Enhance Images as You Like with Unpaired Learning

- 这是IJCAI 2021的文章
- 文章提出一个条件GAN模型,用reference image作为条件,可以在unpaired images上训练暗图增强模型,使得增强结果根据reference image来调节色调亮度和对比度。训练的监督分为四部分,一个是以输入图片为条件时GAN生成的必须是输入图片,一个是增强结果和输入图片的空间相关性,一个是增强结果和参考图片的全局色调相关性,一个是GAN损失。
- 网络结构图如下图所示,部分模块的名称没有统一。上面的self-Mod就是PSM,cond-Mod就是CCM。PSM就是Unet跳跃连接的结合方式,加了一些归一化的trick,而CCM就是用提取到的条件向量来改变特征图。
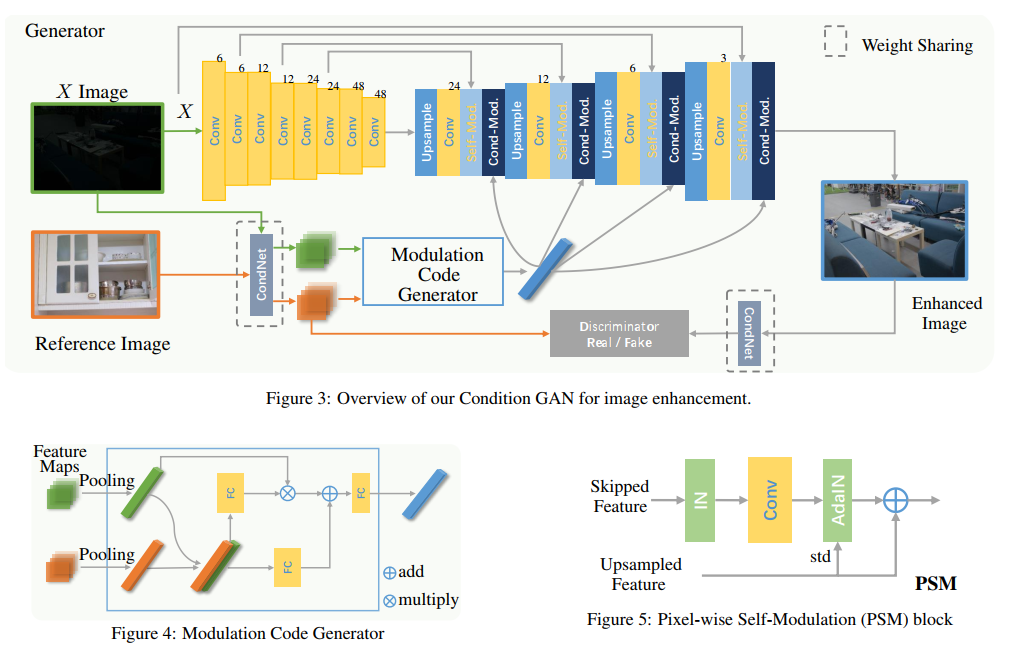
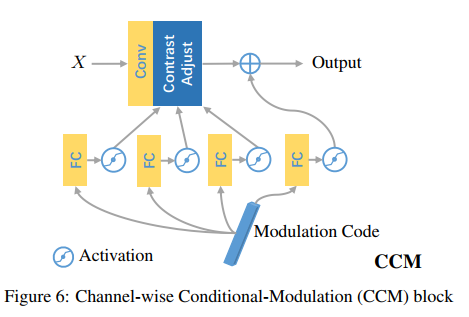
- CCM用的公式如下,这个modulation code经过两层全连接后,预测出4个向量,对x进行操作,产生最后输出的m(x):
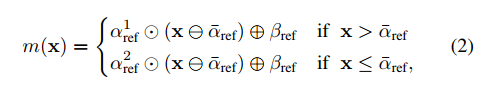
- 方法给出的实验结果如下:

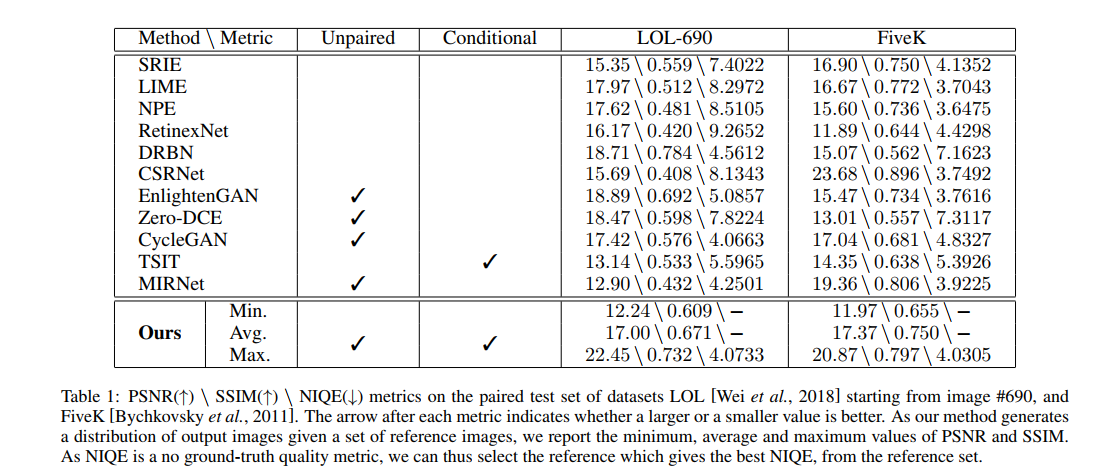
- 参数量是8915727。指标的实验结果文章声称是选不同的reference image进行测试,统计其PSNR的平均值和最小值得到的,但没有说明reference image的来源。
- 总体来看,网络结构有点复杂,应用也没有进一步挖掘。
Exemplar‑guided low‑light image enhancement

- 这是中科院4区期刊 Multimeia systems的一篇2022的论文,提出了一种用reference image来引导增强的方法,并且造了一个数据集,其实就是把LOL这样的成对图片,将GT进行一定的旋转/scale/padding操作,作为与GT不同的reference image,来引导暗图增强。结构如下图所示:
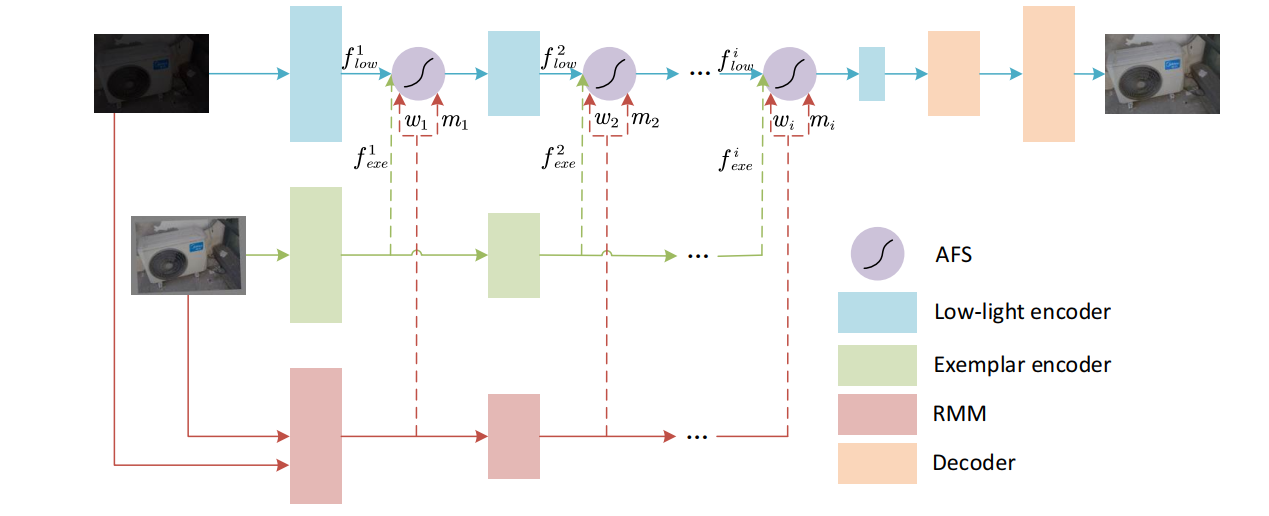
- 这里的AFS是类似注意力的机制
- 实验结果如下图所示:
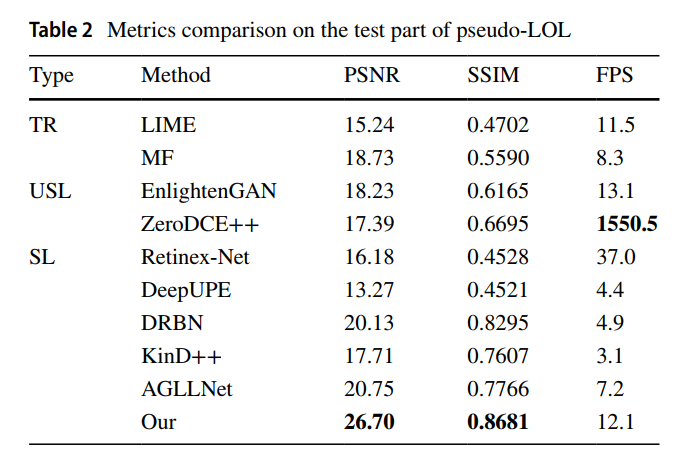
- 其实是一篇水文,读起来太折磨了,错漏百出
Enhancement by Your Aesthetic: An Intelligible Unsupervised Personalized Enhancer for Low-Light Images

- 这是ACMMM2022的一篇文章。文章提出了一种基于reference image的增强方法。如下图所示:
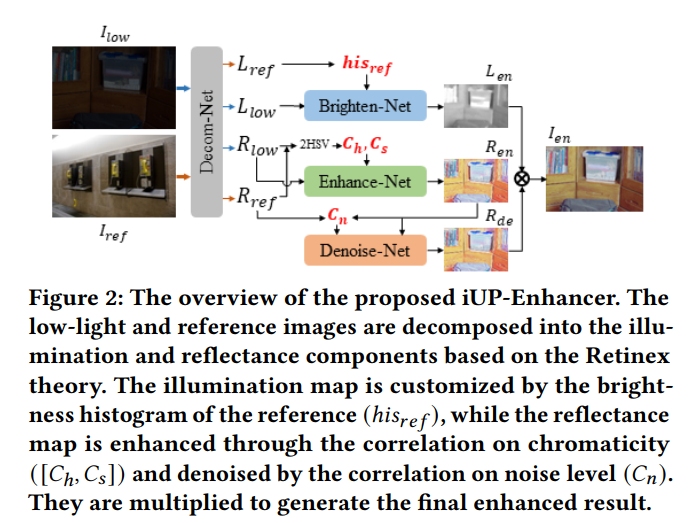
- 方法将图片分解为L和R分量,提取refernece image的L分量的直方图来指导L分量的增强,提取input image和reference image的R分量的色度图的直方图和色饱和度图的直方图,计算input image 和reference image的这些直方图之间的相似度,作为全连接层的输入,预测系数来对R分量的增强网络的特征进行recale和bias,如下所示,其中miu和sigma是特征图自身的均值方差,可以看作是instance norm,而gamma和beta则是来自相似度的指导值
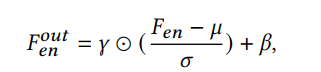
- 损失上,为了使得增强结果和ref image有相似性,添加了增强结果和ref image 的R分量的hue 和 saturation的直方图的L1损失
- 下面的denoiseNet就是用了LLFlow中的方法对noise map进行估计,然后用上面一样的方法去算noise map的直方图的相似度,denoise 模块不是本次调研重点,就不展开了。
- 实验结果如下,其中reference是从LOL FIiveK和ExDark随机选的(这就很奇怪了,为什么要在exdark里选reference image),然后取的是五折的平均结果

- 此外,提供了可调节色调、噪声水平、亮度、色饱和度的参数(其实就是把输入网络的相似度的那个值进行调整)

- 总结:采用了基于直方图相似度进行reference的idea,并提供了基于相似度的可调节参数。随机reference的实验不太合理,psnr也不太高,没有验证与reference image的相似性的指标结果。采用了但分解和调制的方法进行的编辑。
StarEnhancer: Learning Real-Time and Style-Aware Image Enhancement

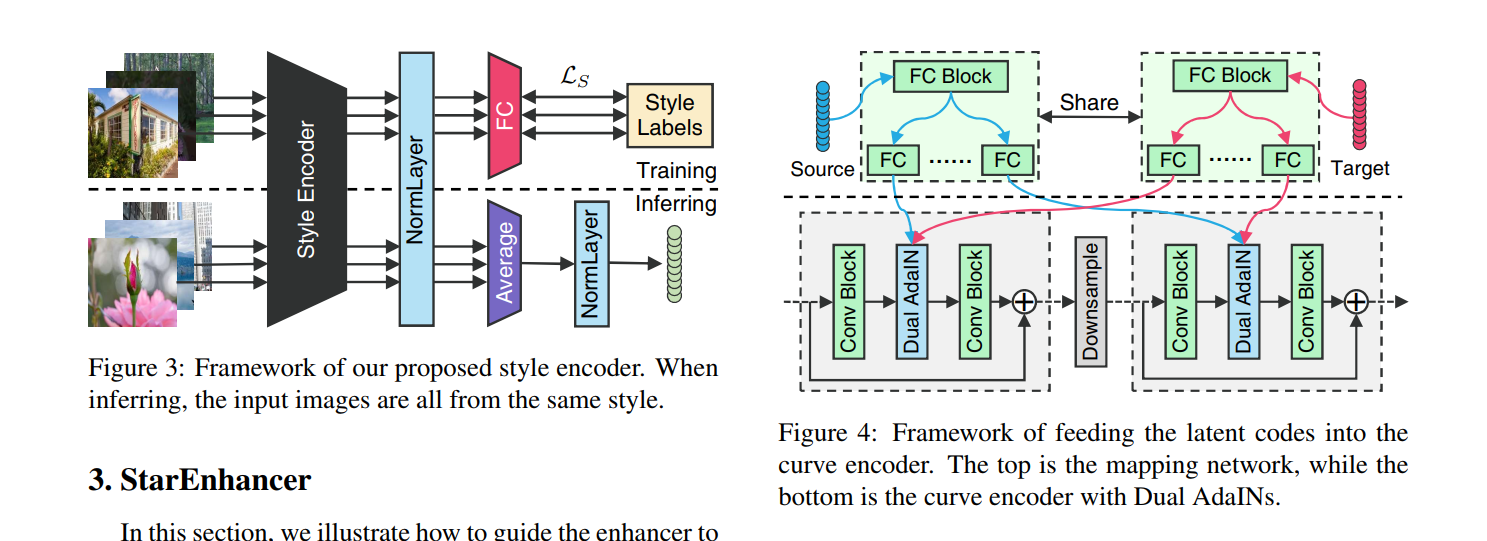
- 这是ICCV 2021的论文。文章提出首先训练一个style classifier,然后去掉后面的分类层,用网络来提取style code,然后用一个全连接层把style code映射为网络中归一化层所用的参数,从而相似风格的图片有相似的style code,从而能产生面向不同风格聚类的各种各样的增强结果。
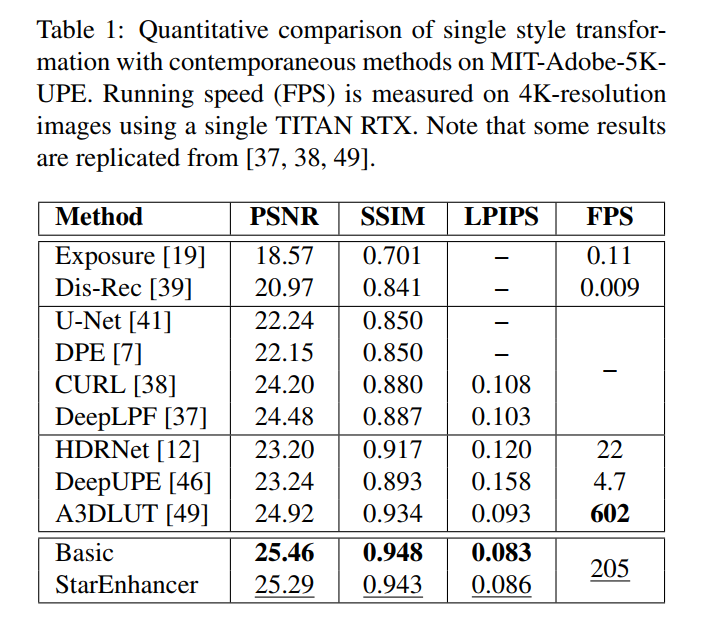
给出了在fivek上的实验结果,生成测试图片的时候用的是平均的style code(不过没说清楚是在什么数据集上的平均):
- 感觉很多实验细节没有完全交代。总体看还是像personalized image enhancement,不过可以给定一张用户喜好的图片,提取其style code,用于进行enhancement,并不是很强调reference image。