文章目录
ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
摘要
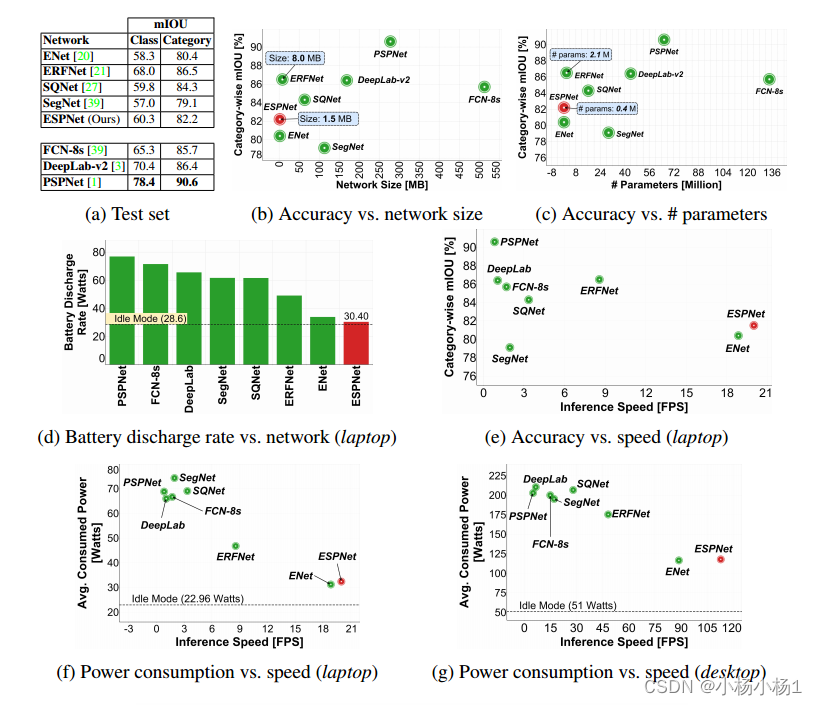
本文介绍了一种快速高效的卷积神经网络ESPNet,用于资源约束下的高分辨率图像的语义分割。ESPNet基于一种新的卷积模块——高效空间金字塔(ESP),它在计算、内存和功耗方面都是高效的。ESPNet比最先进的语义分割网络PSPNet快22倍(在标准GPU上),小180倍[1],而其分类准确率仅低8%。我们在多种语义分割数据集上对ESPNet进行了评估,包括cityscape、PASCAL VOC和乳腺活检整张幻灯片图像数据集。
代码地址
本文方法
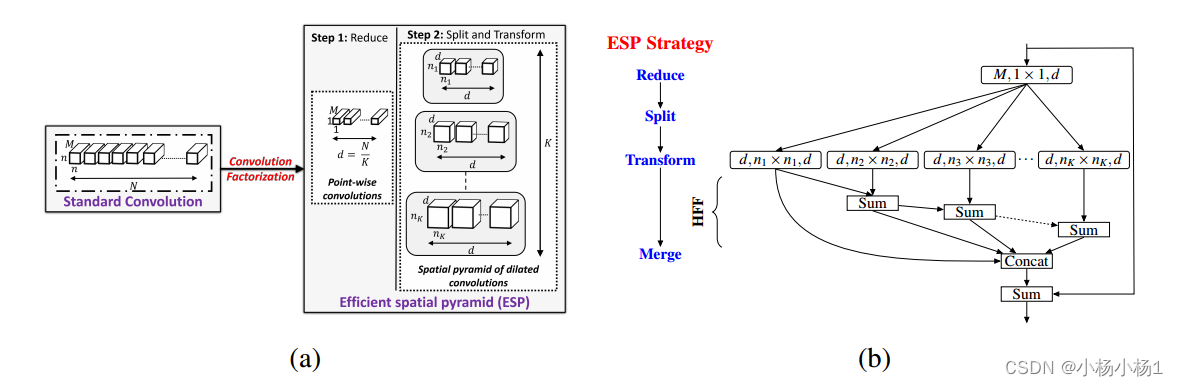
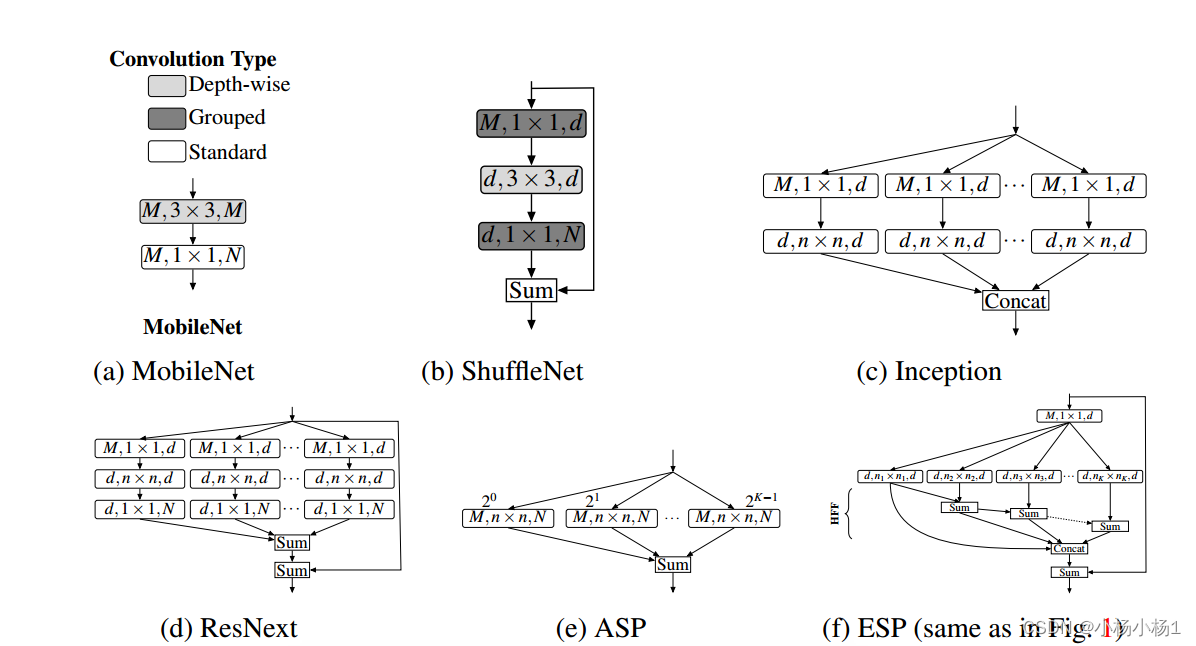
(a)将标准卷积层分解为扩展卷积的点向卷积和空间金字塔,构建高效的空间金字塔(ESP)模块。
(b) ESP模块框图。ESP模块的大有效接受场引入了网格伪影,使用分层特征融合(HFF)去除这些伪影。在输入和输出之间增加了跳跃式连接,以改善信息流。参见第3节了解更多细节。扩展卷积层表示为(#输入通道,有效核大小,#输出通道)。
扩展卷积核的有效空间维数为nk × nk,其中nk = (n−1)2k−1 + 1;k = 1;···注意,只有n × n个像素参与扩展卷积核。
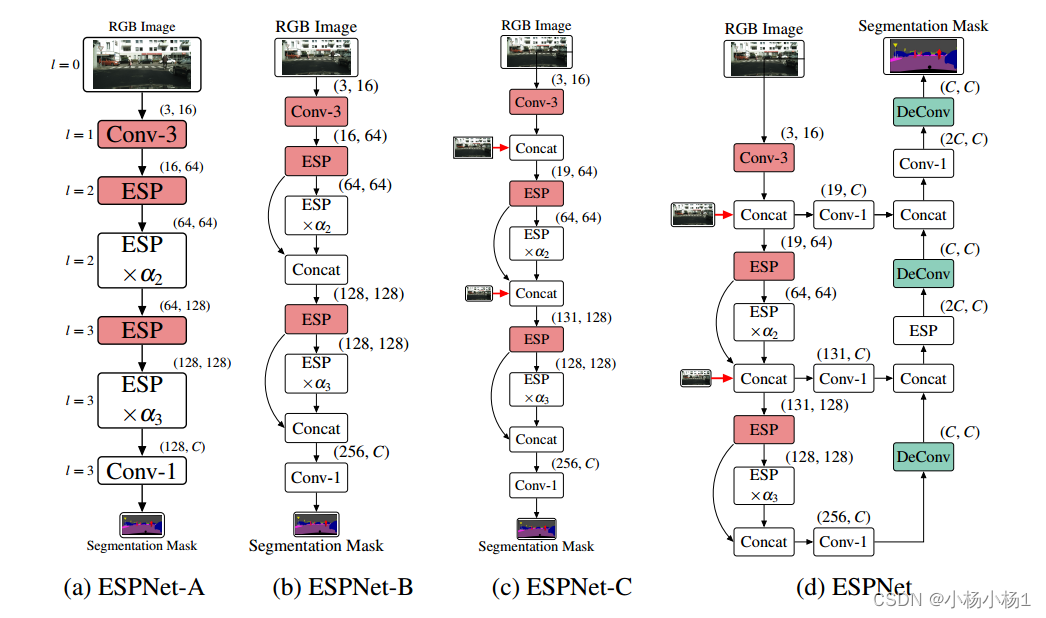
模型比较基础
实验结果

DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
摘要
Lidars和摄像头是自动驾驶中为三维检测提供补充信息的关键传感器。虽然流行的多模态方法[34,36]只是简单地用相机特征装饰原始激光雷达点云,并将其直接提供给现有的3D检测模型,但我们的研究表明,将相机特征与深度激光雷达特征融合,而不是将原始点融合,可以带来更好的性能。然而,由于这些特征经常被增强和聚合,融合中的一个关键挑战是如何有效地对齐从两种模式转换的特征。
提出了两种新技术:InverseAug,它可以逆几何相关的增强,例如旋转,以实现激光雷达点和图像像素之间的精确几何对齐
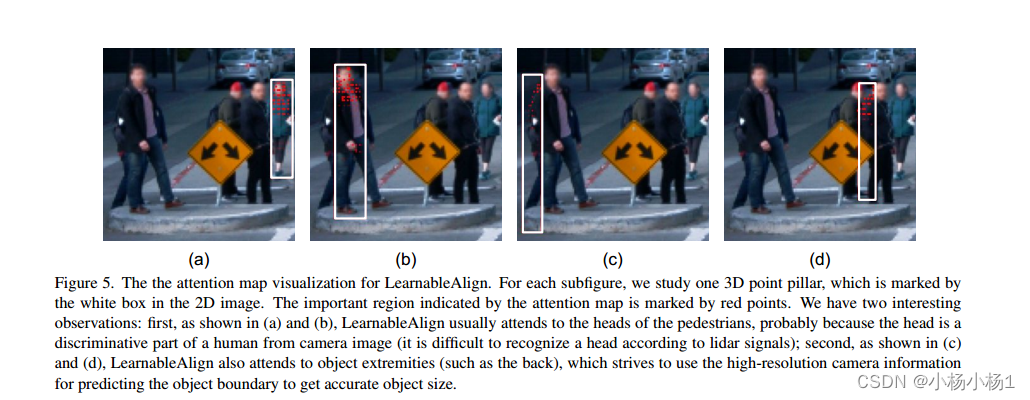
LearnableAlign,它利用交叉注意在融合过程中动态捕获图像和激光雷达特征之间的相关性。
基于InverseAug和LearnableAlign,我们开发了一系列通用的多模态3D检测模型,称为DeepFusion,比以前的方法更准确。
代码地址
本文方法
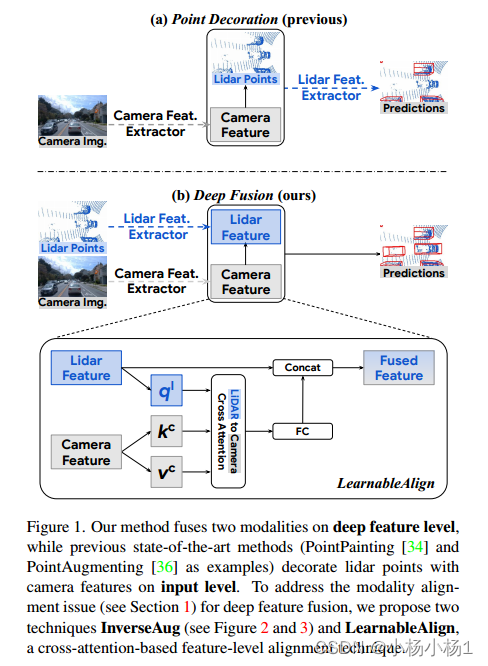
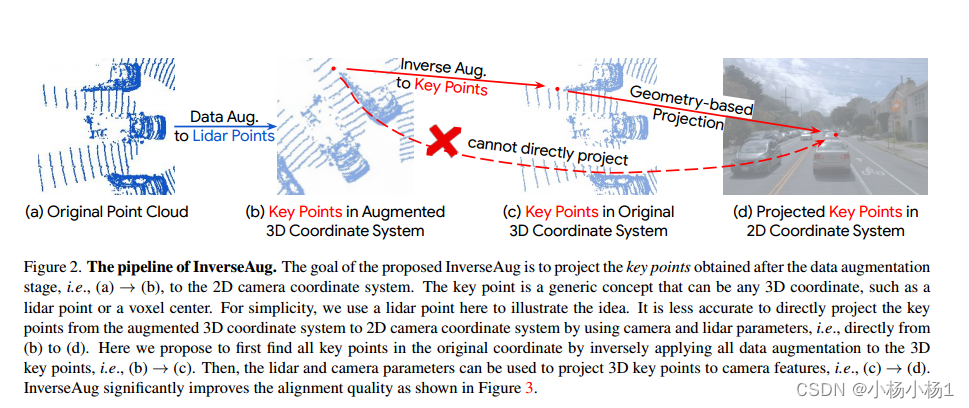
鉴于深度特征对齐的重要性,我们提出了InverseAug和LearnableAlign两种技术,从两种模式有效对齐深度特征。
InverseAug。为了在现有基准测试中获得最佳性能,大多数方法需要强大的数据增强,因为训练通常会陷入过拟合场景。从表1可以看出数据增强的重要性,其中单模态模型的精度可以提高到5.0。然而,数据增强的必要性给我们的DeepFusion管道带来了不小的挑战。具体来说,来自两种模式的数据通常使用不同的增强策略进行增强(例如,3D点云沿z轴旋转,2D图像随机翻转),这使得对齐具有挑战性。
为了解决由几何相关数据增强引起的对齐问题,我们提出了InverseAug。
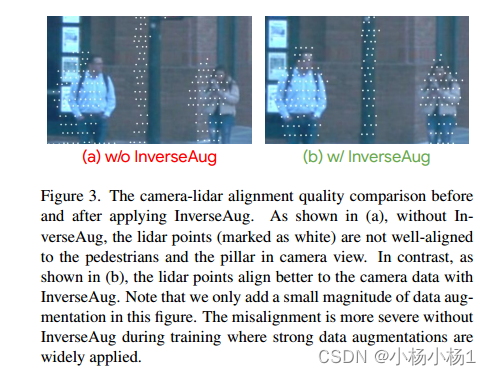
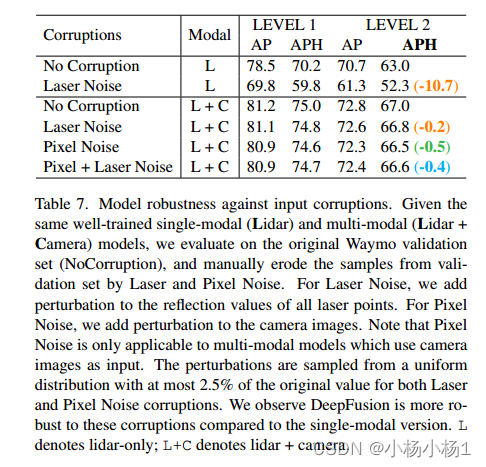
实验结果