GoogleNet系列网络原理及结构详解:从Inception-v1到v4
- 1. Google Net综述
- 2. Inception v1
- 3. Inception v2
- 4. Inception v3
- 5. Inception v4
- 5.1 论文地址
- 5.2 网络结构
- 5.2.1 Inception-resnet-v1
- 5.2.1.1 stem前馈网络
- 5.2.1.2 Inception-resnet-A结构
- 5.2.1.3 Inception-resnet-B结构
- 5.2.1.4 Inception-resnet-C结构
- 5.2.1.5 Reduction-A/B结构
- 5.2.2 Inception-resnet-v2
- 5.2.2.1 stem前馈网络
- 5.2.2.2 Inception-resnet-A结构
- 5.2.2.3 Inception-resnet-B结构
- 5.2.2.4 Inception-resnet-C结构
- 5.2.2.5 Reduction-A/B结构
- 5.2.3 Inception v4
- 5.3 核心思想
- 5.4 性能比较
- 5.5 试验结果
- 6. 总结
- 7. 这一期到这里就结束啦,大佬们的鼓励就是我更新最大的动力,欢迎点赞关注哦~
1. Google Net综述
Google Net是2014年Google团队在ImageNet比赛上提出的网络,获得了识别第一名、检测第二名的成绩;
其主要特点就是提出了一种叫做Inception的结构进行堆叠;
这种结构的主要特点就是加大了网络的深度和宽度(主要是宽度),将不同感受野大小的特征层进行堆叠,并且不增加运算量,提高了计算资源的利用效率。
相比于两年前ImageNet比赛的冠军(也是卷积神经网络的开山之作),参数少了12倍,而top-5损失率却从16.42%下降到了6.67%。
2. Inception v1
2.1 论文地址
https://arxiv.org/pdf/1409.4842.pdf
2.2 网络结构
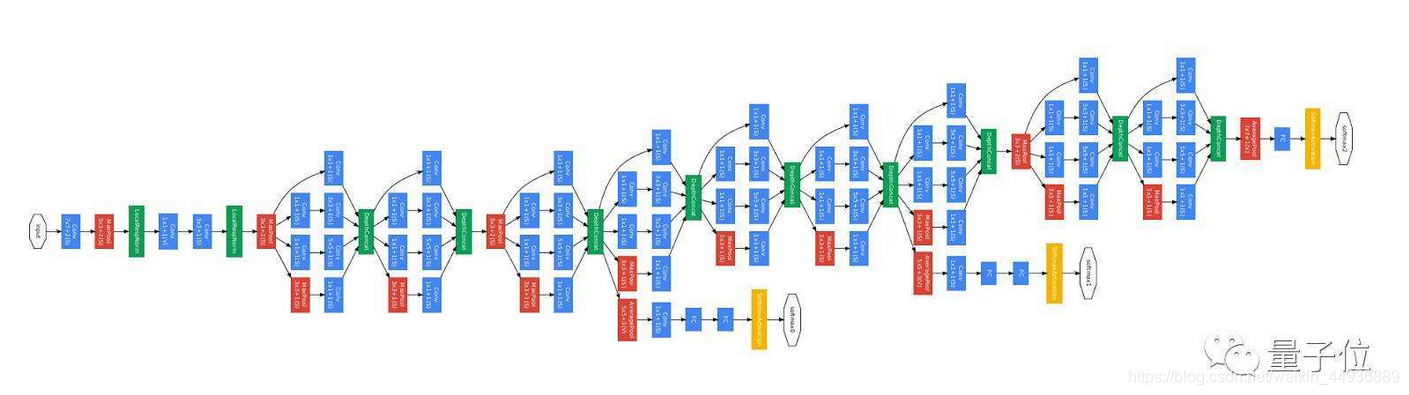
Inception v1的网络结构如图所示:
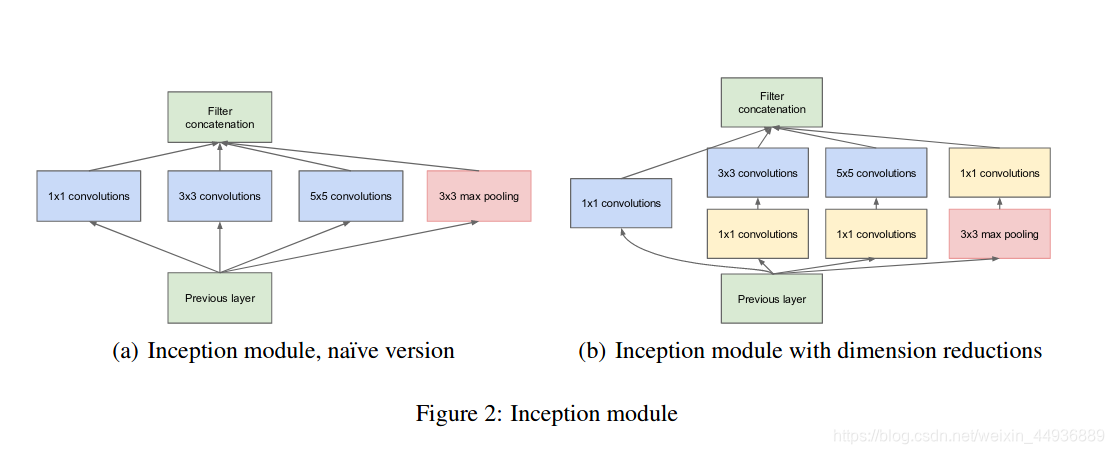
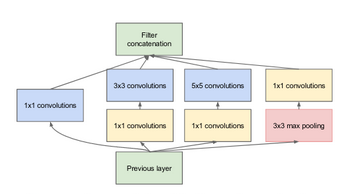
图(a)是作者提出的一个基本的Inception v1网络结构,其基本思想就是,对一个特征层分别使用不同大小卷积核进行卷积操作(包括1x1、3x3、5x5卷积层,和一个3x3的最大池化层),从而获得了不同感受野大小的特征层;最后通过一个concat堆叠,就得到了Inception v1的输出特征层;
图(b)是作者又提出的改进结构,改进的原因是由于Inception v1的输入层可能是上一个Inception v1经
过concat的输出层,深度会非常大,这样的话即使是少量的5x5的卷积操作也会导致计算量大幅增加;
因此在3x3、5x5卷积前加入了1x1卷积进行降维操作;即通过1x1卷积,在不改变特征层感受野大小的情况下,减小特征层的深度从而减少计算;并且1x1卷积后接上RELU激活也能够在一定程度上增加网络的非线性特性;
2.3 实验结果
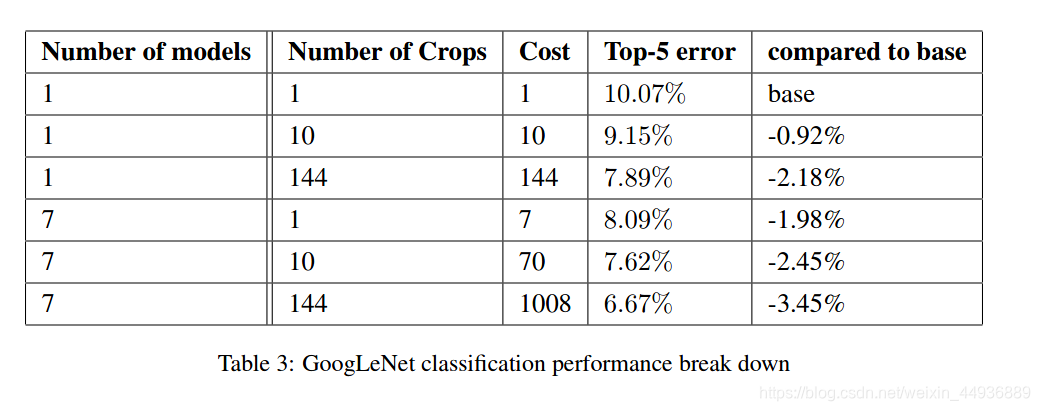 其中:
其中:
(1)Number-of-models 是融合模型的数目;
(2)Number-of-Crops 是每张检测图片裁剪区域的数目;
(3)Cost 是只检测一张图片的计算花销(模型数目x裁剪区域数目);
可以看到模型越多、取样越多,准确率就越高,但相应地计算开销就会越大。
2.4 代码实现
import tensorflow as tf
slim = tf.contrib.slim
def Incvption_v1_net(inputs, scope):
with tf.variable_scope(scope):
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu, padding='SAME',
weights_regularizer=slim.l2_regularizer(5e-3)):
net = slim.max_pool2d(
inputs, [3, 3], strides=2, padding='SAME', scope='max_pool')
net_a = slim.conv2d(net, 64, [1, 1], scope='conv2d_a_1x1')
net_b = slim.conv2d(net, 96, [1, 1], scope='conv2d_b_1x1')
net_b = slim.conv2d(net_b, 128, [3, 3], scope='conv2d_b_3x3')
net_c = slim.conv2d(net, 16, [1, 1], scope='conv2d_c_1x1')
net_c = slim.conv2d(net_c, 32, [5, 5], scope='conv2d_c_5x5')
net_d = slim.max_pool2d(
net, [3, 3], strides=1, scope='pool3x3', padding='SAME')
net_d = slim.conv2d(
net_d, 32, [1, 1], scope='conv2d_d_1x1')
net = tf.concat([net_a, net_b, net_c, net_d], axis=-1)
return net3. Inception v2
3.1 论文地址
https://arxiv.org/pdf/1502.03167.pdf
3.2 网络结构
Inception v2 并没有在结构上作出太大改变,但是首次提出了使用Batch Normalization ,即将一个batch的数据变换到均值为0、方差为1的正太分布上,从而使数据分布一致,每层的梯度不会随着网络结构的加深发生太大变化,从而避免发生梯度消失。
3.3 计算公式
 输入的是一个batch的图片(或者特征层),格式为NHWC;
输入的是一个batch的图片(或者特征层),格式为NHWC;
计算过程:
(1)计算数据的均值u;
(2)计算数据的方差σ^2;
(3)通过公式 x’=(x-u)/√(σ^2+ε)标准化数据;
(4)通过公式 y=γx’+β 进行缩放平移;
注:
(1)ε 是一个较小正数值,防止除零;
(2)其中γ和β是可训练参数;
(3)使用batch normalization时,全链接层可以不必加上bias,因为这时β就相当于加上了一个偏置值;
(4)输入测试数据时,u和σ取的是全部train_data的均值和标准差;
3.4 实验结果

可以看到使用batch-normalization之后,Top-5 Error 从6.67%下降到了4.9%。
3.5 代码实现
import tensorflow as tf
slim = tf.contrib.slim
def Incvption_v1_net(inputs, scope):
with tf.variable_scope(scope):
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu, padding='SAME',
weights_regularizer=slim.l2_regularizer(5e-3)):
net = slim.max_pool2d(
inputs, [3, 3], strides=2, padding='SAME', scope='max_pool')
net_a = slim.conv2d(net, 64, [1, 1], scope='conv2d_a_1x1')
net_b = slim.conv2d(net, 96, [1, 1], scope='conv2d_b_1x1')
net_b = slim.conv2d(net_b, 128, [3, 3], scope='conv2d_b_3x3')
net_c = slim.conv2d(net, 16, [1, 1], scope='conv2d_c_1x1')
net_c = slim.conv2d(net_c, 32, [5, 5], scope='conv2d_c_5x5')
net_d = slim.max_pool2d(
net, [3, 3], strides=1, scope='pool3x3', padding='SAME')
net_d = slim.conv2d(
net_d, 32, [1, 1], scope='conv2d_d_1x1')
net = tf.concat([net_a, net_b, net_c, net_d], axis=-1)
net = tf.layers.batch_normalization(net, name='BN')
return net4. Inception v3
4.1 论文地址
https://arxiv.org/pdf/1512.00567.pdf
4.2 网络结构

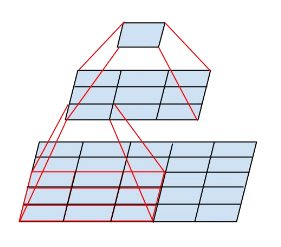
图(Figure 5)是一作者的基本思路,即一个5x5大小的卷积层和两个3x3大小的卷积层得到的特征层的感受野大小是相同的,都是5(如图);
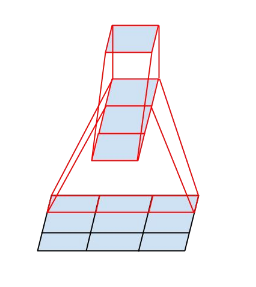
但是如果使用两个3x3卷积核代替5x5的卷积核,能够有效减小参数量;比如对于同样的深度C,一个5x5卷积核的参数量是 5^2 x C,而两个3x3卷积核的参数量是 2 x 3^2 x C;
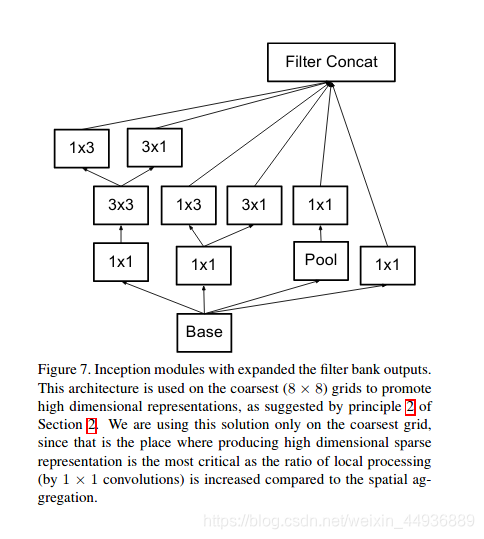
图(Figure 7)在这个思想的基础上,作者又提出了分别使用一个nx1卷积层和一个1xn卷积层,来代替nxn的卷积层,就得到了我们最终的Inception v3的结构;
4.3 补充
在整体架构方面,作者还提出了减小特征层大小、增加深度(通道数)的策略:

4.4 实验结果
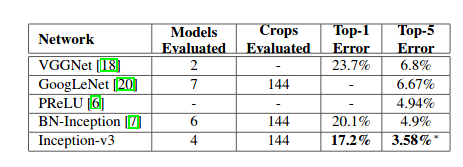
可以看到相比于Inception v2的4.9%,Inception v3的 Top-5 Error 已经下降到了3.58%。
4.5 代码实现
import tensorflow as tf
slim = tf.contrib.slim
def Incvption_v1_net(inputs, scope):
with tf.variable_scope(scope):
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu, padding='SAME',
weights_regularizer=slim.l2_regularizer(5e-3)):
net = slim.max_pool2d(
inputs, [3, 3], strides=2, padding='SAME', scope='max_pool')
net_a = slim.conv2d(net, 64, [1, 1], scope='conv2d_a_1x1')
net_b = slim.conv2d(net, 96, [1, 1], scope='conv2d_b_1x1')
net_b_1 = slim.conv2d(net_b, 128, [1, 3], scope='conv2d_b_1x3')
net_b_2 = slim.conv2d(net_b, 128, [3, 1], scope='conv2d_b_3x1')
net_c = slim.conv2d(net, 16, [1, 1], scope='conv2d_c_1x1')
net_c = slim.conv2d(net_c, 32, [3, 3], scope='conv2d_c_3x3')
net_c_1 = slim.conv2d(net_c, 32, [1, 3], scope='conv2d_c_1x3')
net_c_2 = slim.conv2d(net_c, 32, [3, 1], scope='conv2d_c_3x1')
net_d = slim.max_pool2d(
net, [3, 3], strides=1, scope='pool3x3', padding='SAME')
net_d = slim.conv2d(
net_d, 32, [1, 1], scope='conv2d_d_1x1')
net = tf.concat(
[net_a, net_b_1, net_b_2, net_c_1, net_c_2, net_d], axis=-1)
net = tf.layers.batch_normalization(net, name='BN')
return net
5. Inception v4
5.1 论文地址
https://arxiv.org/pdf/1602.07261.pdf
5.2 网络结构
作者基于ResNet的残差和思想,在Inception v3的基础上提出了Inception-resnet-v1和Inception-resnet-v2,并修改了Inception v3,提出了Inception v4的结构;
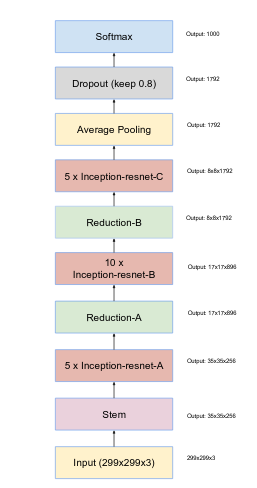
5.2.1 Inception-resnet-v1
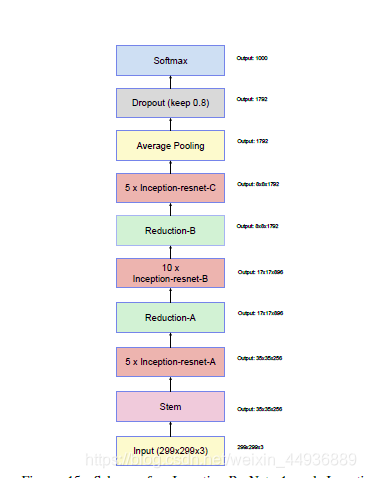
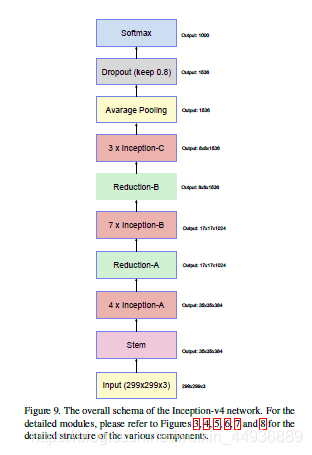
从下到上依次为:
(1)input:输入图片;
(2)stem:前馈网络;
(3)5个Inception-resnet-A结构;
(4)Reduction-A结构;
(5)10个Inception-resnet-B结构;
(6)Reduction-B结构;
(7)5个Inception-resnet-C结构;
(8)平均池化层;
(9)Dropout层;
(10)Softmax;
其中,reduction用于缩小特征层;
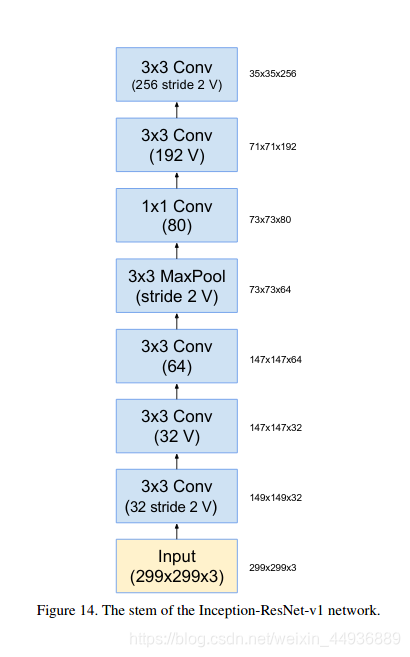
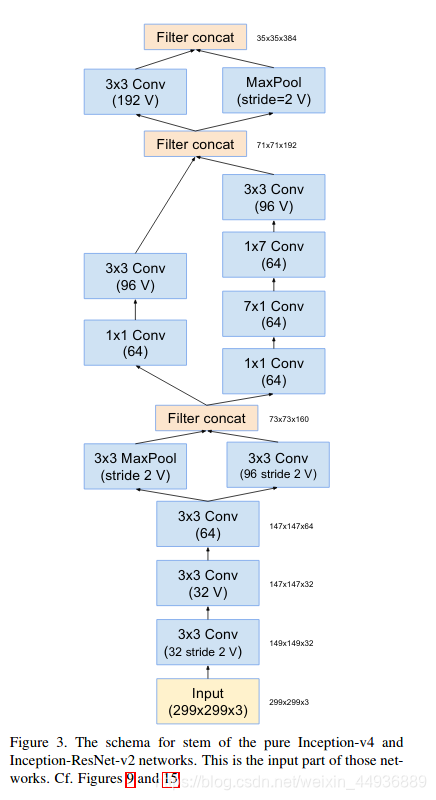
5.2.1.1 stem前馈网络
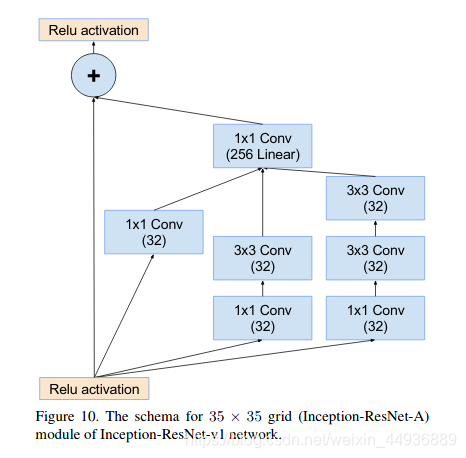
5.2.1.2 Inception-resnet-A结构
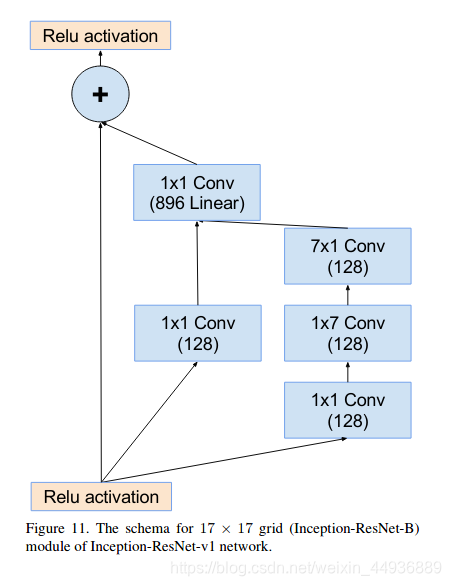
5.2.1.3 Inception-resnet-B结构
5.2.1.4 Inception-resnet-C结构
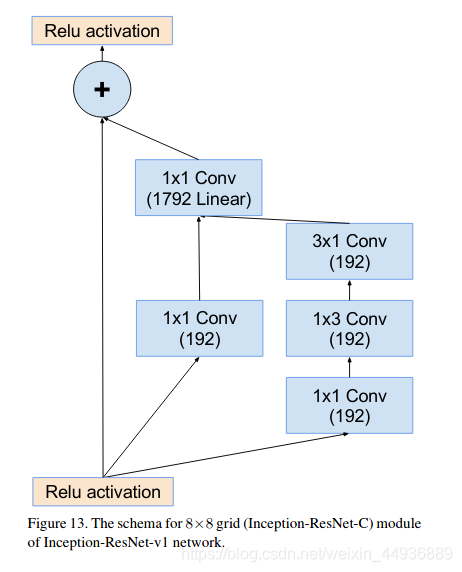
5.2.1.5 Reduction-A/B结构
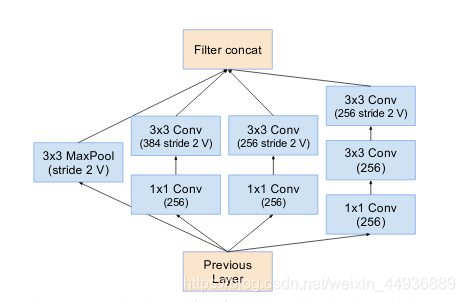
5.2.2 Inception-resnet-v2
5.2.2.1 stem前馈网络
5.2.2.2 Inception-resnet-A结构
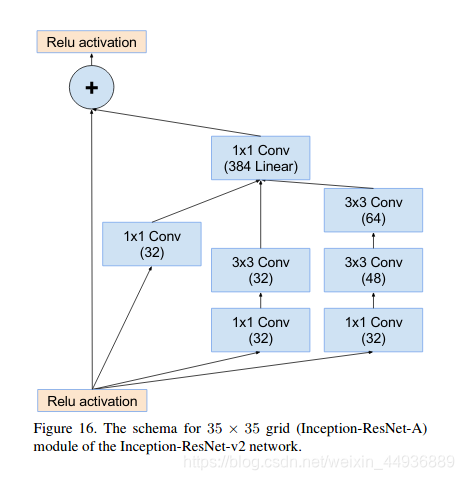
5.2.2.3 Inception-resnet-B结构
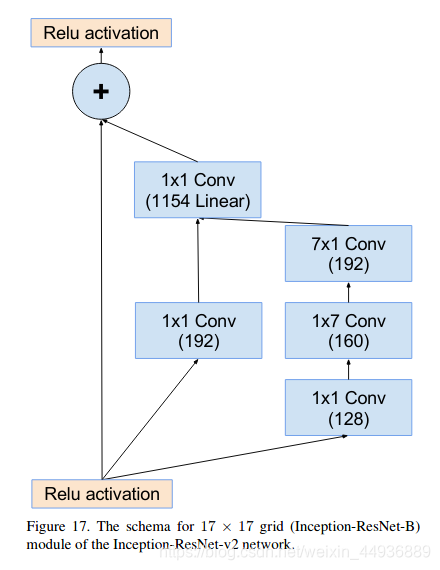
5.2.2.4 Inception-resnet-C结构
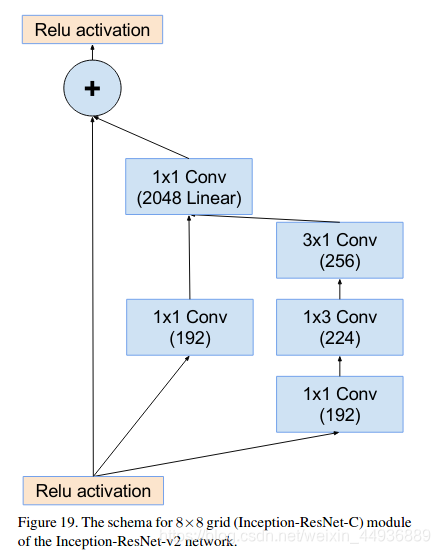
5.2.2.5 Reduction-A/B结构
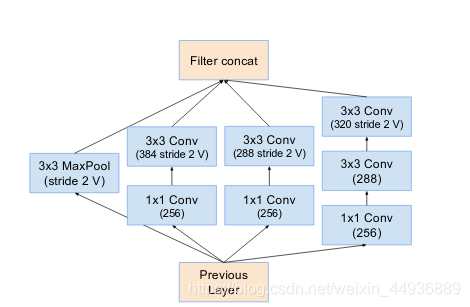
5.2.3 Inception v4
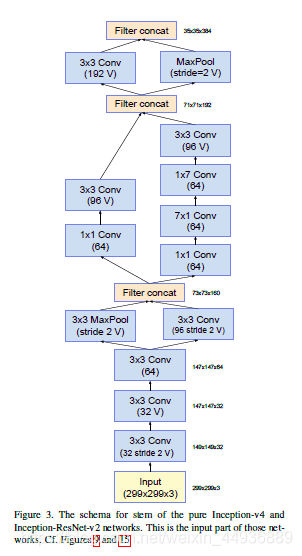
5.2.3.1 stem前馈网络
(与Inception-resnet-v2相同)
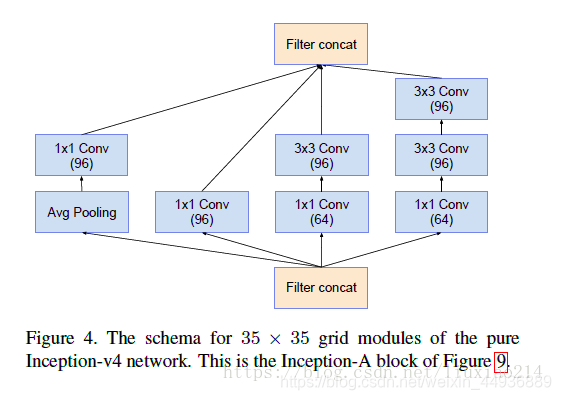
5.2.3.2 Inception-A结构
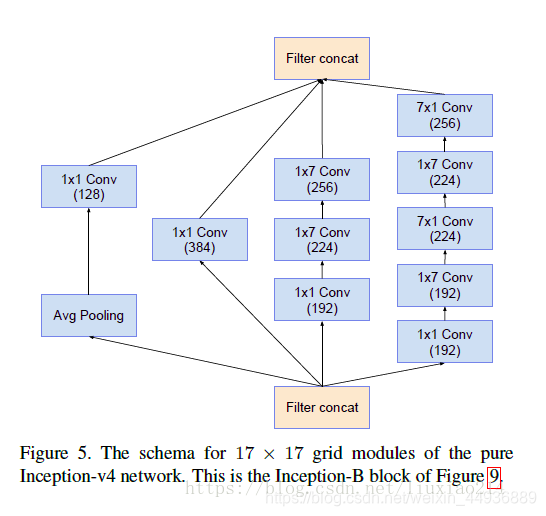
5.2.3.3 Inception-B结构
5.2.3.4 Inception-C结构
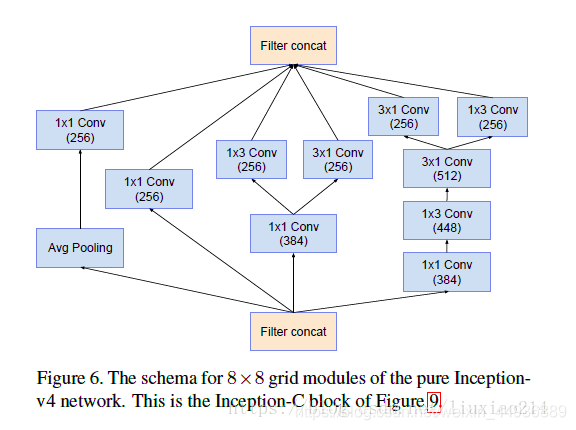
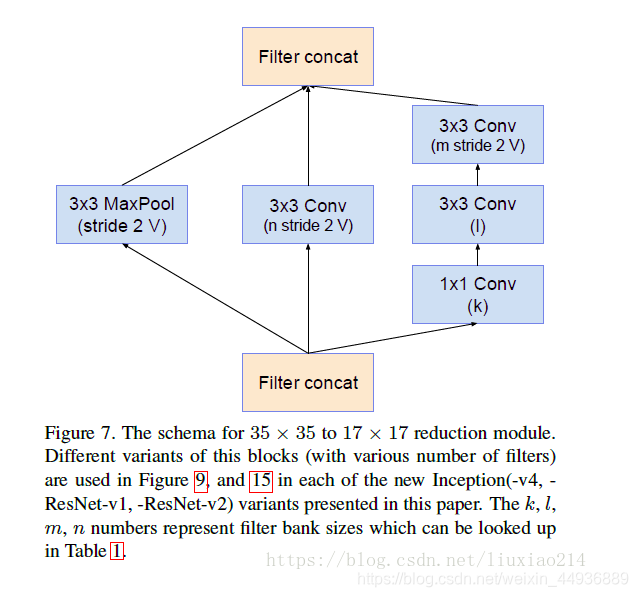
5.2.3.5 Reduction-A结构
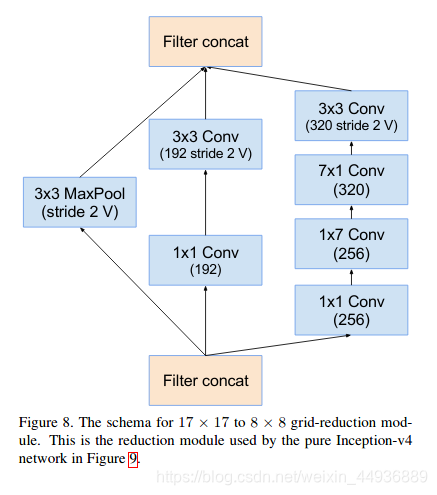
5.2.3.6 Reduction-B结构
5.3 核心思想
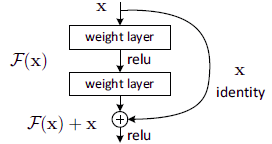
这里作者借鉴了ResNet提出的思想:假设本来要学习的函数为H(x),现在转换为F(x)+x,这样虽然效果相同,但是由于进行反向传播时x项导数始终为1,有效避免了梯度消失问题。
5.4 性能比较
- 相比于Inception v3,Inception-resnet-v1由于使用了残差单元,训练速度更快,但是测试准确率比Inception v3更快;
- 相比于Inception v4,Inception-resnet-v2训练速度快、准确率高;
5.5 试验结果
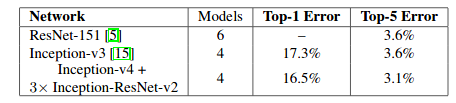
可以看到这时Top-5 Error已经下降到了3.1%。
6. 总结
AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。Inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
7. 这一期到这里就结束啦,大佬们的鼓励就是我更新最大的动力,欢迎点赞关注哦~
Ps:下一期更新一下ResNet系列,我们下期再见
