点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者介绍

张耕维
悉尼科技大学在读博士生,研究方向为持续学习
报告题目
通过慢学习和分类器对齐在预训练模型上进行持续学习
内容简介
持续学习研究的目标在于提高模型利用顺序到达的数据进行学习的能力。尽管大多数现有工作都是建立在从头开始学习的前提下的,越来越多的努力致力于融入预训练的好处。然而,如何让每个增量任务自适应地利用预训练知识,同时保持预训练提供的泛化性仍然是一个悬而未决的问题。在这项工作中,我们对预训练模型上的持续学习(CLPM)进行了广泛的分析,并将关键挑战归因于渐进式过拟合问题。观察到选择性地降低学习率几乎可以解决该问题对表示层的影响,我们提出了一种简单但极其有效的方法,称为带有分类器对齐的慢速学习器(SLCA),该方法通过对类分布进行建模并对齐来进一步改进分类层。在各种场景中,我们的方法为CLPM提供了实质性改进(例如,在Split CIFAR-100、Split ImageNet-R、Split CUB-200和Split Cars-196上分别提高了49.76%、50.05%、44.69%和40.16%),因此显著优于最先进的方法。基于这样一个强有力的基线,我们深入分析了关键因素和有希望的方向,以促进后续研究。
论文链接:https://arxiv.org/pdf/2303.05118.pdf
代码链接:https://github.com/GengDavid/SLCA
01
Background
持续学习表现为在顺序到来的数据上学习,增量式地更新模型。但是,神经网络自身的设计导致它进行持续学习时存在一个挑战,名为“灾难性遗忘问题”,这体现为模型在学习新的任务时,由于没有原来任务的数据,导致模型在旧任务上的性能显著下降。
当前主流的针对这个问题的解决方法有三类。Regularization,在网络参数更新的时候增加限制,使得网络在学习新任务的时候不影响之前的知识。Replay,在模型学习新任务的同时混合原来任务的少量数据,让模型能够学习新任务的同时兼顾旧任务。Network architecture,在模型训练的时候,独立网络中的参数,减少新知识更新对旧知识产生干扰的可能性。
另一方面,预训练模型对于下游任务的训练是非常重要的。目前最基本的方式是对训练模型进行微调(finetune)。也有参数高效调优的方式,诸如视觉提示调优、适配器调优、LoRA、SSF等,在部分单个下游任务上甚至优于微调。
02
Problem Formulation
相对于从头开始学习,当在预训练模型上进行持续学习时,θrps将在预训练模型的数据集上进行预训练,然后使用该模型在一系列新的数据集上进行更新。在引入预训练模型之后,“灾难性遗忘问题”可以延伸为“progressive overfitting”问题,它面临的挑战是如何保证从预训练数据Dpt中得到的泛化性在持续学习的过程中被很好地保留,同时还要兼顾持续学习过程中知识遗忘的问题。
03
Recent Works
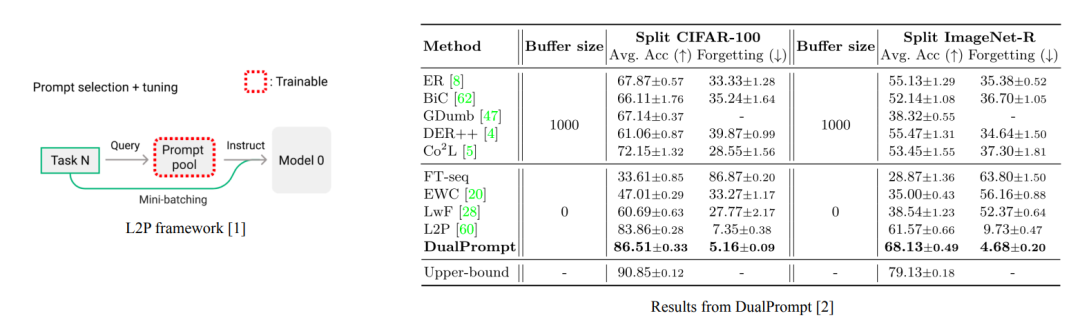
近年来的工作如L2P [1]、DualPrompt [2]引入了prompt技术,解决了模型泛化能力损失的问题。但是实际上prompt也是被共享的,仍然存在遗忘问题。从之前工作的实验结果来看,基于prompt的方法优于基于微调的方法。然而,在本工作里,我们的发现结论并非如此。
04
Continual Learning on a Pre-trained Model
Slow Learner is (Almost) All You Need?
在文章中,我们首先探讨了在持续学习的设置下,加入预训练之后基于微调的方法落后于基于提示方法的原因。我们发现关键在于学习率,传统基线的性能受到使用相对较大的学习率的严重限制。当对θrps使用小得多的学习率(0.0001,SGD优化器),而对θcls使用稍大的学习率(0.01)可以极大地提高传统基线的性能。
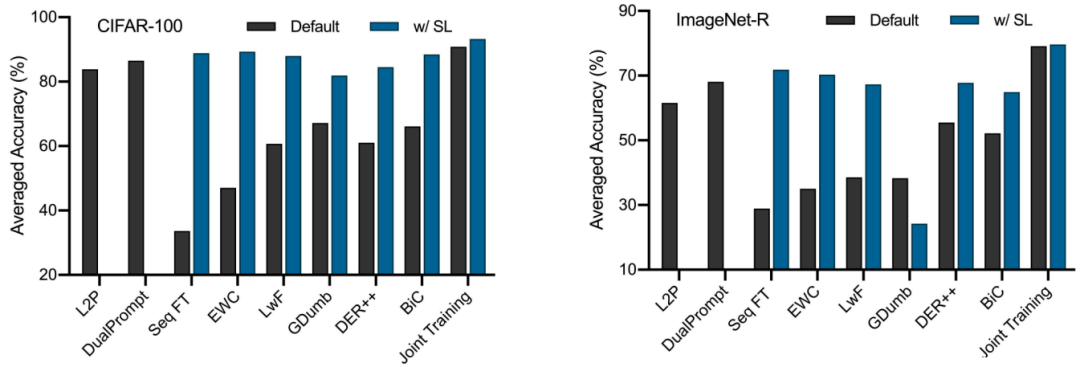
Effect of Pre-training Paradigm
另外,我们评估了预训练范式对下游持续学习的影响。如图所示,自监督预训练虽然在标签要求和上游持续学习方面更加现实,但通常会导致Seq FT与联合训练之间的性能差距比监督预训练更大。
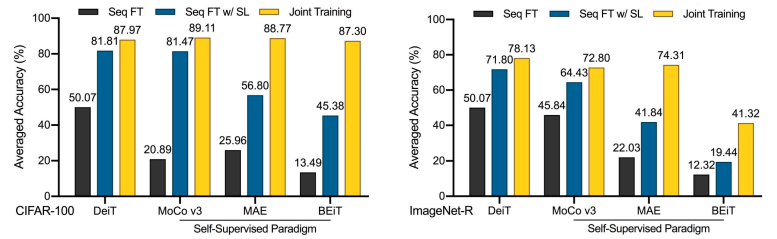
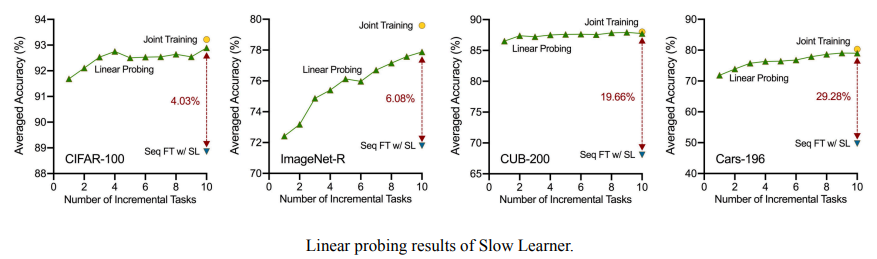
Further Evaluation of Representation
接下来,我们进一步对表示层进行验证,发现在学习完所有增量任务后,使用持续学习的表示层联合训练所有类别的额外分类器几乎可以达到整个模型的联合训练性能,并且远远优于持续学习的表示层分类器。可见在利用慢学习的方式时,表示层的progressive overfitting问题已经近乎解决,而分类器还有很大提升空间。
Slow Learner with Classifier Alignment
出现上述现象的原因在于,由于每一个任务的分类器是独立训练的,而测试时要求对所有类别给出唯一的分类结果,这就导致持续学习得到的分类器并不是最优的。所以我们进一步提出了分类器对齐模块。具体的做法是在训练过程中,每一个任务结束时计算并存储特征的mean与covariance。在测试之前,用特征的统计量构建高斯分布,根据此分布采样得到每个类别的特征,最后对分类器进行统一的进行微调,这就达到了对齐分类器的目的。
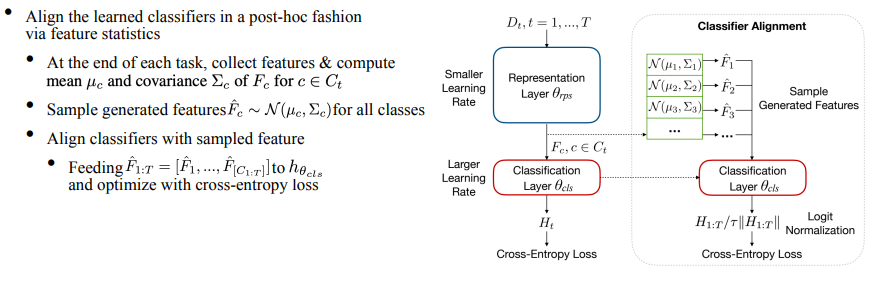
此外,由于分类器在每个任务上是训练收敛的,那么进一步训练分类器会带来过拟合的问题。具体来讲,分类器的输出logits对应每一个类有预测值,我们将其写成模乘以单位向量的形式。当用cross-entropy loss进行优化时,会显著增加模长导致过拟合,于是我们借鉴了ICML’22上logit normalization [3]的工作,加入一个动态的temperature项,使得CE loss仅改变向量的方向,从而缓解过拟合的问题。
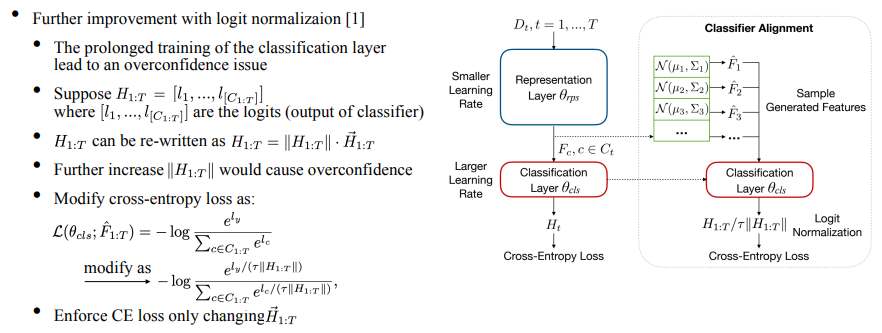
本文方法的整个算法流程如下图所示:

05
Experiment Setups
我们在4个Benchmarks上进行了验证,包括Split CIFAR-100、Split ImageNet-R、Split CUB-200、Split Cars-196。每个benchmark考虑了不同的验证维度(见下表)。我们将每个数据集分成10个任务进行训练,评价指标包括Last-Acc (主要评价指标,模型学习完最后一个任务后在所有任务上的平均accuracy)以及 Inc-Acc。

06
Overall Performance
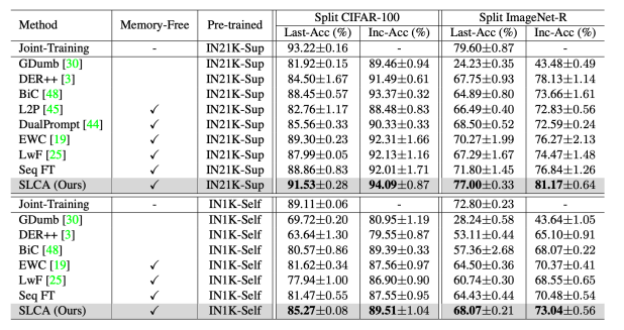
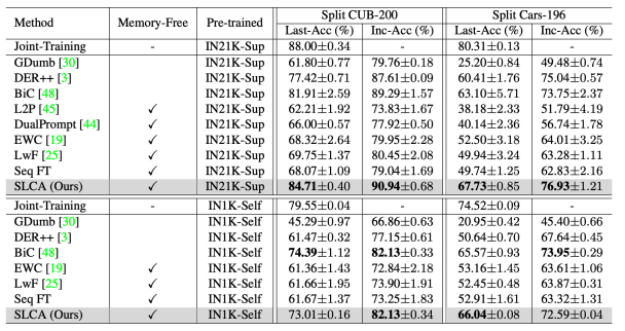
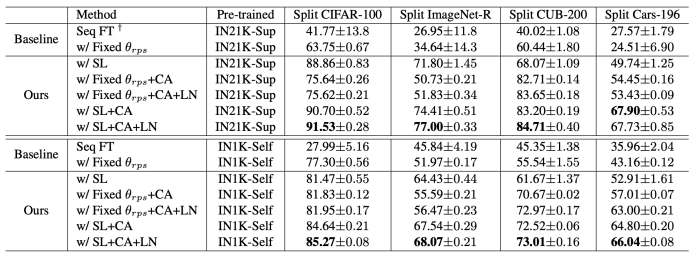
本文方法与其他基线方法对比的实验结果如下图所示,可以看到,在Split CIFAR-100和Split ImageNet-R上,SL可以显著增强持续学习的性能,借助分类器对齐以及logit归一化,我们的方法明显优于L2P与DualPrompt。同样,在细粒度分类的Split CUB-200与Split Cars-196数据集上,本文所提方法表现也较好。
07
Ablation Study
我们对提出的方法进行了广泛的消融实验,证明了更新representation层的必要性。另一方面,我们进一步证明了所提出的分类器对齐和逻辑归一化的有效性。
08
Combine with other methods
我们进一步将Classifier Alignment加入现有的方法中,进一步证明了Classifier Alignment的有效性。

09
Conclusion
首先,我们对这个研究方向进行了重新思考和基准测试,并且提供了一个简单但非常有效的基线,用于重新评估当前的进展和技术路线;其次,Slow Learner几乎可以解决表示层的渐进过拟合问题,分类器对齐进一步改进了分类层。最后,关于未来的方向,我们可以探索更多针对持续学习的预训练范式,更有效地结合参数高效的方法,以及结合上游的预训练和下游的持续学习。
10
Reference
[1] Learning to Prompt for Continual Learning, CVPR’22
[2]DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning, ECCV’22
[3] Mitigating neural network overconfidence with logit normalization, ICML’22
整理:陈研
审核:张耕维
提
醒
点击“阅读原文”跳转至00:22:07
可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1300多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!