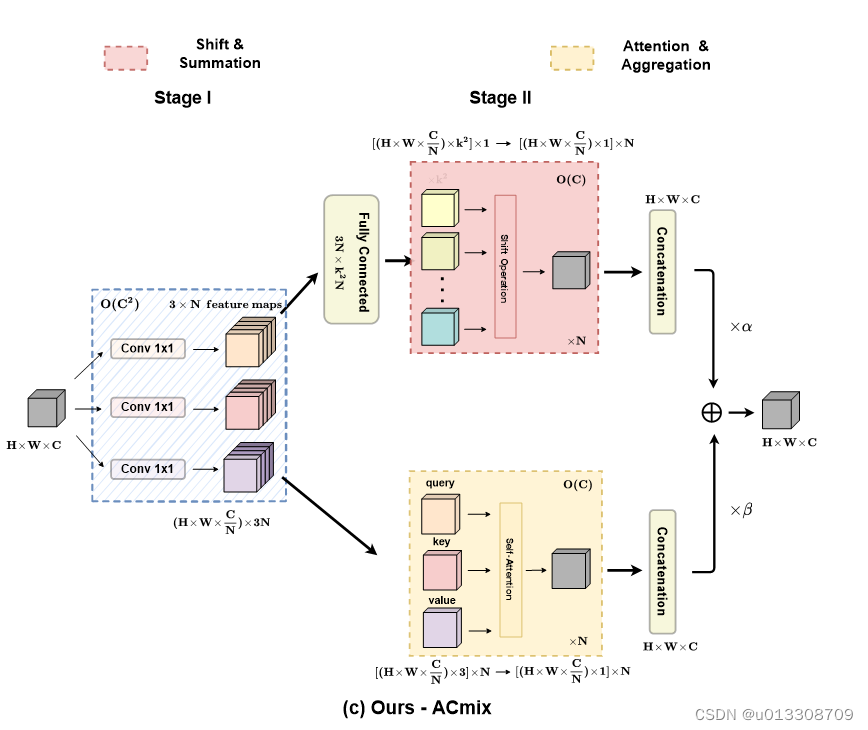
卷积操作和注意力机制都可以用来学习表征,两者之间存在根本关系。从某个意义说,这两个范例的大部分计算实际上用相同的操作完成。传统的 k × k \begin{array}{c} k\times k \end{array} k×k卷积可以被分解成 k 2 \begin{array}{c} k^{2} \end{array} k2个1×1卷积,移位和求和操作。然后,我们将查询、键和值在自我注意力模块中的投影解释为多个1×1卷积,然后计算关注权重和值的聚合。该混合模型既享受了self-Attention 和Convolution (ACmix)的好处,同时与纯卷积或自我注意力对应模型相比具有最小的计算开销。
ACmix包括两个阶段: 在第一阶段,输入特征通过三个1×1卷积进行投影,并分别重塑为N块,得到3×N特征映射的中间特征集。 在第二阶段,有自注意力路径和卷积两个路径。对于自注意路径,对应的三个特征映射作为查询、键和值,遵循传统的多头自注意模块。 对于核大小为k的卷积路径,采用轻型全连接层并生成 k² 特征图,同时进行移位操作和聚合。 最后,将两条路径的输出加在一起,强度由两个可学习标量控制: F o u t = α F a t t + β F c o n v \begin{array}{c} F_{out} = \alpha F_{att} + \beta F_{conv} \end{array} Fout=αF