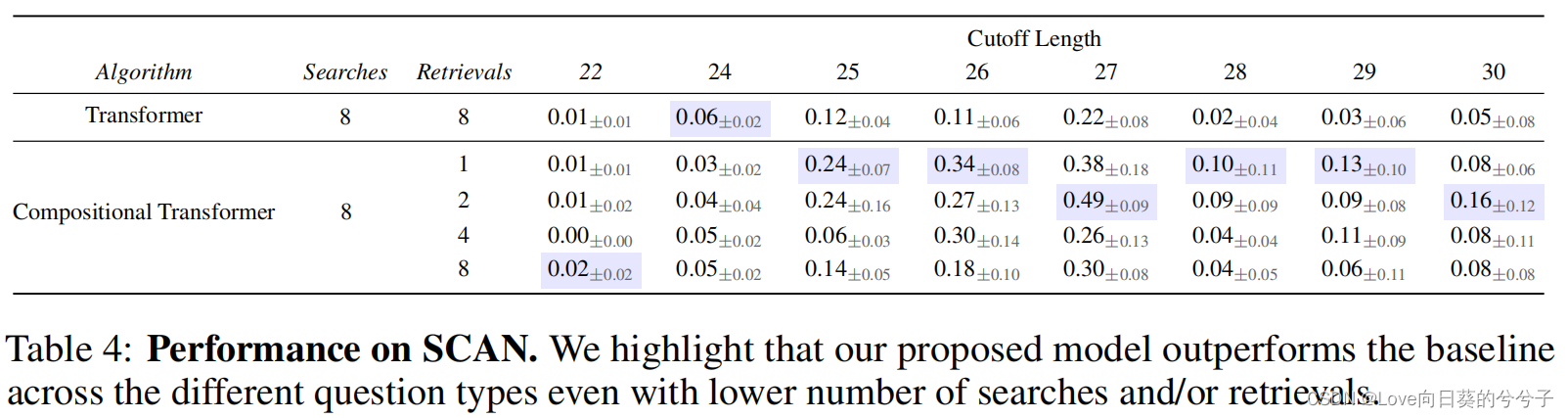
- SCAN数据集
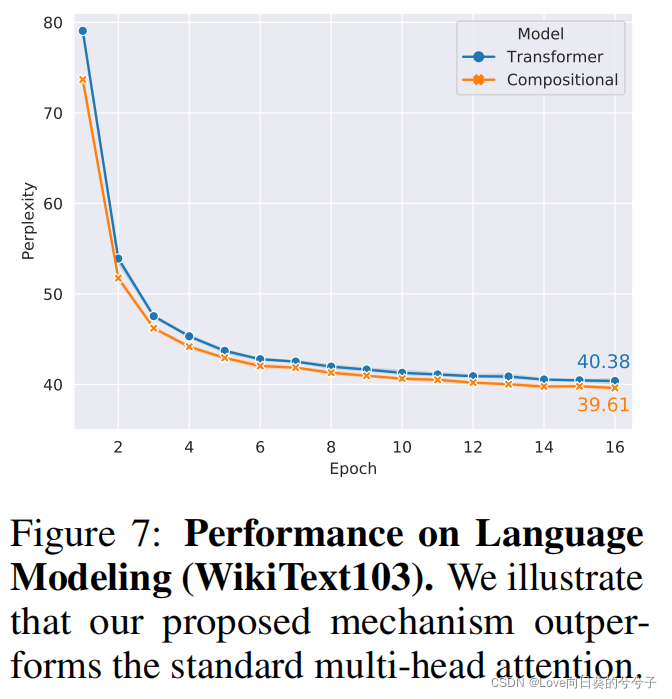
- 语言模型
4. 结论
1)在这项工作中,重新审视了multi-head attention,将其分解成了search和retrieval两步,并强调了其由于搜索和检索机制之间的刚性关联而存在的不足。
2)为了缓解这种刚性耦合阻碍参数的重用性,降低了模型的表达能力的问题,提出了一种利用value检索机制灵活组合搜索和检索的新机制。