点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
来源:CSIG文档图像分析与识别专委会

在CVer微信公众号后台回复:CCD,可下载本论文pdf和代码
本文简要介绍被ICCV 2023录用的论文《Self-supervised Character-to-Character Distillation for Text Recognition》。该论文通过设计一个自监督的字符分割模块来勾勒未标注的真实图像的字符结构,并通过增强视图之间的变换矩阵,轻松丰富局部字符的多样性,在灵活的增强下保持其成对对齐,实现自监督表征学习。实验表明,通过预训练,提升了模型的表征能力。此外,在文本识别 (Text Recognition),文本分割 (Text Segmentation) 和文本图像超像素 (Text Image Super-resolution) 任务上,该自监督方法都展现了不错的潜力,表明有更广泛的应用场景。
一、背景介绍
近年来,监督学习在计算机视觉领域取得了瞩目的成就。然而,监督学习方法严重依赖于数据的收集和标注。只有足量的训练数据才能防止模型过拟合,以泛化到实际使用场景中。为了降低数据驱动式模型对标签的依赖性,自监督学习成为一个十分有前景的解决思路,并吸引越来越多的学者们的关注[1][2]。
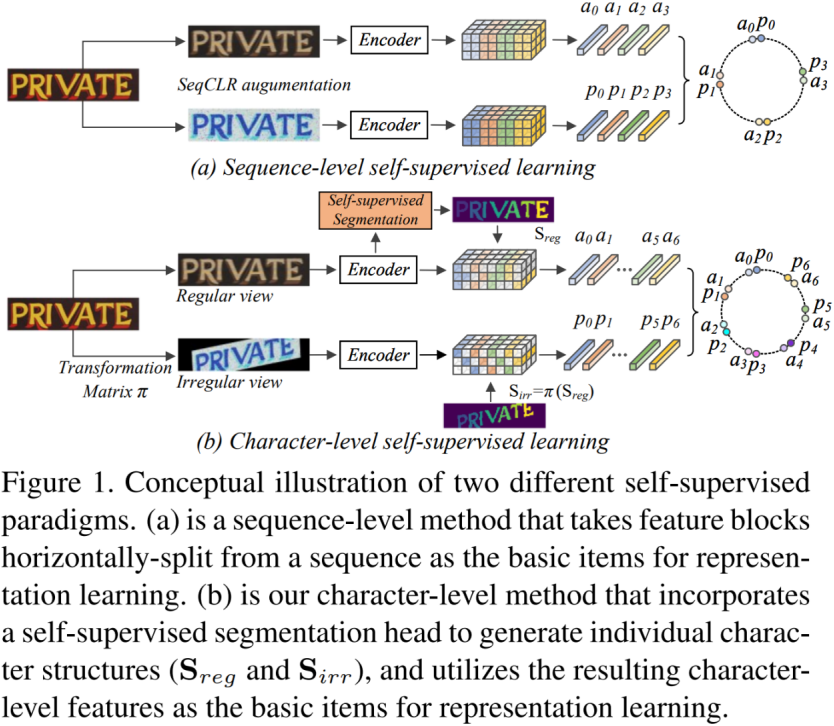
为此,Aberdam等人[3]在文本图像识别领域提出了自监督表征学习方法,如图1 (a) 所示,他们将一行文本切割成多个实例,并在不同实例之间使用对比学习[4]。然而,这种做法仍然是基于现有对比学习方法的过渡做法,文本图像的特点仍没有得到充分挖掘。此外Yang 等人[5]在此基础上,结合生成式任务和对比式任务去学习通用的文本特征表示,进一步提升了识别的性能。这些方法展示了对于文本图像进行自监督预训练的优势,为模型的设计带来启发。
二、方法简述
如图 1 (b) 所示,我们提出了一种字符级的自监督学习范式,称为字符到字符蒸馏(Character-to-Character Distillation, CCD),它通过将文本图像组织成不同的实体,即每个字符和背景区域,来实现跨视角下各种增强的特征表示一致性。具体来说,首先从每个输入图像生成两个视图:具有颜色抖动的规则视图和具有附加几何变换的不规则视图。每个视图都被输入到学生-教师分支的编码器中,以提取代表整个视图的特征。然后,通过联合自监督文本分割和基于密度的空间聚类任务来描绘来自规则视图的字符区域,并且使用两个视图之间的已知变换矩阵生成来自不规则视图的字符区域。这样,CCD自然就保证了跨视图、跨分支对应字符的一致性。因此,通过在灵活的增强下享受局部字符的成对多样性,CCD有效地增强了学习特征的鲁棒性和泛化性,使其更适合与文本相关的下游任务。CCD通过该过程,实现了自监督表征学习。
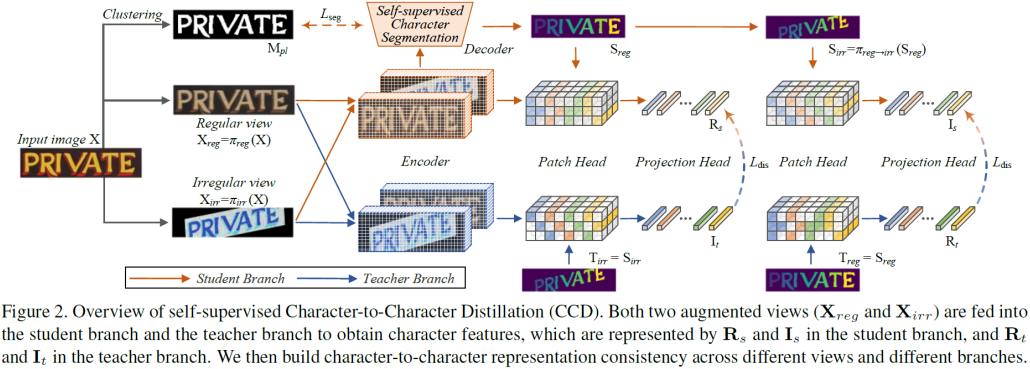
本文方法的详细框图可见图2。受启发于SIGA[6],作者首先通过自监督文本分割模块得到文本分割掩码 。考虑到很多真实的文本图像没有标签,因此作者无法使用隐式注意力对齐模块去获得水平位置信息,进而无法切分得到单个字符结构。退而求其次,作者采用基于密度的空间聚类算法,去分割字符。整个流程如图3所示。
。考虑到很多真实的文本图像没有标签,因此作者无法使用隐式注意力对齐模块去获得水平位置信息,进而无法切分得到单个字符结构。退而求其次,作者采用基于密度的空间聚类算法,去分割字符。整个流程如图3所示。

接下来,我们通过几何变换去实现字符间的结构区域对齐,
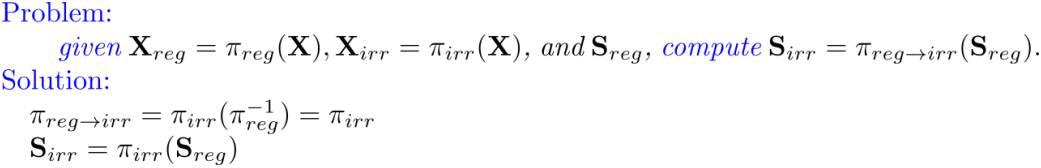
由此我们便可以得到,规则视角下的字符结构和不规则视角下的字符结构。接下来,我们以学生分支上的规则视角为例,展示如何获得字符级的特征表示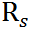 。
。

同理,我们可以获得学生分支上的不规则视角对应的字符级特征表示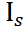 、教师分支上的规则视角和不规则视角对应的字符级特征表示
、教师分支上的规则视角和不规则视角对应的字符级特征表示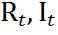 , 然后通过优化学生分支上的字符级特征去匹配教师分支上的字符级表示,以实现蒸馏。
, 然后通过优化学生分支上的字符级特征去匹配教师分支上的字符级表示,以实现蒸馏。
具体地,论文的损失函数为:
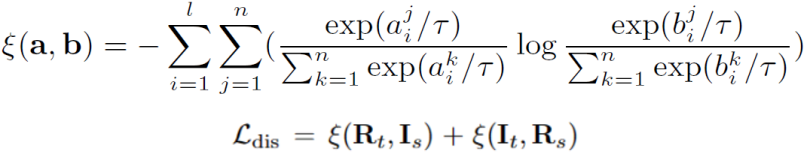
三、实验结果
首先进行了探针评估实验,该实验依照前人工作DiG[4]的设置, 测试主干网络的表征能力。作者强调,由于判别式模型和生成式模型的特性不同,这里的结果难以公平比较,仅供参考。

随后使用不同的比例的训练数据去评估网络的性能,该实验依照前人工作DiG[4]的设置。
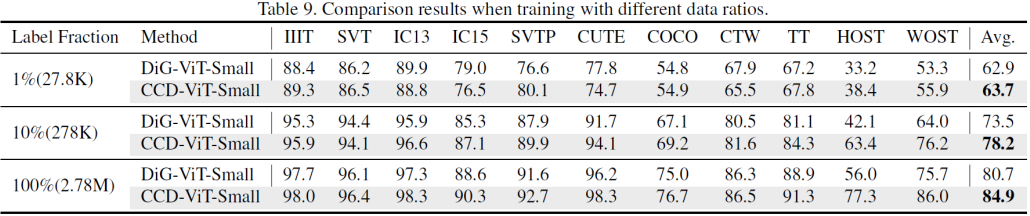
然后作者同自监督文本识别的系列方法进行比较。
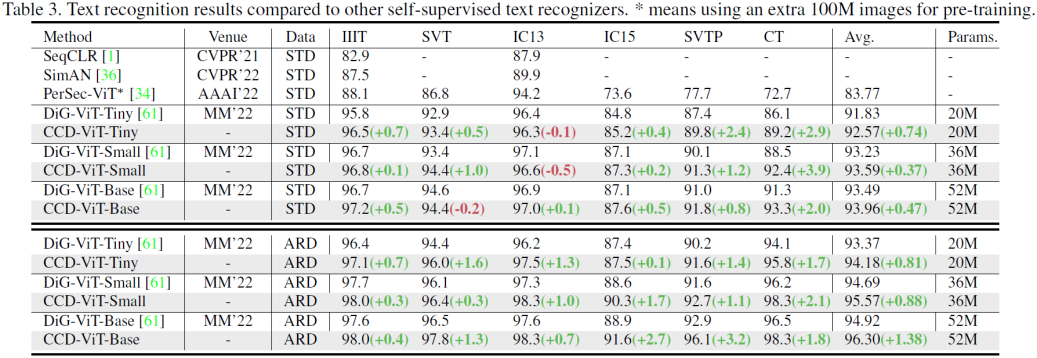
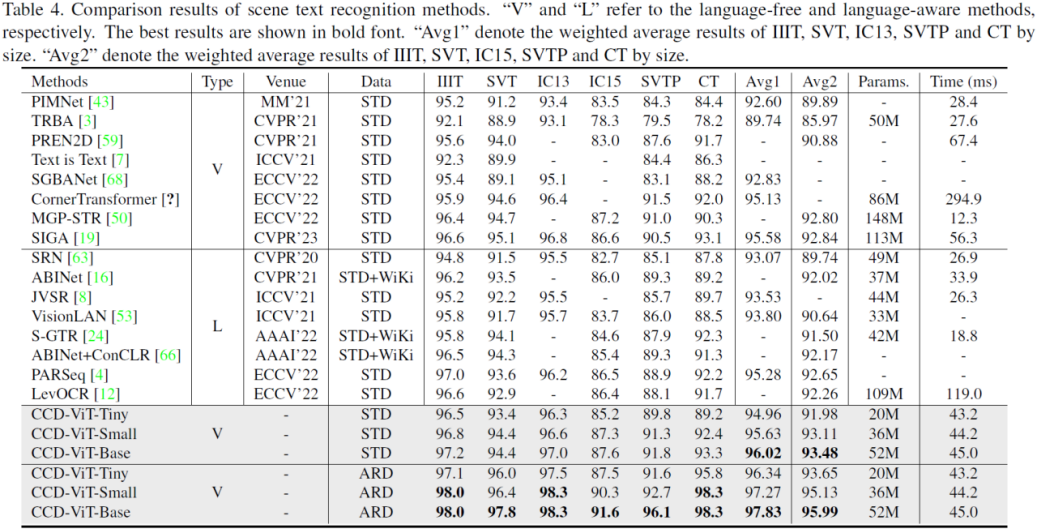
然后作者同监督学习下的文本识别的系列方法进行比较。
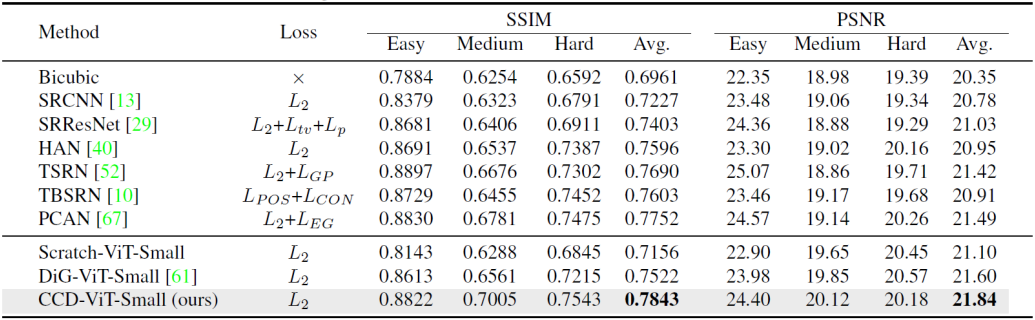
然后CCD也在文本超分辨任务上同之前的工作进行了比较。
根据前人工作DiG[4]内容指出,DiG是首次在文本分割任务上做出评估。因此,作者也在文本分割任务上同DiG进行了比较。

最后,本文展示了在自监督字符到字符蒸馏的可视化例子:


以及在文本分割任务上的可视化结果:

以及在文本超分辨率任务上的可视化结果:

四、总结
相比生成式的方法,CCD从全新的角度,回顾了文本图像的本质特征,重新思考面向文本图像等序列化数据的表征方法。本文提出使用字符结构作为基本项目来实现表征学习,通过建立多分支多视角下同一字符的特征表示一致性,促进模型对文本图像特征的提取能力。实验表明,经过本文方法预训练的识别模型,得到了更好的泛化性能。在大数据时代,自监督方法为该领域的多个视觉任务提供了新的解决思路,希望能带来更深远的意义和更深刻的启发。
五、相关资源
论文下载地址:
https://arxiv.org/abs/2211.00288
代码地址:
https://github.com/TongkunGuan/CCD
在CVer微信公众号后台回复:CCD,可下载本论文pdf和代码
参考文献
[1]. Jing L, Tian Y. Selfsupervised visual feature learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(11):4037–4058.
[2]. Liu X, Zhang F, Hou Z, et al. Selfsupervised learning: Generative or contrastive. IEEE Transactions on Knowledge and Data Engineering, 2021, 1(1):1–1.
[3]. Aberdam A, Litman R, Tsiper S, et al. Sequencetosequence contrastive learning for text recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 15302–15312.
[4]. Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations. In: Proceedings of the International Conference in Machine Learning (ICML), 2020. 1597–1607.
[5]. Yang M, Liao M, Lu P, et al. Reading and writing: Discriminative and generative modeling for self-supervised text recognition In: Proceedings of the 30th ACM International Conference on Multimedia (ACM MM), 2022. 4214-4223.
[6]. Guan T, Gu C, Tu J, et al. Self-supervised Implicit Glyph Attention for Text Recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013. 15285-15294.
原文作者:Tongkun Guan, Wei Shen, Xue Yang, Qi Feng, Zekun Jiang, Xiaokang Yang
撰稿:官同坤 编排:高 学
审校:殷 飞 发布:金连文
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集OCR和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-OCR或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如OCR或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()