论文链接:https://arxiv.org/pdf/2211.00639v1.pdf
目录
3 Behavioral Language for Online Classification
4 Discriminative power of BLOC
4.1 Characterizing individuals and groups
摘要
恶意行为者利用社交媒体抬高股价、影响选举、传播错误信息并煽动不和。为此,他们采用的策略包括使用不真实的帐户和活动。目前检测这些滥用行为的方法依赖于专门针对可疑行为而设计的特征。然而,这些方法的有效性随着恶意行为的发展而减弱。
为了应对这一挑战,我们提出了一种用于建模社交媒体帐户行为的通用语言。这种语言中的单词称为 BLOC,由代表用户操作和内容的不同字母表中的符号组成。该语言高度灵活,无需进行大量微调即可用于对各种合法和可疑的在线行为进行建模。
使用 BLOC 来表示 Twitter 帐户的行为,我们在检测社交机器人和协调不真实行为方面取得了与最先进的方法相当或更好的性能。
1 Introduction
社交媒体的广泛使用使它们成为不良行为者利用的主要目标。利用社交机器人 [18] 提高政治候选人 [41] 的受欢迎程度,通过传播虚假信息和阴谋论 [29, 24] 影响公众舆论,以及通过协调一致的活动操纵股票价格 [14, 39]被广泛报道。恶意行为者造成的威胁影响深远,危及民主 [44, 54]、公共卫生 [47, 1, 40] 和经济 [33]。作为回应,研究人员开发了各种工具来检测恶意的不真实帐户。
然而,我们正处于军备竞赛之中。随着平台提供新的检测方法和预防范机制,恶意行为者继续发展其逃避检测的行为。例如,考虑社交机器人的演变:在早期,垃圾邮件机器人很容易识别,因为它们通常缺乏有意义的个人资料信息和/或表现出幼稚的行为 [57, 30]。近年来,机器人帐户变得更加复杂。有些显示详细的个人资料,要么是从其他用户那里窃取的,要么是由深度神经网络生成的[36]。有些模仿人类行为并建立社会联系[9]。其他人则采取协调不真实行为等策略。1这种协调行为在单独检查时似乎是正常的,但为了实现某些目标而受到集中控制[39]。
这场军备竞赛催生了一系列更为复杂的检测方法[9, 34, 39]。这些方法的一个重要局限是,它们依赖于专门针对先前观察到的恶意行为而制作的特征[43]。这些特征可能无法很好地推广到其他可疑行为。例如,旨在检测复杂社交机器人的方法往往会过度关注协调行为,反之亦然 [55]。现有方法在面对新的恶意行为者时也会变得不那么有用,除非对特征进行相应的调整。
为了应对这一挑战,我们提出了在线分类行为语言(BLOC),这是一种表示社交媒体账户行为的通用语言。BLOC 词语由来自不同字母表的符号组成,代表账户的行为和内容。例如,图 1 展示了美国国家航空航天局(NASA)官方推特账号的一系列推文的可能表达方式。BLOC 语言具有很强的可扩展性,无需进行大量的微调,就能表示各种合法和可疑行为。

(图 1:@NASA 帐户的三条推文序列(一条回复、一条原始推文和一条转发)的 BLOC 字符串。使用动作字母表,序列可以用点分隔的三个单词 p.T.r 表示。使用内容字母表,可以用括号中的这三个单词 (Emt)(mmt)(mmmmmU t) 来表示。参见第 2 节。 3 详细信息。)
在本文中,我们表明,有意义的行为模式从这种表示中出现,促进了与社交媒体帐户分类相关的任务。为了证明 BLOC 的有效性,我们在社交机器人和协调行为检测任务以及之前专门为这两个任务设计的方法上对其进行了评估。据我们所知,BLOC 是唯一已应用于这两项任务的现有表示形式。尽管基于 BLOC 的方法使用的特征比最先进的方法少得多(这使得它们更加高效),但它们产生了更好或相当的性能。
2 Related work
我们至少可以从两个维度来描述不真实的在线行为:自动化和协调。
账户可以是自动化的但独立的,或者是协调的但由人类密切管理的,或者既是自动化的又是协调的,以及介于两者之间的一切。下面我们概述了旨在检测这些维度上的不真实行为的研究。请注意,并非所有自动或协调的行为都一定是不真实或恶意的。例如,一些自我声明的机器人是无害的,甚至是有用的;一些草根运动可能会利用协调来促进有益的社会运动。
2.1 Automation
社交媒体账户自动化的行为范围一端是人类行为,另一端是类似机器人的行为。介于两者之间的是“机器人”[8, 7],它们在人类和机器人行为之间循环。
人们已经提出了各种机器学习方法来识别特定类型的自动化行为。这些方法通常利用一些特征的组合,例如社交网络结构、内容/个人资料特征和时间模式[18]。
一些研究人员重点研究了人类在线行为的特征。伍德-多蒂(Wood-Doughty)等人对一百万个账户进行了研究,探索不同的人口群体如何使用 Twitter [53]。该研究基于这样一个假设,即用户行为会受到信息个性化、时间信息、位置共享、用户互动和设备等指标的影响。He 等人提供了一种识别 Twitter 上五类行为的方法:个人行为、新闻信息传播行为、广告和促销行为、自动/机器人行为以及其他活动 [25]。
研究人员还研究了人类在其他社交媒体平台上的行为。Maia 等人将 YouTube 用户表示为由上传次数、观看视频、访问频道、系统加入日期、年龄等词汇组成的特征向量[32]。然后,他们将用户聚类为预先设定的类别,如小型社区成员、内容生产者和内容消费者。
Benevenuto et al. 研究网络的行为的通过分析访问四个社交网络(Orkut、MySpace、Hi5 和 LinkedIn)的超过37千名用户的点击流数据 [3]。
自动化的另一端是社交机器人[18]。文献的一个共同主题是建立区分机器人账户和人类账户的算法[9],这就要求首先描述账户的特征。从社交媒体平台上获取的丰富信息可以从多个不同维度对账户进行描述。根据目标账户的不同类型,现有方法使用了来源信息[56]、帐号[57, 12, 10]、行为[34]、社交网络[4]和时间特征[34]。
另一种常见方法是在同一模型中结合不同维度的账户特征[30, 15, 52, 22, 55, 43]。例如,Botometer 2 是一个公开可用的监督机器学习系统,它从 Twitter 帐户的信息、内容、情感、社交网络和时间活动中提取了 1000 多个特征。
数字DNA(DDNA),由Cresci等人提出。 [12, 10],是与 BLOC 最相似的方法。 DDNA 将每个帐户编码为一对分别代表操作和内容的符号串。然后,它将具有长公共子字符串的帐户视为机器人。虽然 BLOC 类似地使用符号序列来编码动作和内容类型,但它与 DDNA 有很大不同,即捕获停顿。 BLOC 可以将字符串分割成单词,这些单词表示由停顿分隔的动作序列或内容符号。单词可能会捕捉到不同的行为模式,而没有长时间停顿可能会揭示自动化行为。因此,帐户可以表示为词向量,从而允许进行字符串匹配之外的相似性度量。另一个区别是 DDNA 截断了重复。例如,单个 U 字符代表一个或多个 URL,而 BLOC 可以捕获重复项(例如 U U U )以强调不同的行为。这可以帮助检测重复行为,例如长序列的转发,这是某些不真实帐户的典型特征。
2.2 Coordination
随着时间的推移,恶意社交机器人变得越来越复杂,变得更加有效且更难以检测。在某些情况下,研究个人账户还不够。一组不真实的帐户可以由单个实体进行协调,无论它们的行为是人为控制的还是自动化的。这些复杂的欺骗只能通过群体层面的观察来发现[9]。这导致了多项研究工作来检测恶意协调行为。
虽然个体机器人检测的目的是将个体人类帐户和类机器人帐户分开,但协调检测涉及将可疑相似的帐户聚类成组[39]。相似性度量的适当定义是主观的,并且在不同的研究中有所不同。一个常见的选择是关注时间维度,直接比较不同账户的动作时间序列 [6, 27] 或使用时间点过程建模 [45]。其他类似措施侧重于重复或部分匹配的文本 [2, 51] 或共享转发 [37]。一些方法专注于内容的特定组成部分,例如嵌入链接、主题标签和媒体[39,28,20,21,51]。帐户资料信息也可用于识别类似帐户[17]。最后,可以根据不同的标准聚合相似性度量[31]。
这些方法通常提取针对特定可疑行为模式的账户特征[39]。BLOC 将行为信息编码为特征,可用于计算相似性,而无需预先确定目标行为。因此,BLOC 用途广泛,可用于描述各种行为。接下来,我们将深入介绍 BLOC。
3 Behavioral Language for Online Classification
BLOC 的核心组成部分是两个字母的集合:动作和内容。每个都由一组代表活动或特征的符号组成。总的来说,这些字母表对可用于为各种任务构建模型的行为进行编码。
BLOC 有多个语言参数,如表 1 所示。这些参数值的不同组合对应于不同的语言和表示形式。下面我们详细讨论这些参数,并指出基于大量实验的推荐值。在第 4 节和第 5 节中,我们将不同的 BLOC 表示应用于各种任务。

3.1 BLOC alphabets
让我们说明如何为任意 Twitter 帐户 @Alice 生成从字母表中提取的 BLOC 字符串。但请注意,BLOC 与平台无关。
3.1.1 Action alphabet
动作字母表包括两组动作和暂停符号。一个行动符号代表一个账户发布的一个帖子,其符号概述如下:
T:发布消息 P:回复好友 p: 回复非好友 π: 回复自己的帖子 R: 转发好友的帖子 r: 重新分享非好友的帖子 ρ: 重新分享自己的帖子
例如,字符串 T pπR 表示 @Alice 发布了一条推文,然后回复了一位非好友,接着回复了自己,最后转发了一位好友。
暂停符号表示连续动作之间的停顿。停顿为操作提供了额外的语境。例如,停顿时间很短(如不到一秒)或停顿很有规律的动作可能表示自动化[19]。
首先,我们将 ∆ 定义为两个连续动作之间的时间间隔。根据参数 p2,我们有两种可能的暂停字母表,它们是由将 ∆ 值映射到符号的函数定义的。函数 f1 的定义如下

其中 p1 是会话分隔阈值。因此,会话被定义为停顿时间短于 p1 的连续动作的最大序列。会话很重要,因为它们为标记 BLOC 词提供了自然的词边界(见第 3.2.2 节)。我们建议在公式 1 中使用一分钟或更短的 p1 值。
举例说明,让我们用 f1 和 p1 = 1 分钟来标注 @Alice 的一系列操作(T pπR)。假设爱丽丝在发布第一条推文和回复非好友之间停顿了 2.5 分钟,然后过了 50 秒才回复自己的推文,最后等了 3 天才转发好友的推文。由此得到的 BLOC 字符串为 T.pπ.R,表示三个会话,其边界用圆点标出。
另一种停顿字母表为长停顿分配不同的符号,以获得更好的粒度。我们将时间分解为对数刻度,以表示各种停顿,例如小时、天、周,将 f2 定义为:

以上面的例子为例,在 p1 = 1 分钟的条件下,@Alice 使用 f2 暂停符号的操作串为![]() 。
。
3.1.2 Content alphabets
内容字母表提供了帖子的词汇特征——是否包含文本、链接、主题标签等。与动作字母表不同,单个社交媒体帖子可以包含以下列表中的多个内容符号:
t: 文本 H: 标签 M: 提及朋友 m: 提及非朋友 q: 引用他人的帖子 φ: 引用自己的帖子 E: 媒体对象(例如图像/视频) U : 链接(URL)
举例说明,假设 @Alice 的第一条推文只包含文字;她回复给一位非好友的推文包含两张图片和一个标签;她的自我回复涉及一位好友并包含一个链接;最后她转发了一条涉及非好友的推文。由此产生的内容字符串取决于 p3 参数。如果不使用会话,则每个操作对应一个单独的内容词:(t)(EEH)(U M )(m) 。在这里,回复非好友(EEH)和自我回复(U M)的内容是分开的,尽管它们是同一个会话的一部分。通过会话,我们可以得到 (t)(EEHU M )(m)。请注意,括号将内容词分开,词内内容符号的顺序是任意的,并在实现中确定。
3.2 BLOC models
BLOC 字符串可用于为在线行为特征描述、僵尸检测和协调检测等任务建立数学模型。可能的模型类别包括马尔可夫链和向量空间。
3.2.1语言模式
建立 BLOC 账户模型的一种简单方法是马尔科夫链。模型中的每个状态代表一个 BLOC 符号,从状态 st 到状态 st+1 的过渡链路量化了符号 st+1 紧跟符号 st 的概率 P (st+1|st)。对于每个账户,我们可以执行与马尔可夫链相关的多种随机操作。例如,我们可以通过计算![]() 来预测账户的下一个操作(如推特、分享),或者估算账户产生一系列操作的可能性
来预测账户的下一个操作(如推特、分享),或者估算账户产生一系列操作的可能性![]() 。
。
例如,可以使用深度学习技术[26]训练一个更通用的语言模型,以生成 BLOC 符号序列。
3.2.2 Vector models
我们可以采用深度学习方法,如 word2vec [35],将 BLOC 字符串嵌入向量表示中。但是,抽象向量空间无法从 BLOC 符号的可解释性中受益。或者,我们可以先将 BLOC 字符串标记为单词,然后直接使用这些单词作为向量空间维度,从而获得向量表示。
根据参数 p4(表 1),可以使用 n-gram 或 pause 两种方法之一进行标记化。n-gram 方法通过在 BLOC 字符串上滑动一个 n 大小的窗口来生成固定大小为 n 的标记。在 n = 2 的情况下,我们生成的双语法词汇包含两个符号的单词。例如,给定动作字符串 T pπ.r 和 BLOC 内容字符串 (t)(EH)(U )(mm)(n = 2),我们会得到一组单词 {T p, pπ, π., .r, tE, EH, HU , U m, mm}。
停顿法利用停顿将 BLOC 动作串分成长度可变的词。除了作为单词边界标记外,停顿符号还作为单符号单词包含在词汇中。对于内容字符串,单个句子标记单词边界:同一句子中的所有符号构成一个单词。每个词内的符号可根据参数 p5 按字母顺序排序。为了说明不进行排序的暂停标记法,在给定相同的 BLOC 操作字符串 T pπ.r 和 BLOC 内容字符串 (t)(EH)(U )(mm) 的情况下,我们可以得到词集 {T pπ, ., r, t, EH, U, mm}。
停顿标记化通常会产生长词,例如图 2 中半机械人账户中的 13 个符号词 πππππT T πππππ 。当多个连续动作之间的停顿短于 p1 时,就会出现长词,这意味着动作是连贯进行的,通常表示自动化。例如,rrrrr 和 rrrrrr 之间的区别往往并不重要,因此我们可以在限制之后截断长词,而不是在词汇表中将两者作为单独的词来表示。例如,设置 p6 = 4 就可以截断重复四次或四次以上的字符。单词 rrrr、rrrrr 和 rrrrrr 都将被 rrrr+ 代替。

(图 2:人类、半机械人和机器人 Twitter 帐户的 BLOC 行动字符串(p1 = 1 分钟)图解,显示了这些个体的一些行为差异。如果使用停顿对字符串进行标记,人类账户的单词最短(平均长度为 1.35,而机器人账户为 3.88,机器人账户为 4.0),并且以孤立的转发和回复为主。半机械人账户(我们创建它的目的是发布新闻更新的线程)既表现出人类行为(孤立的帖子),也表现出机器人行为(线程突发)。机器人账户主要以转发为主。)
4 Discriminative power of BLOC
BLOC 让我们可以研究不同粒度级别的行为。我们可以研究不同类别的帐户,例如人类帐户与机器人帐户。或者我们可能会研究一个类别中不同类型的个人帐户,例如政治帐户与学术帐户或垃圾邮件机器人与自我声明的机器人。在本节中,我们通过描述个人帐户和帐户组的行为(无论其类标签已知还是未知)来演示这种多分辨率方法。
4.1 Characterizing individuals and groups
图 2 展示了三个账户之间的行为差异:一个属于记者的人类账户;一个由作者之一手动或使用软件脚本发布新闻更新的半机械人账户;以及一个由 Mazza 等人[34]识别的垃圾邮件机器人账户。这些账户由各自的 BLOC 操作字符串表示。我们观察到了多个不同点。首先,当我们将这些字符串标记为由停顿分隔的单词时,人类记录的单词最短,大多为单个符号的单词(如r, T, p)。这反映了人类在两次发帖之间倾向于休息的事实。其次,机器人账户中的人类子字符串字数较短,其次是突发创建的机器人子字符串。第三,机器人账户倾向于通过转发(例如,rrrrrrrrrrr)而不是创建新内容来放大内容。
让我们把重点转移到研究账户组上。图 3 展示了六个不同数据集(见表 2)中同等数量的机器人和人类账号的 BLOC TF-IDF 向量的主成分分析(PCA)。我们观察到,图中左列的机器人和人类账号比右列的账号表达了更多不同的行为模式。

(图 3:来自六个数据集(包括人类和机器人)的账户 BLOC TF-IDF 向量的二维 PCA 投影(参见表 2):(A) cresci-17,(B) botometer-feedback-19,( C) cresci-rtbust-19、(D) cresci-stock-18、(E) varol-17 和 (F) gilani-17。从每个数据集中,我们选择相同数量的机器人(橙色)和人类(蓝色)帐户。我们使用少数类别中的所有帐户,并从多数类别中抽取相同数量的帐户。维恩图显示了所显示的机器人和人类帐户的前五个暂停分隔的 BLOC 单词。)

(我们的机器人检测评估中使用的带注释的数据集。对于每个数据集,我们报告描述它的参考文献以及当前评估时仍然活跃的帐户数量)
因此,左栏账户的共同词较少,更容易分离。例如,图 3A 中的机器人和人类账户都推送纯文本内容 (t),但机器人账户更常使用标签 (Ht)。在图 3C 中,机器人通过大量转发(rrr、rrr+)来放大内容,这与人类创造原创内容(T )不同。在图 3E 中,机器人分享更多外部链接(U ),而人类则倾向于参与对话和评论(p, q)。
在图 3B 中,机器人和人类表达了相似的行为特征:两类人都有相同的五大关键词。在图 3D 和图 F 中,机器人和人类共享五个热门词汇中的四个。在图 3D 和图 F 中,机器人账户更倾向于放大内容(rrr)和链接到外部网站(U t),而相应的人类账户则更倾向于参与对话(p)。总之,该图表明,在不同的数据集中,人类所表现出的行为往往是一致的,而机器人则根据其创建目的有不同的行为。这些发现与之前基于临时特征的分析结果一致[43]。BLOC 表示法非常强大,可以捕捉到这些行为之间的显著差异。
4.2 Behavioral clusters
当行为类别标签不可用时,我们可以以无监督的方式表征在线行为,使用 BLOC 根据行为相似性对帐户进行聚类。
我们分析了 CoVaxxy 项目3 在 2021 年 1 月 4 日至 9 月 30 日期间收集的推文,该项目研究了网络错误信息如何影响 COVID-19 疫苗的接种[40]。数据集[16]由超过 2 亿条关于 COVID-19 和疫苗的英文推文组成,由超过 1700 万个账户发布。收集到的推文包含 76 个关键词和标签,涵盖了各种中性(如 covid)、支持疫苗(如 getvaccinated)、反疫苗(如 mybodymychoice)和阴谋论(如 greatreset)话题。
鉴于数据集中存在大量账户,且配对比较的成本为二次方,我们将重点放在每月最活跃的一千个账户上。我们根据账户发布推文的天数来定义活跃度;为了打破并列关系(尤其是每天都活跃的账户),我们使用了账户在收集期间发布的推文总数。
我们采用了一种基于网络的三步法来识别具有高度相似行为的账户群。首先,我们为每个账户生成 BLOC TF-IDF 向量,使用停顿来标记单词,不对符号进行排序,并截断单词(p6 = 4)。其次,我们计算了 1,000 个向量之间的余弦相似度。我们只将相似度至少为 0.98 的节点(账户)连接起来,并删除单个节点,从而构建了一个网络。这一阈值确保了对具有可疑高相似度的账户的关注。第三,我们采用Louvain方法识别社区[5]。每个月(一月至九月)都会应用此程序,以生成九个行为相似性网络,该网络由具有高度相似性的帐户集群组成。
图 4 显示了 163 个已识别群组中的 24 个。图中,一个点代表一个聚类,该聚类位于代表其平均行为多样性和平均自动化得分的坐标轴上。

(图 4:24 个具有高度相似行为的帐户社区的平均行为多样性与平均自动化(参见文本)。每个社区都由一个点表示,根据手动分类进行着色(见正文)。通过可视化相应的子网来突出显示一些选定的社区,其中节点大小和深色分别代表程度和推文数量)
对于单个账户,我们通过其 BLOC 字符串(标记化前)的熵来衡量其行为的多样性。我们通过账户使用 Twitter API 发布信息的次数来估算账户的自动化程度。用户必须创建一个应用程序才能使用 Twitter API,Twitter 数据包括一个 "用户代理",用于识别应用程序。一些用户代理值对应于 Twitter 原生应用程序(TweetDeck、Twitter for Advertisers、Twitter for Advertisers(传统)、Twitter for Android、Twitter for iPad、Twitter for iPhone、Twitter for Mac、Twitter Media Studio、Twitter Web App 和 Twitter Web Client)。
虽然原则上可以编写软件来控制本地应用程序,但我们假定这些应用程序中的绝大多数都是手动操作的。同样,我们假定非本地应用程序表明使用了 Twitter API,因此很可能是自动化的,尽管其中一些可以手动操作。熵和自动化得分是每个群组中账户的平均值。图 4 中的聚类沿着自动化轴线被很好地区分开来,这表明人类账户和机器人账户之间有很强的区别。
我们手动检查了图 4 中的集群来描述主要行为,总结为以下几组。每个簇编号都有一个后缀,指示观察它的月份。在图 4 中,每组中的所有簇都具有相同的颜色。
巨大的连接组件(蓝色):集群 3-Sep 包括自动化分数低和行为多样化的帐户。这些可能是合法用户,他们大多转发并偶尔发布推文,并有正常的停顿。每个月都会出现类似的大型组件。
疫苗供应/预约机器人(橙色): 4 月 12 日群组包括 12 个自我标识的机器人账户,它们跟踪美国各城市的疫苗供应和预约情况,如 @DCVaxAlerts 和 @FindAVac Austin。这些账户发布了诸如 "检测到新的可用预约!- 提供商: CVS Pharmacy - City: 阿拉莫高地 - 注册链接:www.cvs.com/immunizations/ covid-19-vaccine..." 他们创建的长篇推文主要由 URL 和文本组成。总体而言,这些账户发布的内容最多。同样,1 月 17 日群组包括两个疫苗预约机器人(@kcvaccinewatch 和 @stlvaccinewatch),它们创建了推文线程。7 月 13 日群组包括 @CovidvaxDEL,一个印度新德里的疫苗预约状态机器人;以及 @ncovtrack,一个发布各国疫苗统计数据的机器人。
发布新闻的帐户(绿色): 4 月 14 日、1 月 16 日、4 月 20 日和 2 月 22 日群组包括许多账户,它们大多每小时发布链接到新闻网站的推文,如 @canada4news 和 @HindustanTimes一些账户由 @Independent 和 @guardian 等国际新闻机构拥有。
内容放大,可能是僵尸账户(紫色):5 月4日,包括一对没有创建任何内容的账户;它们重复转发的推文大多相同。5 月19日包括由同一自我识别开发者创建的自我识别机器人。这些机器人 @EdinburghWatch 和 Glasgow Watch 分别转发来自格拉斯哥和爱丁堡的随机内容。
- 错误信息分享和本地新闻账户(白色): 2 月 24 日的 Cluster 包括由 ussanews.com 拥有的 @USSANews,根据 factcheck.org 的资料,这是一个错误信息网站。该账户发布的链接标题如下 "我不接种疫苗的 31 个理由"。同一集群还包括 @abc7newsbayarea,一个合法的洛杉矶新闻机构的账户。这两个账户大多发布多条带图片的推文,每条推文之间的停顿时间都在一小时以内
垃圾机器人(红色): 3 月 10 日、4 月 11 日和 8 月 23 日的群组包括重复发布内容的账户。3 月 10 日群组中的账户重复使用 7 个或 13 个标签链接到各自的博客。4 月 11 日群组中的账号发布信息,招揽他人关注某个特定的账号。8 月 23 日群组中的两个账户重复发布了相同的支持疫苗信息,分别为 133 次和 72 次。、
- 协调机器人(黑色): 5 月 21 日群组中的三个账户没有创建任何内容;他们分别转发了同一账户的信息 1,004 次。在 2021 年 5 月的第一周,它们的 BLOC 字符串的前 44 个字符是匹配的。同样,群组 15-5中的账户没有创建内容,但总是转发由多个商业账户组成的相同集合,宣传各种商品。3 月18日包括一对互相转发 313 次的账户。
对疫苗持不同立场的各种低自动化账户(黄色):最后,图 4 还展示了支持疫苗的账户集群(5 月 1 日和 1 月 2 日的集群)、反对疫苗的账户(5 月 1 日和 1 月 6 日的集群) - 4 月、3 月 7 日和 5 月 8 日),或两种情绪的混合(集群 9 月 - 6 月)
5 Evaluation
在本节中,我们评估 BLOC 模型在 Twitter 上的机器人和协调检测任务上的性能。我们实验中使用的 BLOC 代码和数据集是可用的 [38]。
5.1 机器人检测
机器人检测任务涉及将可能由人类用户操作的帐户与可能由自动化操作的帐户分开。这是一项具有挑战性的任务,因为两类账户的行为是异构的且随时间变化的.
5.1.1 Methods
评估中使用的 BLOC 语言参数如下:p1 = 1 分钟,p2 = f2(Δ),p4 = 双语法(表 1)。其他参数不适用于双语法标记化。我们为每个有注释的 Twitter 帐户提取了 BLOC 动作和内容双元组。这样就得到了 197 个双元组。这些双元组可用作任何机器学习模型的特征。我们获得了每个账户的 TF-IDF 特征向量,并用它们来训练随机森林分类器。
我们将 BLOC 的性能与三个基准模型进行了比较: Botometer-V4(本文撰写时 Botometer 的当前版本)[43] 和两种基于 DNA 的方法,即 DDNA [12, 10] 和 DNA-influenced [23]。之所以选择后者,是因为它们与 BLOC 有某些相似之处。
Botometer-V4 使用了 1,161 种不同的特征,这些特征可分为六类,分别侧重于不同的账户特征。例如,用户档案特征是从用户档案中提取的,如好友和关注者的数量。时间特征测量帖子的时间模式,如频率和时间。在已部署的系统中,一个集合中的不同分类器会对不同类型的账户进行训练,然后这些分类器通过投票得出最终的机器人得分[43]。在此,为了比较 BLOC 与 Botometer 特征的表示能力,在其他条件相同的情况下,我们使用用于训练 Botometer-V4 的相同特征训练了一个单一的随机森林分类器。
如果账户共享代表行为和内容的长序列符号,数字 DNA 就会将其归类为机器人。Cresci 等人[10]提供了他们的 Python 代码[42],该代码封装了最长公共子串(LCS)算法的 C 语言实现。我们修改了代码,以实现作者描述的方法。该方法从训练数据中得出最大公共子串长度。然后,利用该长度确定测试数据中具有相同长度最大公共子串的账户集合。这些账户被分类为机器人。最后,我们使用交叉验证来评估分类器。
受 DNA 影响的僵尸分类器的理论基础是,与人类账户相比,僵尸账户更有可能彼此相似。该方法利用一个公式计算给定字符串的概率分布,并利用对称 KL 发散计算与两个字符串相关的概率分布之间的距离 [58]。这样,该方法就能计算出两个账户对应的 DDNA 字符串之间的距离[23]。为了实现这种方法,我们将训练数据集中的僵尸账号分成 50 组,与 Gilmary 等人的方法类似[23]。我们计算了组内所有账户对的平均距离。然后将所有组中的最大平均距离作为判定阈值:如果测试数据集中的任意两个账户的距离小于或等于判定阈值,那么这两个账户就会被分类为机器人。
5.1.2 Datasets
我们的评估数据集(表 2)由 32056 个标记为机器人的 Twitter 账户和 42773 个标记为人类的账户组成,这些账户均选自机器人资源库4 。为了消除类别不平衡可能导致的比较分析偏差,我们将所有数据集合并,但从多数类别(人类)中随机抽取了 32056 个账户。
5.1.3 Results
我们评估了 BLOC、Botometer、数字 DNA 的三种变体(b3 类型、b3 内容和 b6 内容)[10],以及通过预测机器人和人类标签受 DNA 影响,所有这些都在表 2 中相同的带注释数据集上进行。我们计算了精度、召回率和来自 5 倍交叉验证的 F1
如表 3 所示,Botometer-V4 在 F1 指标上略微优于 BLOC。不过,BLOC 使用的特征明显较少。DNA-influenced 的表现优于 Digital DNA,尽管它将所有账户都标记为僵尸。

(3:使用 5 折交叉验证以及特征数量的不同机器人分类器的精度、召回率和 F1。每个指标的最佳值以粗体显示。受 DNA 影响的分类器产生了 1.0 的回忆,因为它们总是预测所有帐户都是机器人)
5.2 Coordination detection
多个国家利用社交媒体开展针对本国公民、外国公民和组织等的信息行动。Twitter 将信息行动定义为平台滥用的一种形式,即对操纵或扰乱用户体验的信息或行为进行人为放大或压制。
我们使用 "驱动者 "一词来指从事某些信息操作的账户。驱动者可能会采用垃圾邮件、假冒、混淆和/或针对个人或社区等策略。我们认为所有这些行为都是相互协调的,但并不加以区分。我们的任务是将驱动者与推送相同主题的普通(控制)账户区分开来。
5.2.1 Methods
协调检测基于无监督学习,即识别具有可疑相似行为的账户。BLOC 词表达行为特征。我们按照第 5.1.1 节所述方法生成 TF-IDF 向量,然后通过两个向量之间的余弦值计算两个账户之间的相似度。
我们将 BLOC 与三种基线方法进行了比较,这三种方法对协调账户之间可能共享的行为特征做出了不同的假设[39]:标签序列(Hash)、活动(Activity)和共同转发(CoRT)。标签基线法通过找出那些主要使用相同标签序列(如相同的标签 5-grams)的账户来识别协调账户。活动法查找发布推文时间同步的账户:经常在同一时间窗口内发布推文或转发推文的账户会被视为可疑账户。
与 Pacheco 等人[39]的做法类似,我们考虑的是那些在 30 分钟内持续发布推文的账户。
共同转发法通过找出主要转发相同推文的账户来识别协调账户。根据 Pacheco 等人的研究[39],我们生成了标签 5-gram、活动时间间隔和转发推文 ID 的 TF-IDF 向量。所有基线都使用 TF-IDF 向量之间的余弦值来计算相似度。我们还评估了一种组合方法。对于一对账户,组合方法取 BLOC 和三种基线计算出的四个余弦相似度值中的最大值。
我们使用 k = 1 ... , 10 构建了 k 最近邻 (KNN) 分类器比较五种方法。我们报告在 k 值中获得的最大 F1。
5.2.2 Datasets
Twitter 发布了超过 141 个信息操作数据集[48]。这些数据集包括 21 个国家的驱动者在 2008 年至 2021 年不同时间段发布的推文。为确保对检测信息操作驱动程序的分类器进行公平评估,我们建立了对照数据集,其中包括未参与信息操作但在同一时间发布相同主题的账户的推文。对于每个信息操作,我们提取了驱动者使用的所有标签。然后,我们将这些标签作为 Twitter 学术搜索 API6 的查询条件,该 API 没有日期限制。我们提取了与驱动器在相同日期、使用相同标签发布推文的账户。最后,我们提取了最多 100 条与驱动器在相同日期发布的推文,重建了每个账户的时间线。如表 4 所示,我们为 36 个信息操作创建了控制数据集。这些数据集代表了 18 个国家和整个时间段。

(选定的信息操作。我们列出了生命周期、用于评估的周数(自信息操作开始以来),以及在评估周内活跃的驱动程序和控制账户的数量。请注意,评估周不一定是连续的。)
有些信息操作持续了几个月(如表 4 中的中国 3),有些则持续了五年(如表 4 中的伊朗 7)。因此,我们可以对不同时间段(如第一年、最后一年、所有年份)的驱动因素进行检测实验。从减轻影响的角度出发,我们遵循的原则是:在信息(推文)尽可能少的情况下,尽早发现驱动者。我们认为,早期发现驱动者较为困难,因为可能没有足够的具有协调信号的推文。
根据上述原则,我们在每次实验中都会逐步增加两周的数据,直至观察到至少 10 名驱动者的第一年结束或活动结束(以时间在前者为准)。换句话说,我们实验的第一个实例是在两周数据的基础上进行的,第二个实例是在四周数据的基础上进行的,以此类推。使用不断增加的评估间隔是为了探索准确性如何取决于积累的数据量。对于每种协调检测方法,我们都会生成与每个信息操作和评估区间内活跃的所有驱动者和控制账户相对应的向量。表 4 列出了整个评估时间段以及数据集中驾驶员和控制账户的数量。
5.2.3 Results
图 5 显示了在一个子集的编队操作中表现最好的分类器的 F1 值。

(图 5:在至少有 10 周数据的活动子集中,检测信息操作驱动因素的最佳分类器的 F1 分数。x 轴上显示的周数代表驱动因素活跃的周数(评估周数);这些周数不一定是连续的。曲线图按第 10 周使用综合方法计算的 F1 分数从高到低排列。)
每个图的 x 轴代表评估周数,y 轴代表最佳分类器的 F1 分数。信息操作按照各自的 F1@Week 10 综合得分从高到低排列,以反映检测其驱动程序的难度。信息操作的 F1@Week 10 综合得分是使用综合方法计算的 10 周数据的 F1 得分(F1@Week 10)。表 5 列出了所有信息业务的 F1@Week 10 分数。

(表 5:用于检测信息操作驱动因素的 BLOC 和基线分类器的 F1 分数,根据每次活动前 10 周的数据计算得出(F1@第 10 周)。对于数据少于 10 周的活动,将使用整个数据集。信息操作按照组合方法的F1分数排序(组合F1@Week 10)。每个活动的最佳方法以粗体显示。请注意,当分类器使用的相似性信号无法在特定活动驱动者的行为中观察到时,F1 = 0。在中国1,没有观察到任何一对司机之间的共同转发。)
根据图 5 和表 5,BLOC 在大多数活动中的表现都优于基线。来自中国的信息行动(如中国 4 和中国 5)的驱动因素最容易检测;除 Hash 外,所有共序检测方法的 F1 分数都高于 0.9。最难检测的驱动因素是来自阿联酋的信息操作。图 5 中我们还注意到,在某些活动(委内瑞拉 4、委内瑞拉 3 和埃及阿联酋)中,不同方法的准确性随着训练数据的增加而提高。这表明驱动者会同时显示多种协调信号。然而,数据越多并不一定意味着检测驱动者的准确率越高。在一些活动中,没有明显的时间趋势,在少数情况下(如伊朗 4 号和伊朗 3 号),增加更多数据会阻碍检测。这表明,驾驶员可能会改变其行为,从而变得更难被发现。
图 6 比较了 BLOC 和三种基线协同检测方法的性能。x 轴代表平均 F1,y 轴代表所有信息操作中所有分类器的平均特征数量。
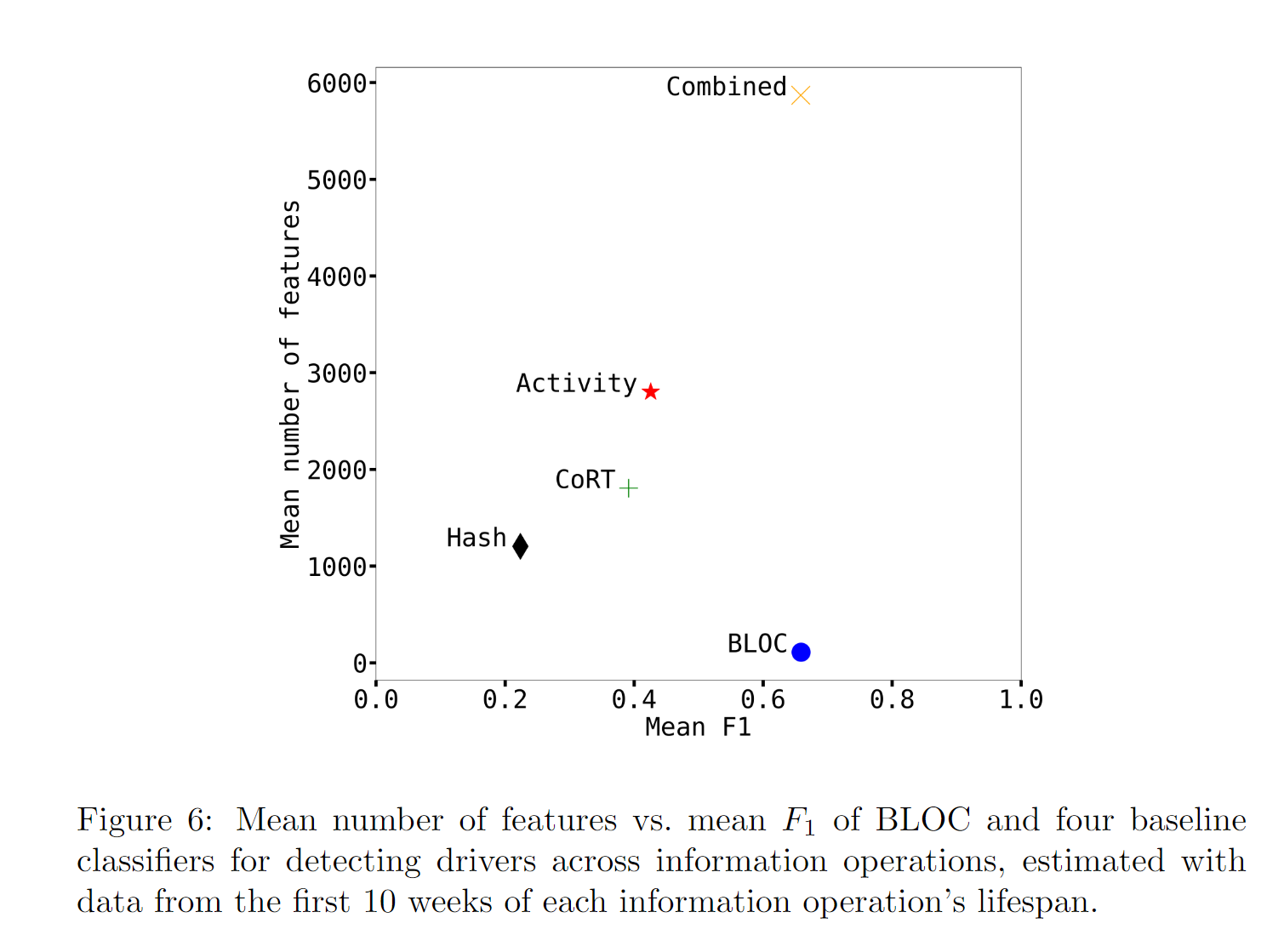
(平均特征数与 BLOC 的平均 F1 和用于检测信息操作驱动因素的四个基线分类器的关系,根据每个信息操作生命周期前 10 周的数据进行估计。)
这两个值都是根据信息操作最初 10 周的数据计算得出的。在协调检测任务中,BLOC 分类器的表现优于所有基线,平均 F1 = 0.659,特征数量最少(108 个)。组合分类器的平均 F1 = 0.658 与之相似,但使用的特征数量最多(5869 个)。
6 Discussion
为了应对社交媒体影响力操作带来的深远威胁,研究人员开发了针对特定类型恶意行为的方法。然而,其中一些技术的有效性(主要依赖于手工制作的功能)是暂时的,因为恶意行为者会不断改进其策略来逃避检测。在本文中,我们提出了 BLOC,一种代表社交媒体用户行为的通用语言,无论其类别(例如,机器人或人类)或意图(例如,良性或恶意)。 BLOC 单词映射到以无监督方式导出的特征。我们注意到,BLOC 并没有使特征工程变得无关紧要,事实上,我们可以使用 BLOC 来设计特征。
虽然 BLOC 与平台无关,但我们通过 Twitter 上的两个实际应用证明了它的灵活性。在机器人检测任务中,BLOC 的表现优于同类方法(数字 DNA 和 DNA 影响),也可与最先进的方法(Botometer-V4)媲美,但特征数量要少得多。这表明,BLOC 的动作和内容阿尔法投注提供了有用的信号,可以在各种数据集上区分自动账户和人工账户。
在协调检测任务中,BLOC 的表现优于基线方法,该任务旨在识别信息操作生命周期早期阶段的驱动因素。在不同的信息行动中,所有分类器的性能都不尽相同,这凸显了驱动行为的异质性。这与 Twitter 的报告一致,Twitter 的报告显示,司机包括人类、自动账户、协调账户等 [49, 50]。因此,某些信息操作的驱动者比其他信息操作的驱动者更容易被发现也就不足为奇了。