
论文链接:https://arxiv.org/abs/2202.06709
代码链接:https://github.com/xxxnell/how-do-vits-work
1. 动机
多头自注意力(MSAs)技术在计算机视觉领域的成功已是不争的事实。然而,人们对MSAs的工作原理知之甚少。此外很多工作对MSA工作原理的分析只停留在其具有弱归纳偏置(weak inductive bias)和长距离依赖捕捉(long-range dependency)的能力。本文较为全面的对视觉Transformer的低层原理进行了分析和实验论证。
2. MSA和ViT特性
本篇论文总结了MSA和ViT的三大特性如下:
1)MSA提高了网络的精度,但是这种改善主要归因于训练数据的特异性(data specificity),而不是长距离依赖性。
2)MSA与卷积Conv呈现两种不同的操作形式,MSA是低通滤波器,而Conv是高通滤波器。二者是共为互补的。
3) MSA在模型特征融合阶段扮演了非常重要的角色,基于此,作者提出了一种新网络AlterNet,将每个stage末尾的Conv块替换成了MSA。AlterNet在大中小型数据集上的性能表现都超过了单纯的CNN模型和ViT模型。
3. 传统Transformer探究
视觉Transformer的核心部件Self-Attention可以被表示为:
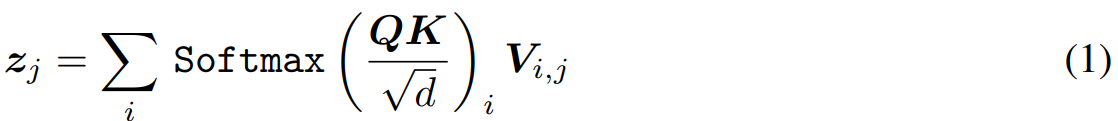
其中 Q Q Q, K K K和 V V V分别是查询、键和值向量,d表示查询和键向量的维度。 z j z_j zj是第 j j j个输出token。从卷积神经网络(convolutional neural networks, CNNs)的角度来看,MSAs是所有具有大型和特定于数据的核的特征映射点的转换,即,MSA可以看成是一种特殊的卷积变换,它作用在整个feature map上,具有大尺寸的核参数。因此,MSAs至少与卷积层(Convs)具有同样的表达能力,尽管这并不能保证MSAs会表现得像卷积层。
但是MSA的长距离依赖建模能力对于模型预测性能的提升,本文作者提出了反对意见,作者认为给予模型适当的距离约束可以帮助模型学习更鲁棒的表示,例如一些局部建模MSA的工作,CSAN和Swin Transformer都仅在小窗口内计算自注意力,不仅在小数据集上表现优异,而且在大型数据集例如Imagenet-21K上达到了更好的性能。基于此,作者提出了针对MSA和ViT的三个核心问题:
- 我们需要MSA中的哪些属性来更好的优化网络,MSA的长期依赖建模到底对模型优化起到了怎样的作用?
- MSA的操作与Conv有何不同?
- 如何协调使用MSA和Conv才能更好的发挥它们各自的优势?
4. MSA和ViT的问题分析
问题一:我们需要MSA中的哪些属性来更好的优化网络,MSA的长期依赖建模到底对模型优化起到了怎样的作用?
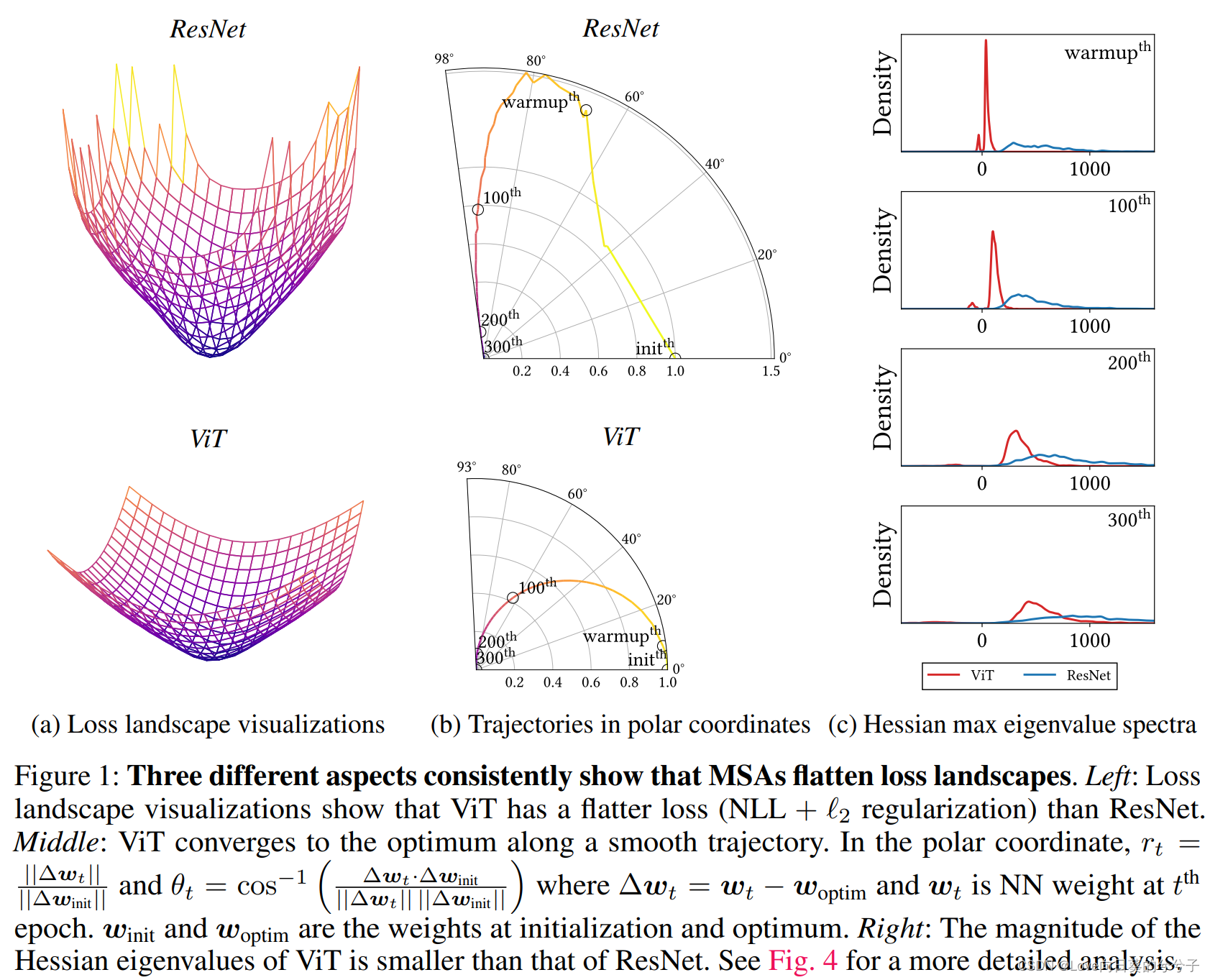
作者首先提出了各种证据来支持MSA是广义空间平滑。这意味着MSA提高了性能,因为其公式(1)是一个适当的归纳偏置。这个弱归纳偏置会干扰神经网络的训练。特别是,MSAs的一个关键特性是它们的数据特性,而不是长期依赖关系。MSA之所以能提升模型的整体性能,是因为它使损失平面变得扁平化,这有助于ViT的训练。 上图展示了ViT和ResNet损失函数的平面示意图,如图1所示,损失平面越平坦,模型的性能和泛化能力越好。
但是另一方面,MSA允许模型在接触数据时使用负Hessian特征值,这意味着MSA的损失函数是非凸的,这种这种非凸性在一般情况下会干扰神经网络的优化。这一说法也可以通过上图(c)进行证实,图(c)提供了模型训练阶段的Top-5 Hessian特征值密度,batchsize为16,可以看出,ViT具有非常多的负Hessian特征值,而ResNet只有少数,这种损失优化情况会扰乱网络的优化,尤其是在训练的早期阶段。但是在数据量非常大的情况下,这个缺陷会消失,图(a)通过使用滤波器归一化方法可视化得到的损失函数平面,表明ViT的平面相比ResNet更加平坦,这种趋势在边界区域更加明显。同样,在图(b)中展示着ResNet遵循不规则的优化轨迹,而ViT逐渐沿着平滑的轨迹收敛到最优值,这也说明了为什么ViT在大数据集上表现的比CNN好。
问题二:MSA的操作与Conv有何不同?
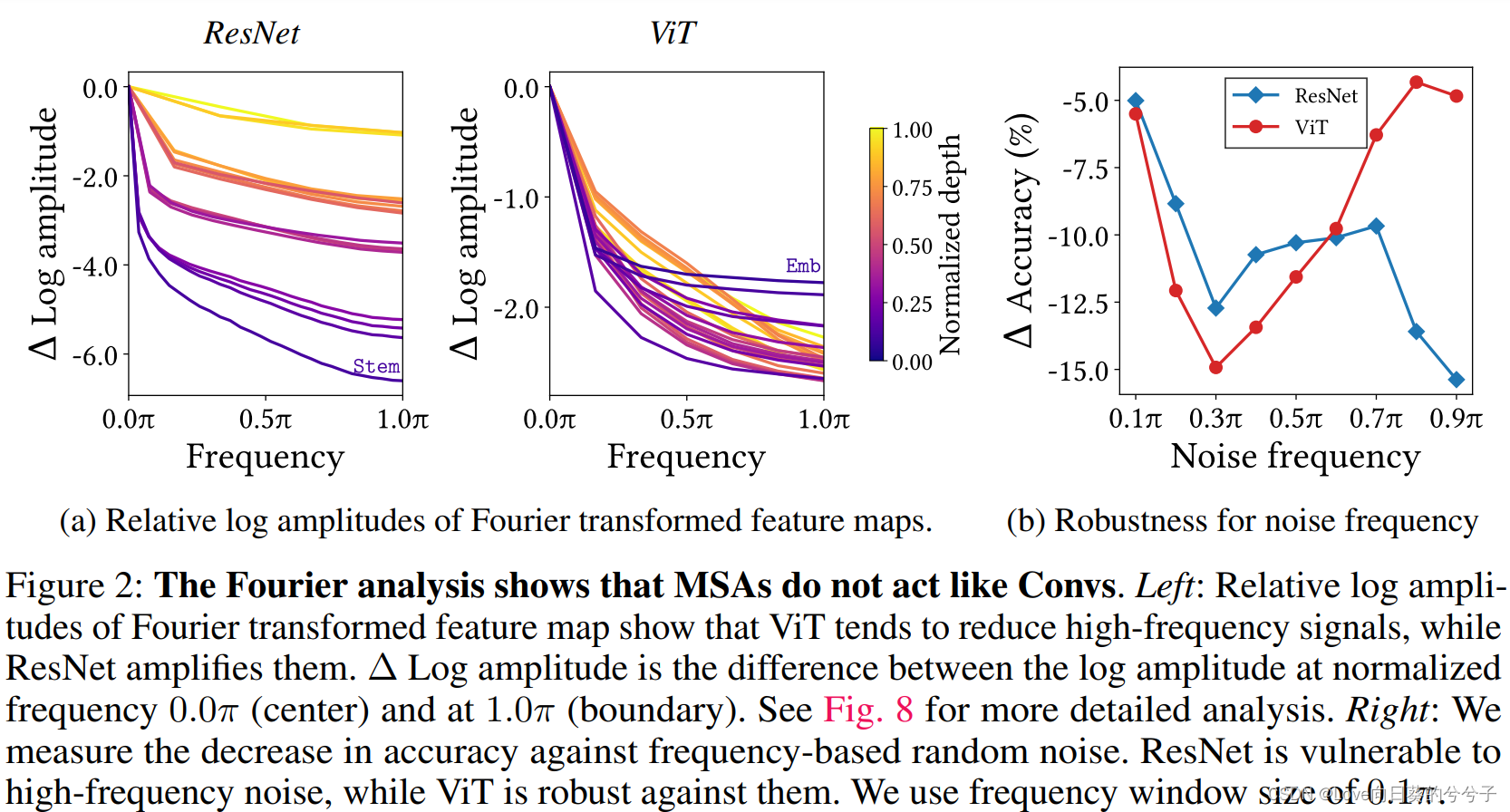
本文认为MSA和Conv的操作基本上呈现相反的效应,其中MSA是低通滤波器,而Conv是高通滤波器,MSA在空间上平滑了具有更高自注意力值的特征图区域,因此,其倾向于减少高频信号。为了支持这一论点,作者对MSA和Conv的特征图进行了傅立叶分析,结果如上图所示,其中图(a)的相对对数幅度表明,ViT倾向于减少高频信号,而ResNet会放大。图(b)展示了基于频率计算得到的随机噪声对模型准确率的影响程度,可以看到ResNet非常容易受到高频噪声的影响,而ViT对高频噪声具有一定的鲁棒性,因此将二者结合可以有效提升整体性能。
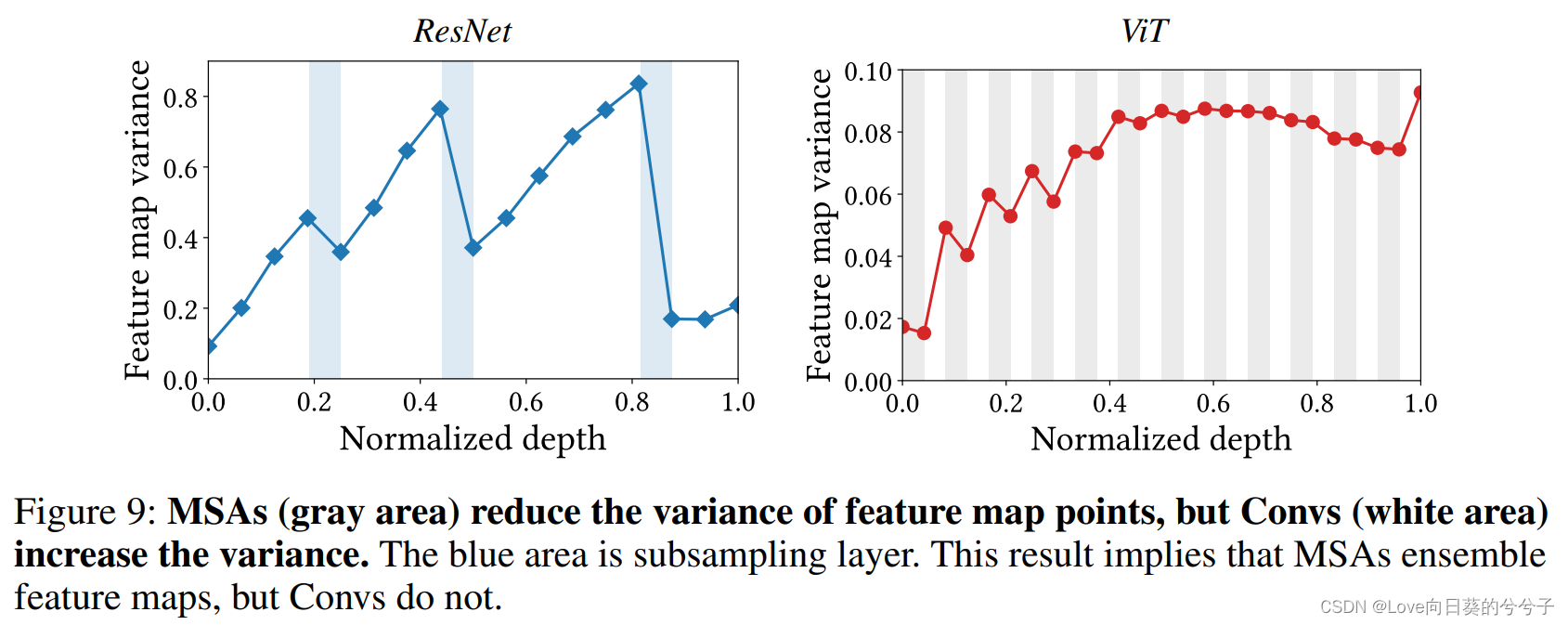
此外,作者还分析了二者在特征融合方面的差异,作者认为MSA操作可以有效的对不同层次的特征进行聚合,但是Conv不能。这是因为MSA具有平均化特征图的操作,这会减少特征图点之间的方差,进而对特征图进行集成,为了证明这一论点,作者做实验对ResNet和ViT的特征图的方差进行计算,实验结果如上图所示。从图中可以看出,MSA倾向于减少方差,相反,ResNet中的Conv和ViT中的MLP会增大方差。此外作者还观察到了两个特征图的方差演化模式:
- 随着网络层数的深入,方差会先在每个层中累积,随着深度的增加而增大。
- 在ResNet中,特征图方差在每个stage结束时达到峰值,因此可以通过在ResNet每个阶段的末尾插入一个MSA来提高ResNet的特征聚合能力。
问题三:如何协调使用MSA和Conv才能更好的发挥它们各自的优势?
作者在问题二的回答中认为MSA和Conv是互补的,因此在问题三中,作者提出了一种设计规范来将MSA和Conv进行组合,称为AlterNet,下图展示了AlterNet与其他两种组合形式的对比。
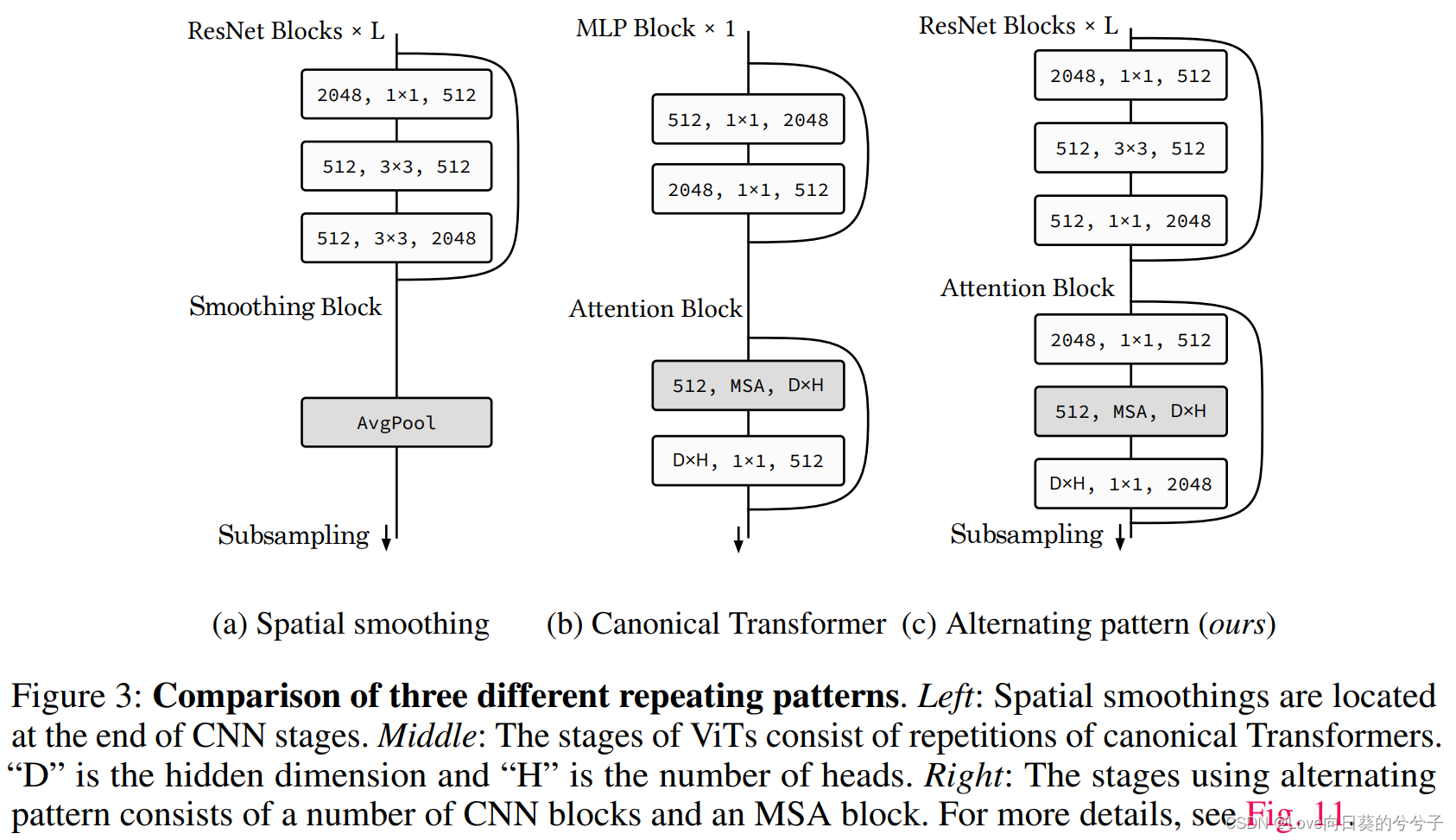
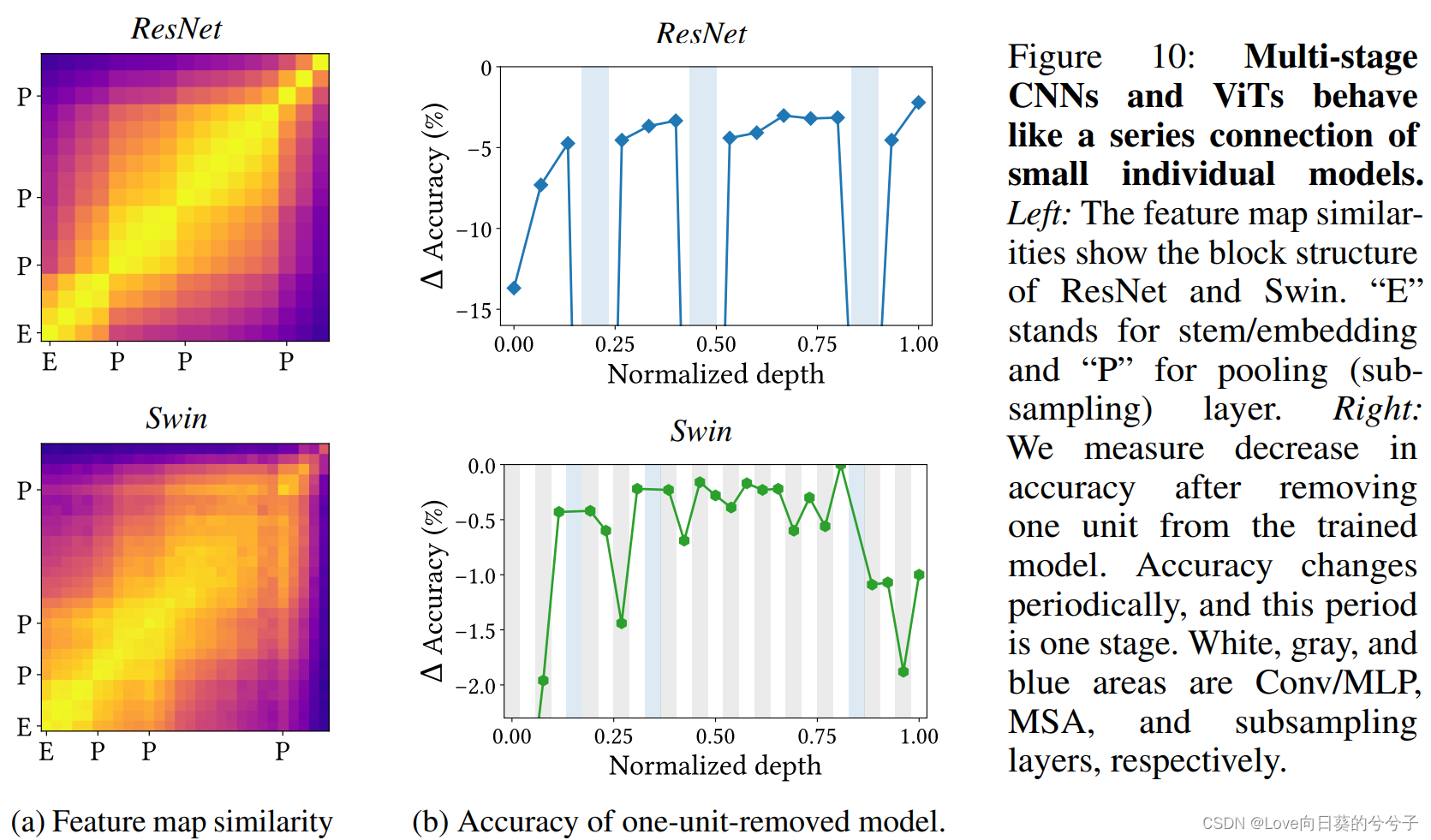
作者首先研究了目前流行的多stage神经层叠加架构的特性,并且设计了一种交替模式,即基于CNN的结构来堆叠MSA。作者通过实验证明,多stage神经层叠加得到的效果接近于单个模型,这在问题二特征图方差的分析图得到了验证,可以观察到,不管在ResNet还是ViT中,特征图方差的演变模式在每个阶段都会重复。下图也展示了ResNet和Swin Transformer在CIFAR-100上的特征相似性,在该实验中,作者使用mini-batch CKA方法来测量相似度。可视化结果显示,CNN的特征图相似性具有块结构,同样,多stage的ViT的特征图相似性也呈现出一定的块结构,但是在单stage的ViT中却没有这种现象,因此块结构应该是多stage结构的本身特性。
基于以上发现,作者假设MSA放置在网络stage结束的位置可以显著提升性能,而不是放置在整个模型的末尾。作者提出的MSA和Conv交替模式的设计规范如下:
- 在baseline CNN模型的末尾使用MSA替换Conv块。
- 如果添加的MSA块不能提高预测性能,就将之前stage末尾的Conv块继续替换为MSA块。
- 越在后stage的MSA块,给定的head参数和隐藏层维度应该越大。
网络模型AlterNet
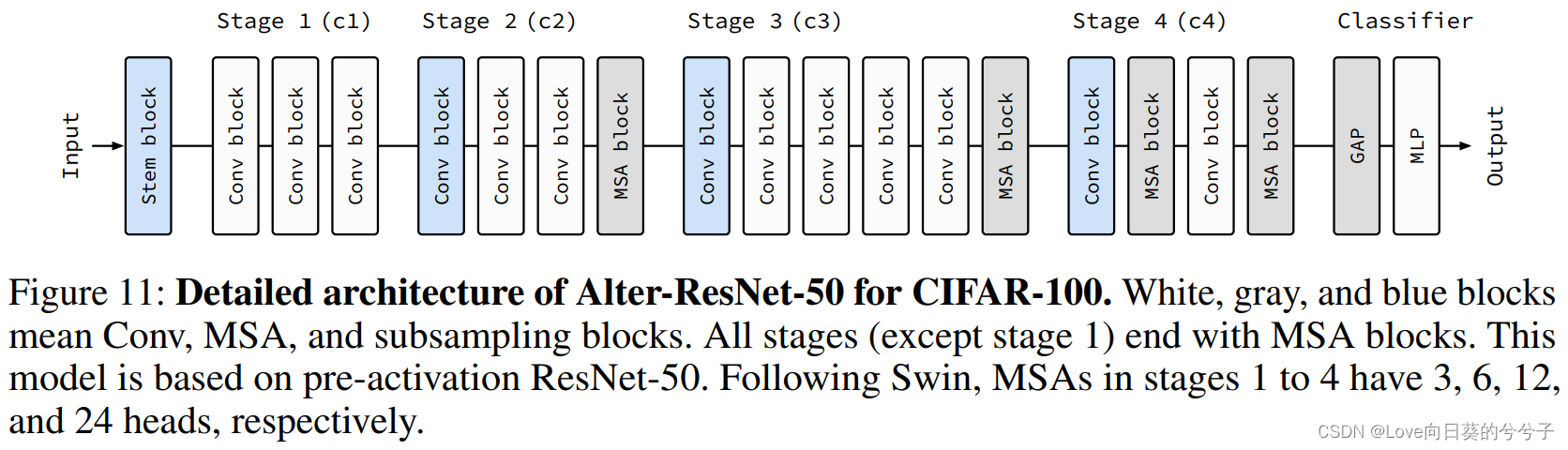
根据上述三条规范,作者提出了一个新的网络模型AlterNet,AlterNet通过调整MSA和Conv在整体模型中的占比来统一ViT和CNN。下图展示了基于ResNet-50的AlterNet模型结构。
下图展示了Alter-ResNet-50与其它基线模型在CIFAR-100的准确率和鲁棒性测试结果,由于CIFAR是一个小型数据集,因此CNN的性能优于规范的ViT,但是本文的Alter-ResNet-50可以看作是一个遵循设计规范的MSA模型,其在小数据集上的性能也优于CNN,这表明MSA操作可以对Conv操作进行补充和增强。

5. 结论
本文目前的工作表明,MSAs不仅仅是广义卷积,而是与广义卷积互补的广义空间平滑。MSA通过集成特征图和平滑损失平面来帮助神经网络学习更加鲁棒的特征表示。根据这些分析,作者保留了Conv和MSA本身的结构,并针对他们分别作为高通滤波器和低通滤波器的特性,提出了一系列的组合设计规范,以及复合网络AlterNet,AlterNet可以方便在现有模型中替换主干网络,用于其他视觉任务。本文的另一个关键贡献是,证明了MSA在特征融合方面的优势和特性,这有助于后续的研究者使用MSA集成特征图来改善下游任务的预测结果。