
论文链接:https://arxiv.org/abs/2304.13031
开源代码仓库地址:https://github.com/AIR-DISCOVER/DQS3D
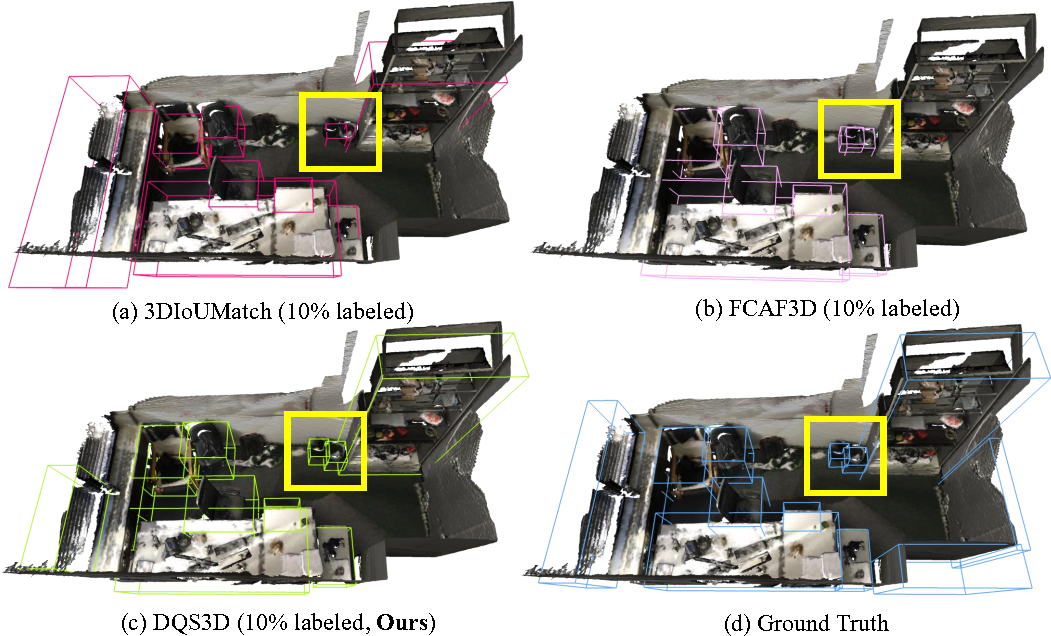
01. 简介
本文旨在解决三维室内场景中高昂的标注成本问题,特别关注半监督条件下的三维物体检测。为了解决这一问题,我们采用了强大的自学习框架,该框架在半监督学习中取得了显著进展。虽然这种方法在图像级别或像素级别预测方面表现出色,但在目标检测问题中,目标 Proposal 匹配(后文皆称为候选框匹配)的挑战依然存在。
目前的方法通常采用两阶段流程,第一阶段对生成的候选框进行启发式选择,然后进行匹配,导致训练信号在空间上呈现稀疏分布的特点。与之不同的是,我们提出了一种单阶段的半监督三维检测算法,通过此算法,我们可以在空间上获得密集的监督信号。
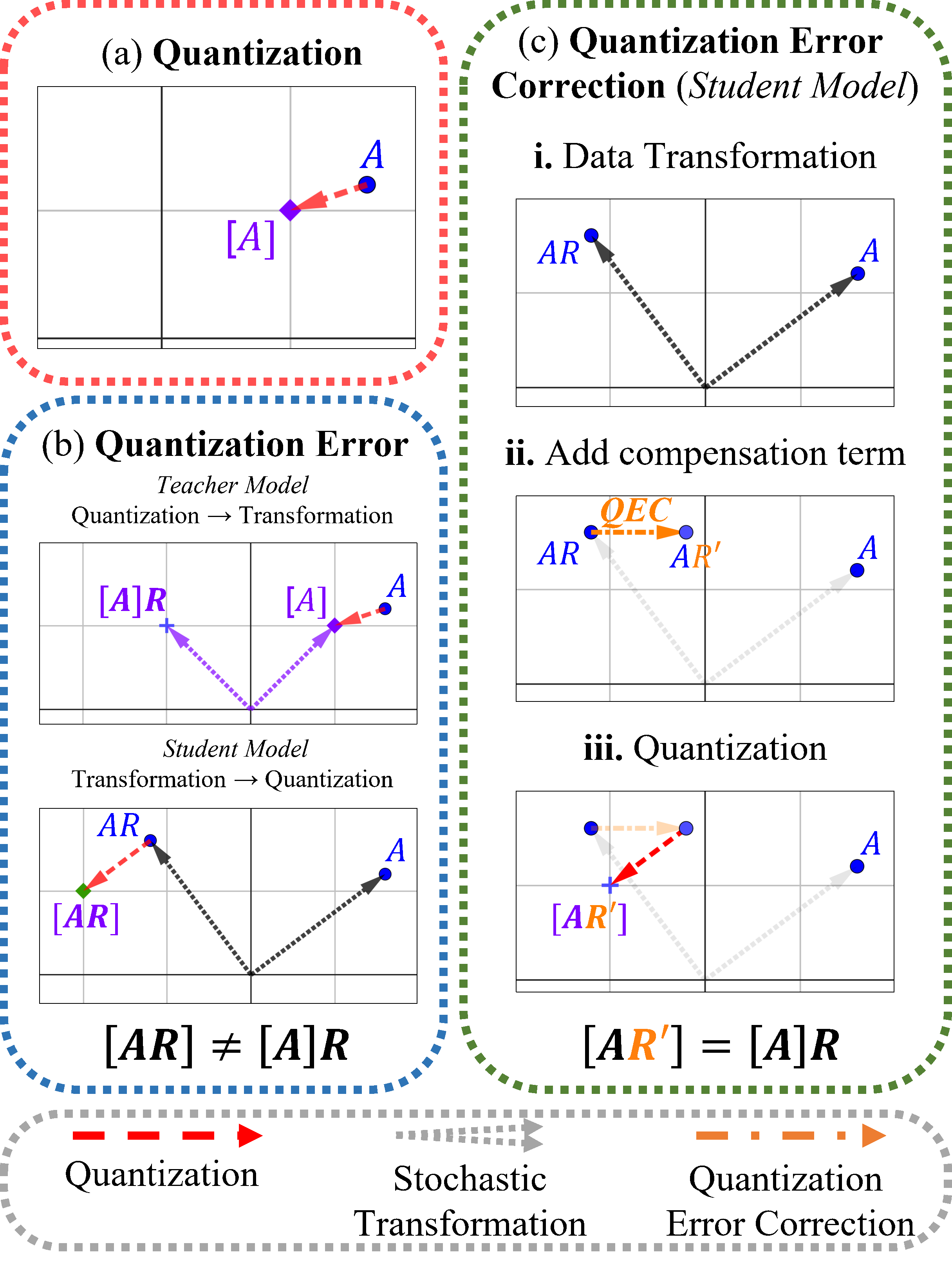
然而,我们的算法也面临一个基础问题,即点到体素离散化引起的量化误差,这必然导致体素域中两个不同数据增广视图之间的不对齐。为了解决这个问题,我们推导并实现了一种闭式解,可以在线地补偿这种不对齐现象。通过这个方法,我们取得了显著的成果,例如,仅使用 20% 的标注数据,我们就成功将 ScanNet 的 [email protected] 从 35.2% 提升至 48.5%。
02. 方法
2.1 密集匹配
为了解决半监督三维物体检测任务,基于教师-学生网络(Mean Teachers)的自训练方法强制学生网络和教师网络的预测保持一致。因此,建立在数据增广对齐视图意义下的学生和教师预测之间的映射是至关重要的,我们称之为匹配。
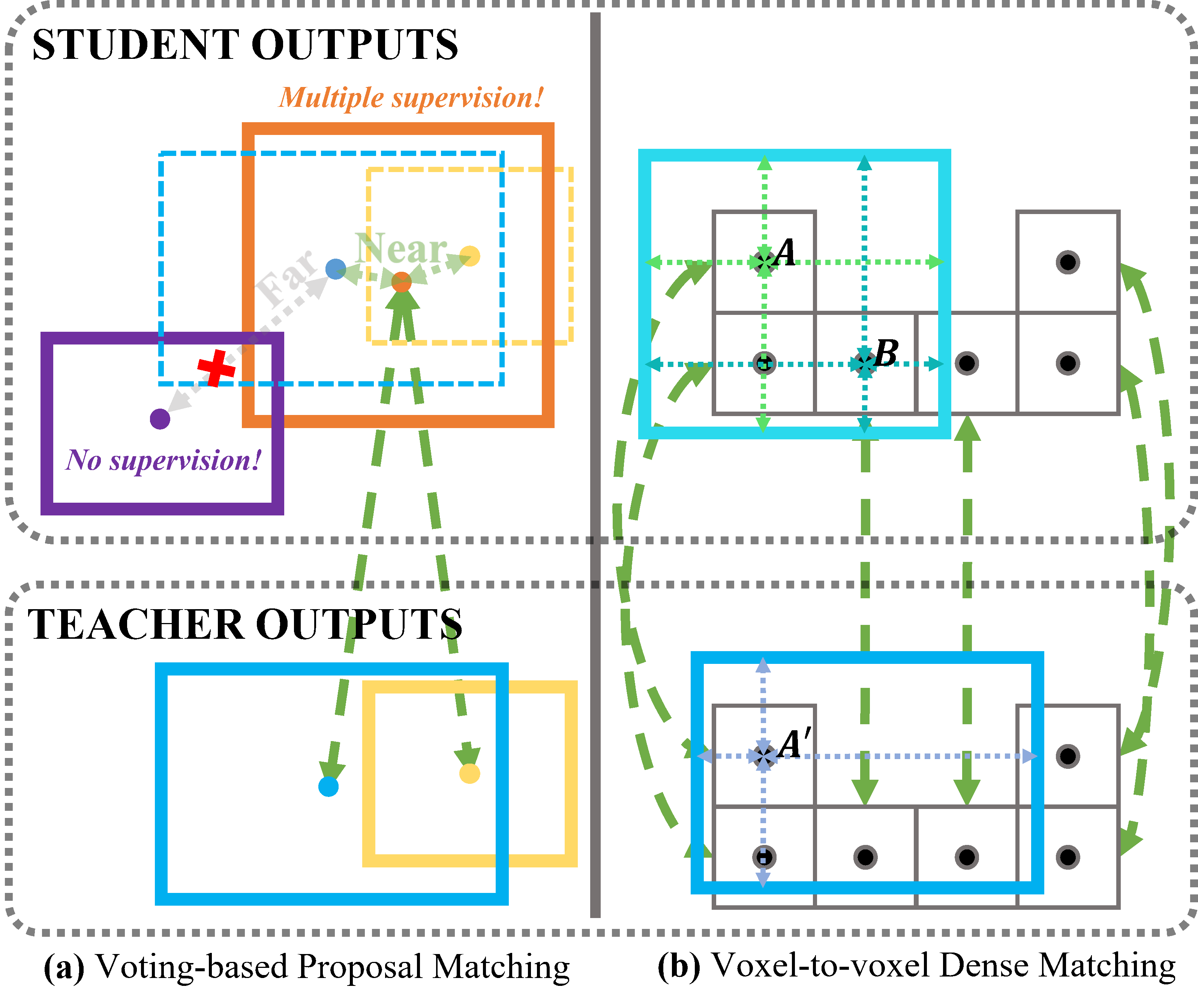
以前的自训练方法 SESS 和 3DIoUMatch 采用候选框匹配来对齐学生网络和教师网络的预测对象(称为候选框),通常通过最近中心策略完成。更具体地说,每个教师候选框与其中心最接近的学生候选框对齐,如图中所示。请注意,虚线框仅用于展示教师输出的空间位置。 尽管教师候选框通常比学生候选框更准确,但我们认为候选框匹配是欠佳的,可能会阻碍从教师到学生的知识传递。这种无效性主要归因于图中所示的两种不利情况,这是由于空间中候选框的稀疏性不可避免造成的:(1)相邻的教师候选框对齐到同一个学生候选框,导致对学生的监督模糊。(2)与任何教师候选框相距较远的学生候选框对齐失败,无法从教师候选框获得监督。
为了解决上述问题,一个充分条件是学生和教师预测之间具有双射关系。我们注意到现在流行的目标检测器是在空间上稠密的,即可以逐体素地进行物体预测的启发。同时,学生和教师视图的体素锚点在空间上是相互对应的。因此,我们提出了一种叫做“密集匹配”的方法,它简单地将相应体素锚点处的预测进行配对。我们相信密集匹配方案具有以下优势:
-
每个预测对象由多个边界框预测来表示,其回归得分在不同的体素锚点处有所变化,这种现象对密集预测模型施加空间正则化,并提高了模型对局部几何的感知能力。
-
通过体素锚点的对应关系,学生和教师预测之间所需的双射关系自然建立。
这消除了前面提到的两种不利情况。基于密集匹配的优势,我们在下一节中提出了一个专门针对密集匹配方案的自训练框架。
2.2 自训练框架
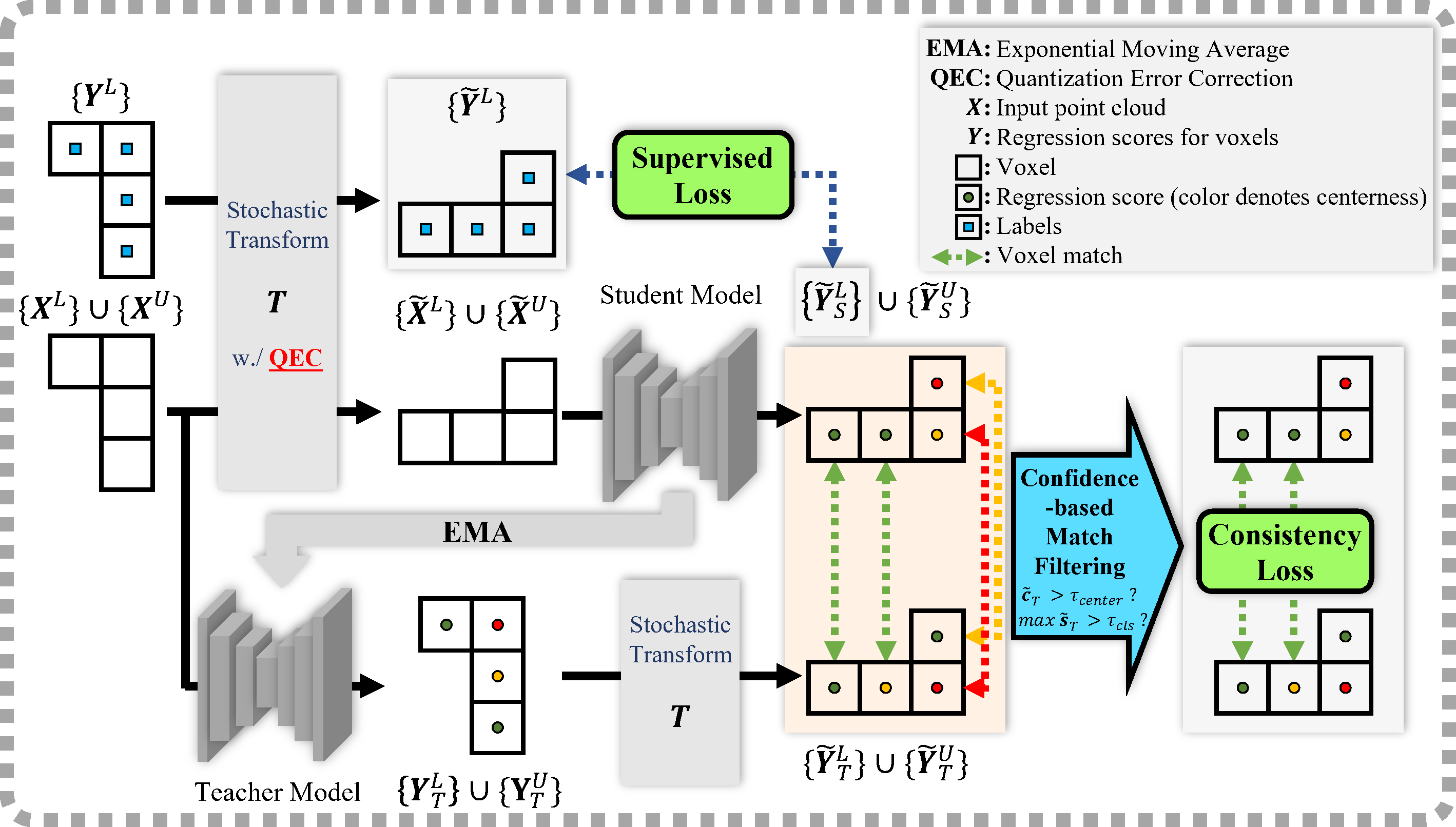

2.3 量化误差及其解决方案

03. 实验
继承 SESS 和 3DIoUMatch对于半监督三维物体检测的研究,我们使用 ScanNet v2 和 SUN RGB-D 数据集对我们的框架进行了评估。
首先,我们比较了我们提出的密集匹配方法和传统的稀疏的候选框匹配方法之间的差异。 我们通过展示密集匹配策略生成的伪标签的数量和质量来验证我们提出方法的优越性,展示结果如下:
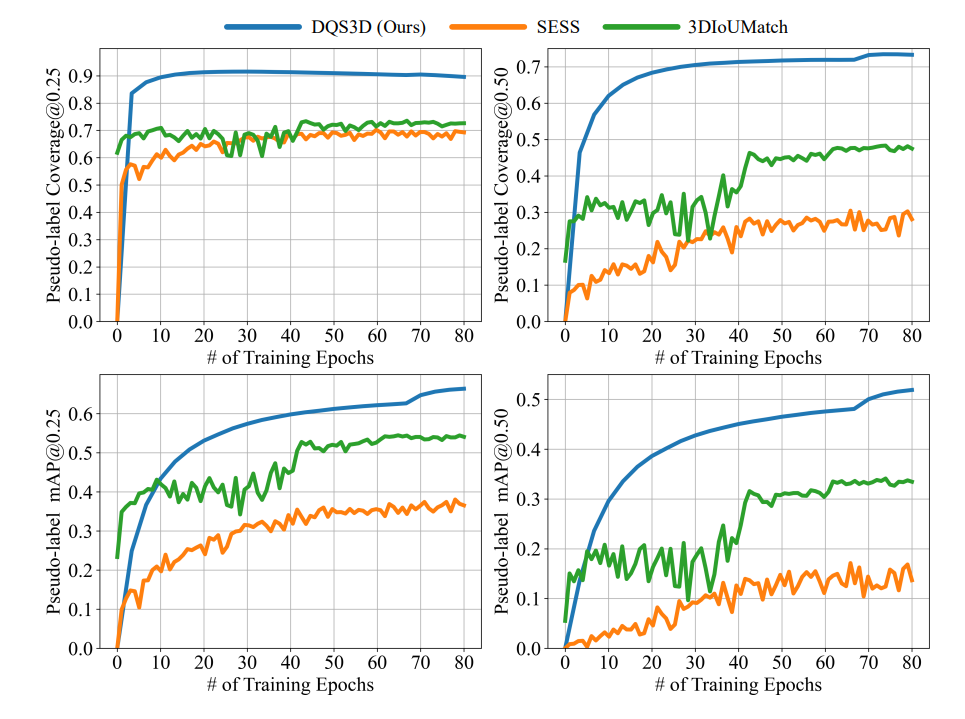
从上图中可以看到,与之前的几种方法相比,我们的方法能够生成更多且更具质量的伪标签,从而自然地,在半监督三维物体检测中表现更优异的性能:
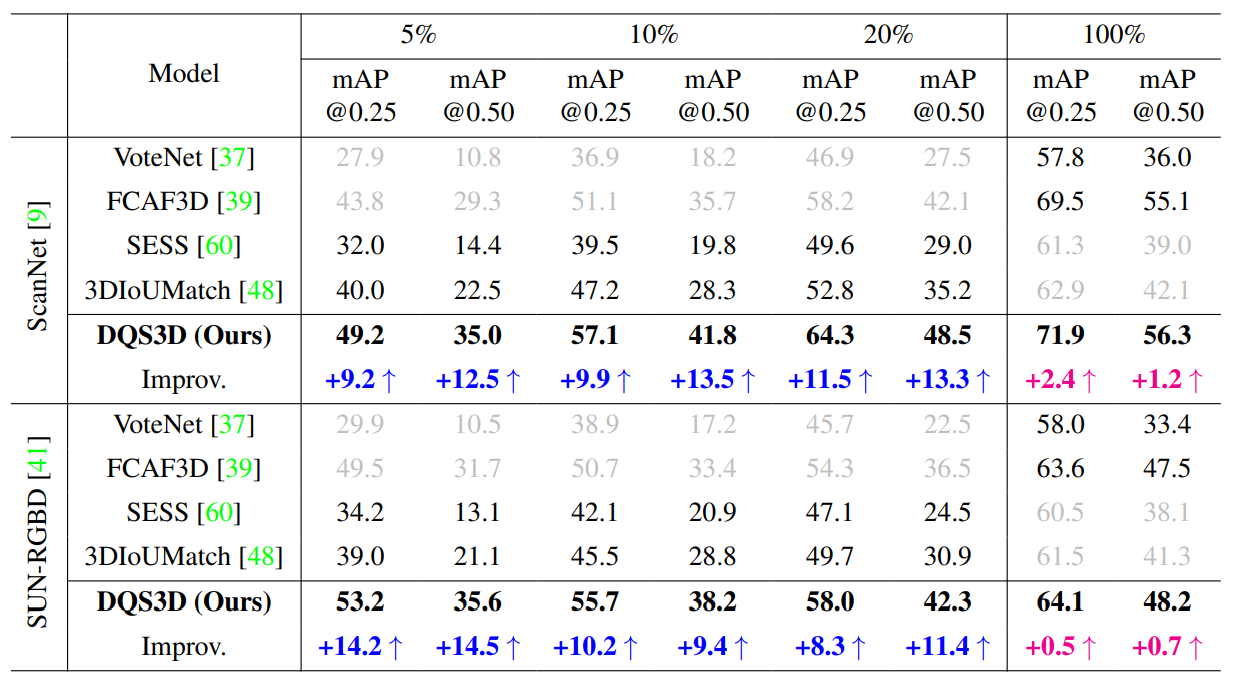
我们在 ScanNet 和 SUN RGB-D 数据集上进行了广泛的实验,并报告了 DQS3D 及先前方法在半监督和全监督设置下的性能。 在半监督设置中,我们对训练集的不同部分(5%,10% 和 20%)进行标记。 我们在标记和未标记的数据集上都施加了一致性损失。 而在全监督设置中,我们将整个数据集都视为标记和未标记的数据集,以检查我们提出的框架是否能够从伪标签的额外监督中进一步学习。实验结果见上表。
从表中我们可以看到,我们的方法在半监督三维物体检测的基准测试中,对于 ScanNet 和 SUN RGB-D 数据集均大幅超越了先前的候选框匹配方法,并取得了新的最先进结果。 值得注意的是,[email protected] 的提升普遍比 [email protected] 的提升更大。 我们将这归因于我们的框架产生的伪标签的密集性,它为学生模型在空间上提供了更精细的监督信号。 这样,预测的物体边界框在更大程度上与目标物体重叠,有助于在更高的 IoU 阈值下实现更明显的性能提升。
然后,我们做了一系列消融实验,来证明我们提出的每个部件的有效性。
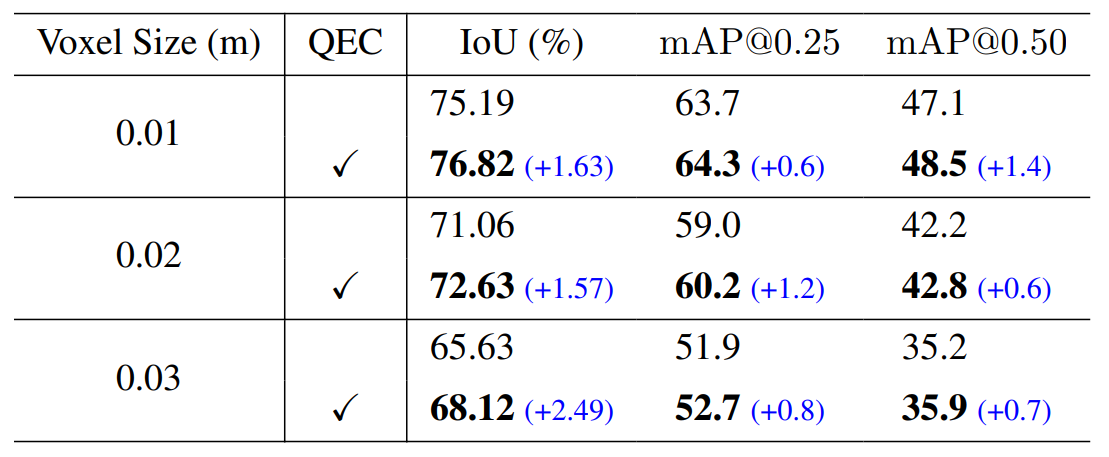
量化误差校正模块。 为了展示我们提出的量化误差校正(QEC)模块的有效性,我们在 ScanNet 数据集上进行了实验(其中 20% 的训练集带有标签)。在实验中,我们使用不同的体素大小来训练我们的提出框架,并对是否施加校正项进行对比实验。除了在“验证”集上的 mAP@{0.25,0.50} 之外,我们还报告了“有标签训练”集上预测的边界框与目标真实边界框之间的加权 IoU。物体的权重由预测的中心性度量值决定。
我们的实验结果如上表所示。 值得注意的是,在所有的体素大小下,使用校正项进行训练的实验性能都比没有使用该项的实验性能更高(最高可达 +2.49% IoU)。 这些非常显著的提升表明了量化误差校正(QEC)模块在解决量化误差这个固有问题上的有效性,从而提高了检测的准确性。

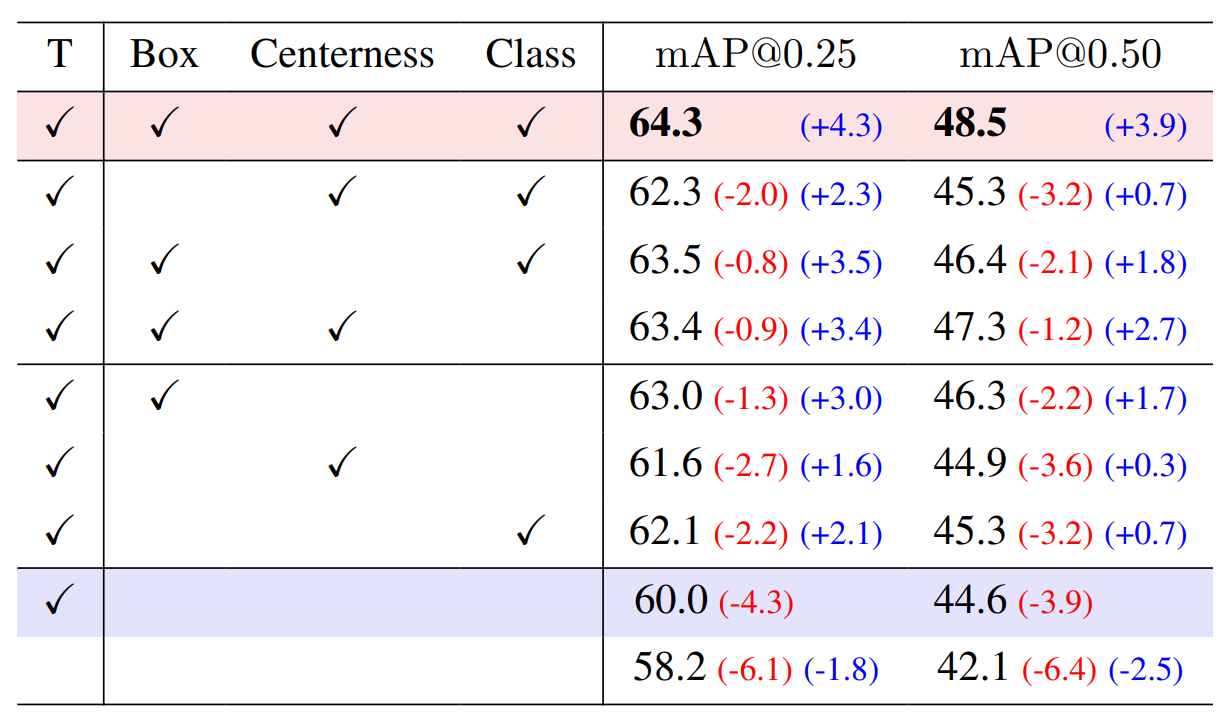
一致性损失。 我们在带有 20% 标签数据的 ScanNet 数据集上进行了一致性损失的对比实验。 实验结果如上表所示。 根据结果显示,缺失了边界框预测参数的一致性损失对性能影响最大,[email protected] 下降了 2.0%,[email protected] 下降了 3.2%,而其他两个一致性损失的缺失也会导致性能下降。 这些结果表明,提出的一致性损失的每个组成部分都是必要的。
04. 总结
本论文提出了 DQS3D 这一自学习半监督三维物体检测框架。与传统的 Proposal 匹配方法不同,DQS3D 利用了密集匹配,并且解决了量化误差的问题,在半监督条件下,在两个广泛使用的基准数据集 ScanNet v2 和 SUN RGB-D 上取得了显著的改进。
此外,论文还提供了证据表明,使用密集预测可以产生更有意义的伪标签,并促进自学习的效果。我们希望本文介绍的方法论和基本技术能够促进更多未来半监督学习领域的研究。
作者:高焕昂
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区