论文信息
题目:SimVODIS++: Neural Semantic Visual Odometry in Dynamic Environments
作者:Ue-Hwan Kim , Se-Ho Kim , and Jong-Hwan Kim , Fellow, IEEE
时间:2022
来源: IEEE ROBOTICS AND AUTOMATION LETTERS(RAL)
Abstract
语义的缺乏和动态对象导致的性能下降阻碍了其在现实场景中的应用。
为了克服这些限制,我们在Simultanerous VO、Object Detection和Instance segmentation (SimVODIS) 网络之上设计了一种新颖的神经语义视觉里程计 (VO) 架构。
接下来,我们提出了一种具有多任务学习形式的专用姿态估计架构,用于处理动态对象和 VO 性能增强。
此外,SimVODIS++ 专注于显着区域,同时排除无特征区域。
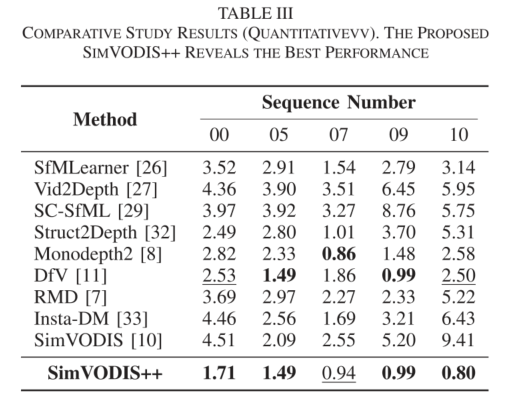
我们工作中进行的大量实验证明,所提出的 SimVODIS++ 提高了动态环境中的 VO 性能。此外,SimVODIS++ 专注于显着区域,同时排除无特征区域。通过进行实验,我们发现并解决了传统实验设置中的数据泄漏问题,随后进行了许多先前的工作,这也是我们的贡献之一。
Introduction
目前的自监督单目深度和运动学习方法存在三个局限性:缺乏语义信息,动态环境下视觉里程计(VO)性能下降,以及测量VO性能的错误实验设置。
- 首先,采用VO算法的智能系统通常需要语义信息来执行高级任务,如机器人提供的家庭服务[1]。这种系统在VO线程之外运行另一个计算线程来提取语义信息,这增加了系统的复杂性和计算时间[10]。
- 其次,由于自我监督损失的静态场景假设,目前的方法很难在动态环境中学习深度和运动[11]。光度一致性损失是自监督损失的核心,需要一种合适的机制与动态对象进行学习[12]。
- 此外,目前的一组方法是在训练数据分割的部分评估VO性能,而不是在不涉及训练过程的数据上,即数据泄漏问题。这种错误的实验设置已经成为一种惯例,许多先前的研究都遵循了这种惯例。
为了克服上述限制,我们提出了SimVODIS++,SimVODIS++从一组输入图像帧中估计以下信息:
1)图像帧之间的相对姿态,
2)密集深度图预测,
3)对象类,
4)对象边界框
5)实例分割掩码。
SimVODIS++的网络架构允许提取智能系统的五个基本信息,计算量比Mask RCNN[13]略有增加。因此,智能系统可以通过SimVODIS++从共享特征中提取几何和语义信息来提高计算效率。
此外,我们还致力于提高动态环境中自监督单目深度和运动学习的VO性能。为了实现这一目标,我们提出了一种专注的姿态估计架构,用于处理保持网络大小的移动对象。
我们使用了一个自注意模块,使SimVODIS++学会以自监督的方式排除动态对象并选择显著区域。SimVODIS++还学习在该过程中排除无特征区域。
此外,我们提出了一种学习相机校准和姿态估计的训练方法,作为多任务学习,以提高VO性能。简单地学习相机校准并不能提高VO性能,但我们的学习公式具有理论背景。
Approach
Network Architecture
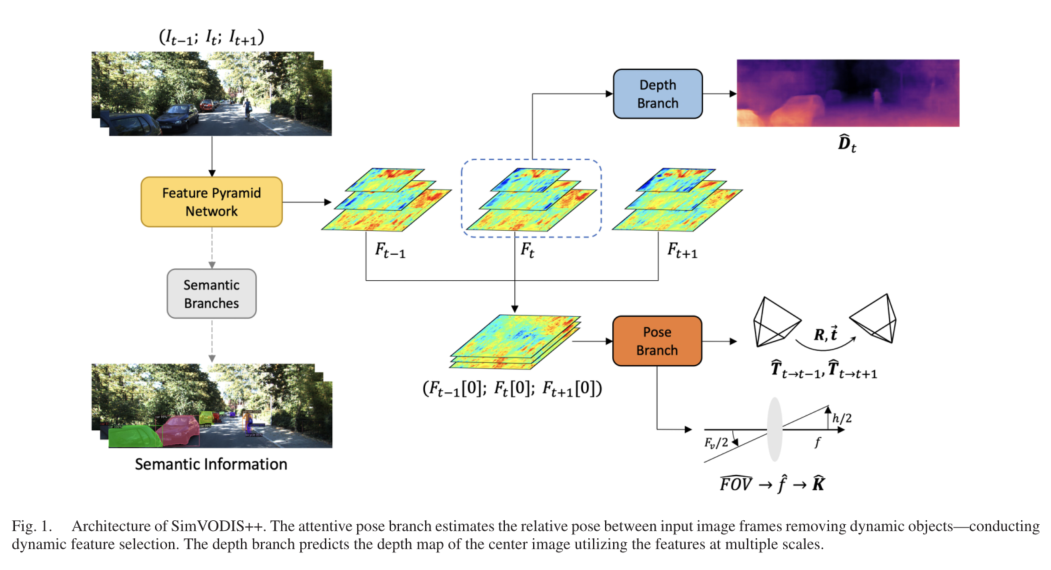
我们基于以下推理设计了SimVODIS++网络:
(1)用于语义分支(对象检测和实例分割)的特征金字塔网络(FPN)提取能够执行语义和几何任务的一般特征;
(2)我们可以利用这些丰富的特征来执行位姿估计和深度图预测。对于SimVODIS++,与SimVODIS[10]相比,我们设计了两个新功能:姿态估计和相机校准。我们进行专注的姿态估计以去除动态对象,并进行相机校准以提高VO性能。由于所提出的姿态估计和相机校准导致的参数总量的增加是最小的。
Attentive Pose Estimation
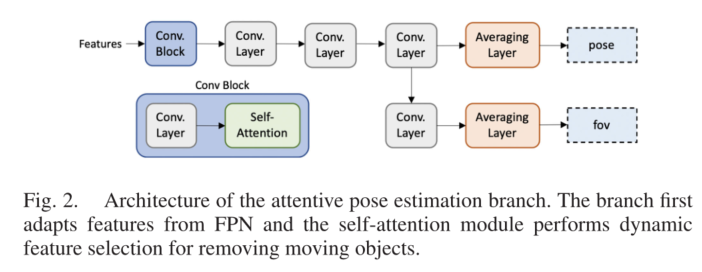
图2描述了在动态环境中用于鲁棒性能的所提出的注意姿态估计的架构。
Conv. Block 从FPN接收特征,调整输入特征以进行自注意,并通过自注意进行动态特征选择。对于自我注意,我们使用CBAM模块[37]。在训练过程中,CBAM模块让姿势分支学会专注于具有相关特征的区域,并尽量减少对动态对象的关注。

此外,动态选择的特征要经过一系列Conv.层。除了Conv.块中的一个之外,Conv.层具有3×3个内核。Conv.块中Conv.层的核大小是3×3或7×7;我们在消融研究中研究了核大小的影响。之后,平均层紧随其后,并在空间上对输入特征进行平均。最后,我们缩放平均姿势以生成输出姿势值。
Camera Calibration
我们将相机参数的学习和姿态估计作为多任务学习,以提高姿态估计的性能。在这个过程中,我们做出了两个适用于大多数现代相机的假设:
(1)焦距在垂直和水平方向上是相同的;
(2)主点在中心。接下来,我们选择相机参数的监督学习,因为光度一致性损失容忍相机参数的无监督学习,如下[11]:

此外,我们用垂直视场(Fv)而不是焦距(f)来参数化相机参数的学习。垂直视场可以从单个图像中直接观察到,而焦距则不然[38]。这个特性使得学习垂直视场的过程是稳定的。
我们从垂直视场中恢复焦距如下: f = h 2 × t a n F v 2 f=\frac{h}{2×tan {\frac{F_v}{2}}} f=2×tan2Fvh。然后,具有两个假设的相机矩阵变为

Loss Function

Evaluation