
论文:《Event Camera Data Pre-training》
链接:https://arxiv.org/abs/2301.01928
代码:https://github.com/Yan98/Event-Camera-Data-Pre-training
背景
事件相机(Event Camera)是一种新型传感器。不同于传统的RGB相机记录的是场景的像素亮度,输出稠密、低频的图像帧,事件相机记录的是像素亮度的变化,输出稀疏、高频的事件流。与RGB相机相比,事件相机具有高的动态范围和时间分辨率,并且对光照变化和运动模糊具有鲁棒性等优势,在模式识别、同步定位与建图(SLAM)和场景理解等应用领域拥有出色的表现。
事件相机虽然也从基于图像帧的深度学习方法中得到启发,但由于缺少标准的数据集,自身进展仍受到阻碍。在小数据集的领域现状下,自监督学习框架是解决途径之一。然而,目前针对稀疏事件的自监督学习(SSL)范式的研究较少。
虽然在自监督学习中,使用RGB图像进行预训练已经取得了重大进展。然而,在事件相机数据上复制成功并非易事,因为RGB图像和事件数据之间存在域差距。RGB图像记录场景的所有像素强度,并且在空间上是密集的,而事件数据仅记录场景变化,并且是空间稀疏的。
因此,本文研究基于事件相机数据的预训练问题。我们的模型以自监督的方式,只使用成对的事件数据和RGB图像,进行预训练。用户可以将我们预先训练好的模型转移到不同的下游任务中。
主要贡献
1)对于SSL框架中的网络训练,图像增强(例如,高斯模糊、ColorJitter、RandomResizedCrop)是最重要的部分之一。稀疏事件相机数据通常可以表示为事件图像。人们可能会直接错误地对事件图像进行这些增强,例如,模糊二进制事件图像(0/1值像素)会生成无意义的事件图像。相反,我们研究了如何在转换为事件图像之前执行事件数据增强。
2)我们把学习问题表述为对比学习任务。以事件图像作为输入,可以直接执行随机掩蔽策略来对固定数量的事件补丁进行采样,以鼓励模型捕捉空间布局并加速训练。然而,事件图像在空间上是稀疏的,并且随机掩蔽将生成无信息的补丁,导致训练不稳定。为了缓解这个问题,我们提出了一种条件掩蔽策略来对信息补丁进行采样。
3)通过事件补丁,我们能够学习有区别的事件embedding ,即从相似的事件图像中提取embedding ,同时从不同的事件图像中将embedding 推开。令人惊讶的是,我们发现在事件embedding 空间中简单地执行度量学习会导致模型collapse,产生过多的相似embedding 。这是事件图像的空间稀疏性导致的。为了解决这个问题,我们发现来自成对RGB图像的embedding 可以用作regularizer,并且提出了一个embedding projection loss来解决collapse。
4)对于成对的事件数据和RGB图像,我们还旨在将匹配对的embeddings 拉到一起。这是因为有许多经过良好预训练的RGB网络可用,并且事件图像的信息量不如其配对的RGB图像。因此,RGB网络充当了我们事件网络的老师,我们提出了一种probability distribution alignment loss。
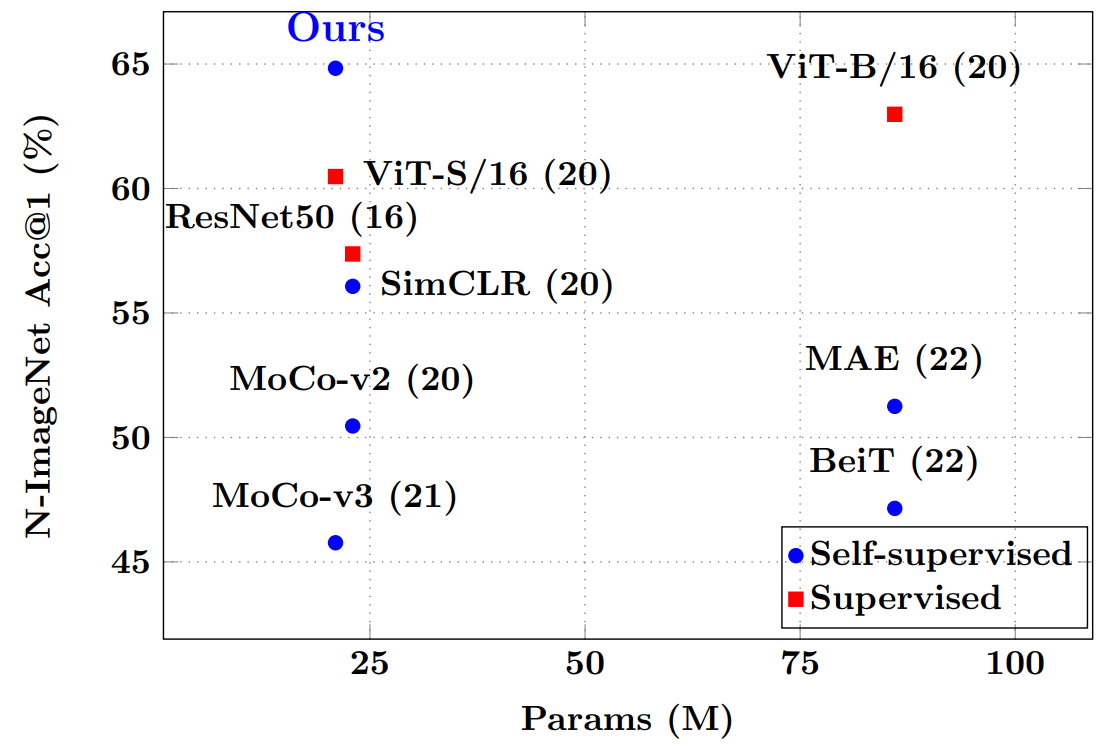
我们在标准事件数据集中实现了最先进的性能。
方法
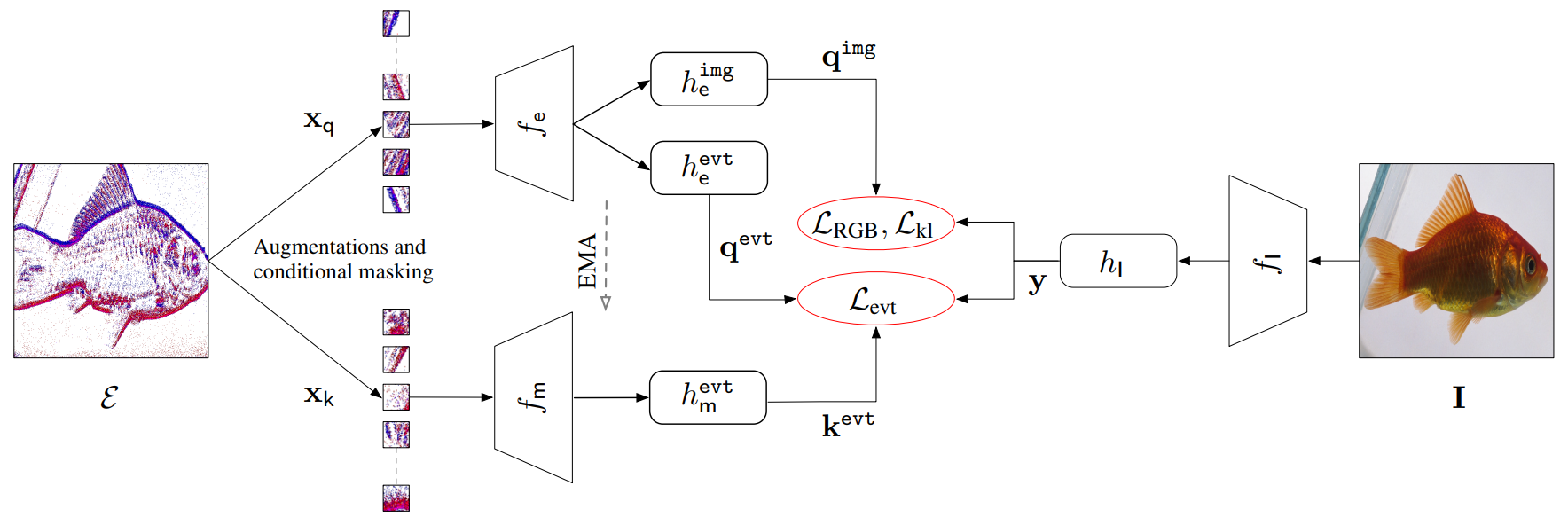
更多细节请参阅论文。
实验结果
我们在 object recognition, optical flow estimation, 和semantic segmentation三个下游任务上评估了我们的预训练模型,并取得了领先的性能。Baseline包括:
i) SOTA:我们将每项任务与最先进的方法进行比较;
ii)Training from scratch:我们使用随机权重初始化来训练最先进的方法;
iii)Transfer learning of supervised pre-training:使用ImageNet-1K数据集以有监督的方式获得最先进方法的初始权重;
iv)Transfer learning of self-supervised pre-training:最先进方法的初始权重是使用ImageNet-1K数据集以自监督的方式获得的。
Object Recognition
首先展示我们的预训练模型在大规模N-ImageNet数据集上的性能。

然后报告我们在三个小规模数据集N-Cars、N-Caltech101和CIFAR-10-DVS上的性能。

Optical Flow Estimation
在MVSEC数据集上展示了我们的光流估计性能。


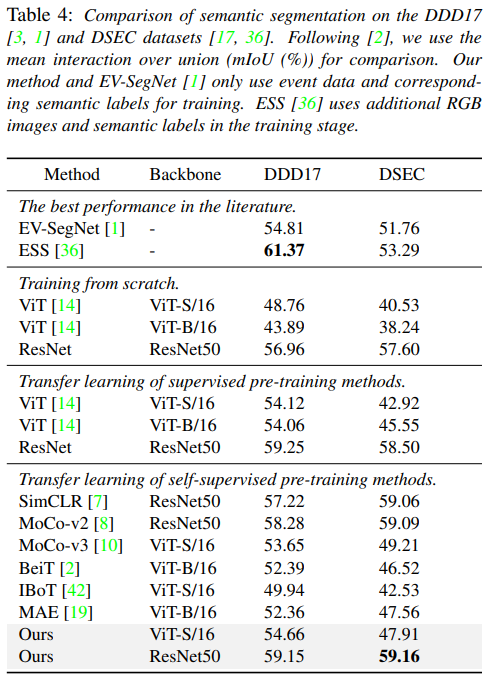
Semantic Segmentation
在DDD17和DSEC数据集上展示了我们的分割性能。

结论
在本文中,我们训练了一个用于事件相机数据的自监督学习框架,包含三个关键组成部分:
- 一系列事件数据增强
- 条件掩蔽策略
- 对比学习方法
我们的key insight是增强匹配事件图像之间以及配对事件和 RGB 图像之间嵌入的相似性,以预训练我们的模型。在下游任务(即对象识别、光流估计和语义分割)上的大量实验证明了我们的方法优于过去的方法。我们的模型有望通过使用RGB图像域的视觉语言方法来驱动事件数据网络,从而扩展到零样本学习。我们希望这篇论文能对今后的工作有所启发。