文章目录
本文主要介绍 ShuffleNet 系列方法
一、ShuffleNetV1

论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
出处:CVPR 2018 | 旷世
1.1 背景
现有的表现良好的网络结构动辄上百层,上千个通道,FLOPs(浮点计算次数)大概在十亿次,ShuffleNet 的提出是为了适应于算力较弱的移动端,以实现大概几十到几百的 MFLOPs 为目标。
现有网络的问题:
现有的高效结构如 Xception 和 ResNeXt,其实在极小的网络上的计算效率依然不太高,主要在于很耗费计算量的 1x1 卷积。
ShuffleNet 如何解决:使用 point-wise 分组卷积和 channel shuffle 两个操作,很好的降低计算量并保持准确率。这种结构能够允许网络使用更多的通道,帮助 encode 阶段提取更多的信息,这点对极小的网络非常关键。
- 使用 point-wise 卷积来降低 1x1 卷积的计算量
- 使用 channel shuffle 能够让不同通道的信息进行交互
这里再介绍几个基本概念:
- 分组卷积:AlexNet 中提出的概念,在 ResNeXt 中有使用,也就是将特征图分为 N 个组,每组分别进行卷积,然后将卷积结果 concat 起来
- 深度可分离卷积:和 MobileNet 中都有使用,也就是每个特征图使用一个卷积核来提取特征,之后使用 1x1 的卷积进行通道间的特征融合
- channel shuffle:shuffle 可以翻译为重新洗牌,也就是把不同组的 channel 再细分一下,打乱重新分组
- 模型加速:加速推理时候的速度,如剪枝、量化
1.2 方法
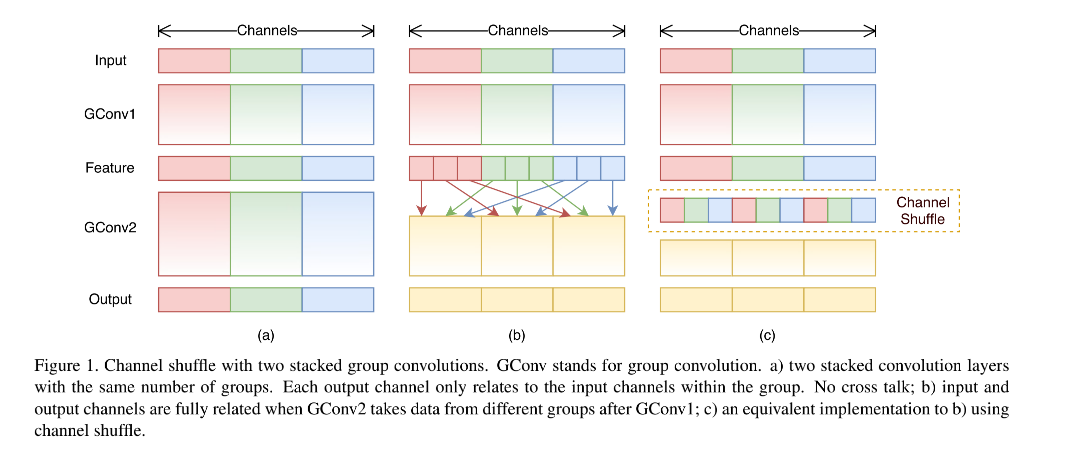
1.2.1 Channel shuffle for group convolutions
Xception 使用了深度可分离卷积, ResNeXt 使用了分组卷积,但都没有考虑 1x1 的瓶颈层,该瓶颈层也会带来很大的计算量。
ResNeXt 中在分组卷积中使用的卷积大小为 3x3,对每个残差单元,逐点的卷积占了 93.4%。在极小的网络中,这样大的占比就难以降低网络计算量的同时来提升效果了。
为了解决上面 1x1 瓶颈层的问题,要怎么做呢:
- 一般会考虑使用更稀疏的通道,如在 1x1 内部也使用分组卷积。但是这样也会有问题,因为 1x1 是瓶颈层,所以该层的输出是下一层 block 的输入,如果在 1x1 卷积中使用分组策略,则 1x1 瓶颈层的输出特征的每个通道并没有接收其他前面的所有输入,只接收了一小部分输入的特征(如图 1a)。
- 所以,如何解决图 1a 的问题呢,可以使用图 1b 的方法,将每个 group 里边再细分,细分后放入不同的组内,这个过程可以叫做 channel shuffle,打乱后如图 1c 所示。
1.2.2 ShuffleNet unit
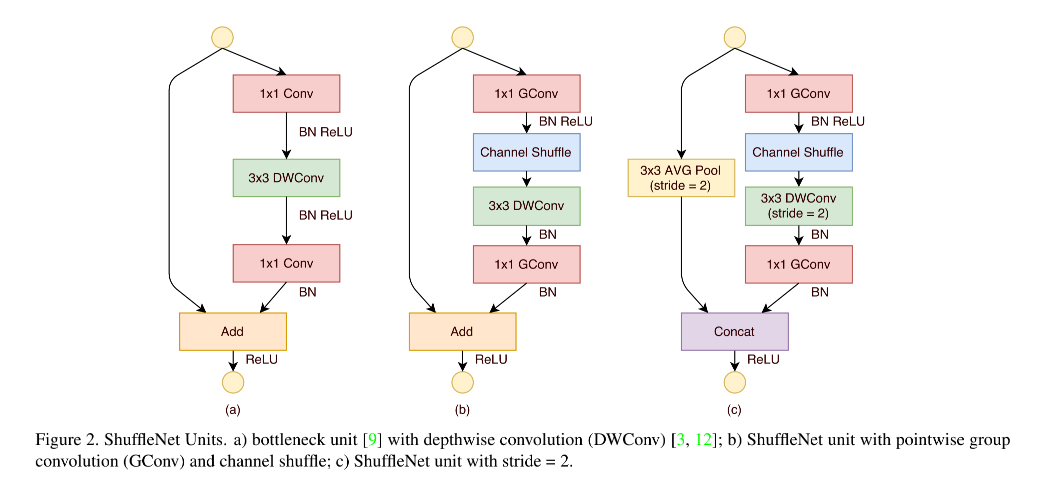
作者又针对小网络提出了 ShuffleNet unit:
从如图 2a 的 bottleneck 单元开始,在 bottleneck 特征图上,使用 3x3 深度卷积,然后使用 point-wise group convolution + channel shuffle,来构成 ShuffleNet unit,如图 2b 所示
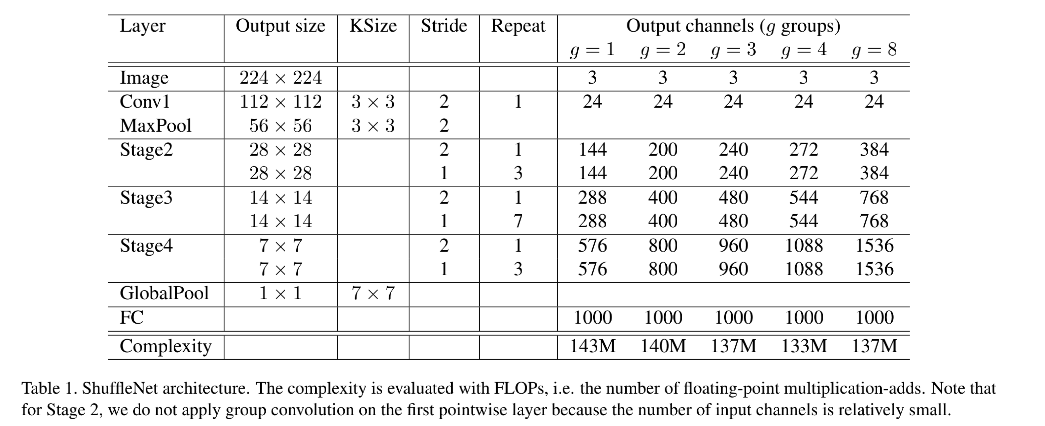
1.2.3 网络结构
ShuffleNet 结构如图 1 所示,是一个由 ShuffleNet units grouped 堆叠起来的 3 stage 网络,在每个 stage 的开头,stride = 2。
- 每个 stage 的超参数都是相同的
- 下一个 stage 的的输出是上一个 stage 通道数的 2 倍
- bottleneck channels 的个数是 ShuffleNet unit 的输出通道数的 1/4
- 在 ShuffleNet unit 内,group number 数 g g g 控制着 point-wise convolution 的稀疏程度,表 1 做了实验,验证了在胸膛计算量情况下,不同的 g g g 的效果。大的 g g g 的输出通道更多,能够帮助 encode 更多的信息,但也可能由于输入特征有限,导致单个卷积滤波器的退化
- 为了针对不同的需求设计不同大小的网络,作者还对通道数设计了缩放因子 s s s,表 1 中的结构为 ShuffleNet 1x,ShuffleNet s s sx 则表示将滤波器个数扩充 s s s 倍,同时计算量会是 ShuffleNet 1x 的 s 2 s^2 s2 倍。
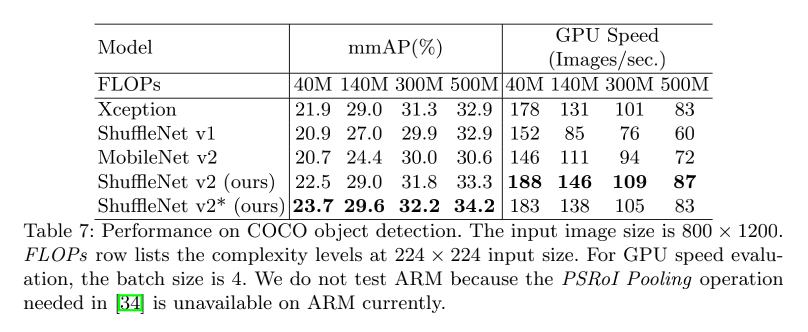
1.3 效果
channel shuffle 的效果:
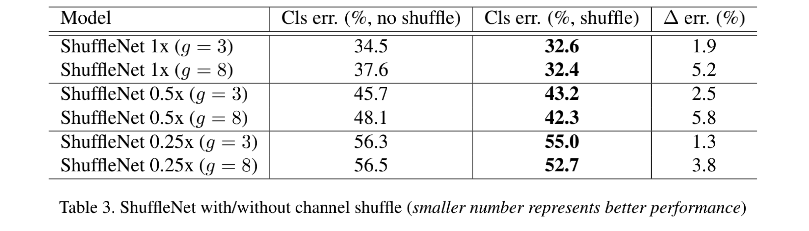
分类效果:

和 MobileNet 的对比:
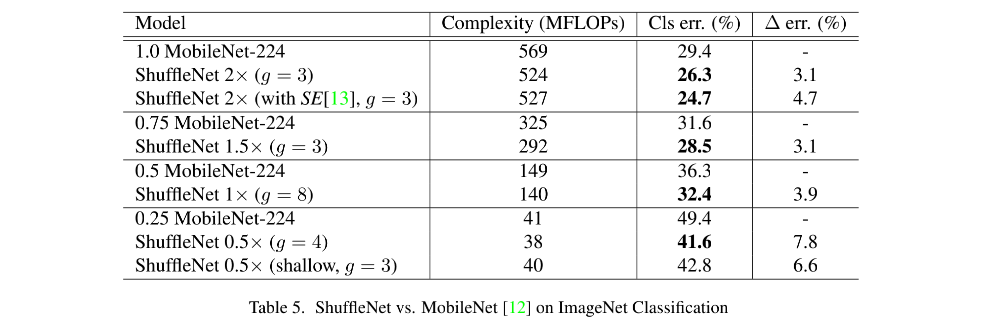
二、ShuffleNetV2

论文:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
出处:ECCV 2018 | 旷世 清华
贡献:
- 提出了更应该使用直接的效率度量方法(如速度、耗时等)
- 在 V1 的 channel shuffle 的基础上,又提出了 channel split,增强特征的重用性的同时也减少了计算量
- 提出了 4 条设计高效网络的方法:使用输入输出通道相同的卷积、了解使用分组卷积的代价(分组越多,MAC 越大)、合理的设定分组格式、降低网络并行的分支(并行越多 MAC 越大)、减少逐点运算
2.1 背景
FLOPS:每秒浮点计算数量
FLOPs:浮点计算数量
MAC:Memory Access Cost,内存访问成本,MAC 描述了这个复杂的网络到底需要多少参数才能定义它,即存储该模型所需的存储空间
目前卷积神经网络的设计大都依据计算量,也就是 FLOPs,浮点计算次数,但 FLOPs 不是一个直接的衡量方式,是一个大概的预估,而且也可能和我们更关系的直接衡量方法(如速度和时间)得到的结果不等,且实际模型的的速度等还依赖于内存消耗、硬件平台等,所以 ShuffleNetV2 会在不同的硬件平台上更直接的来评估,而非只依靠 FLOPs。
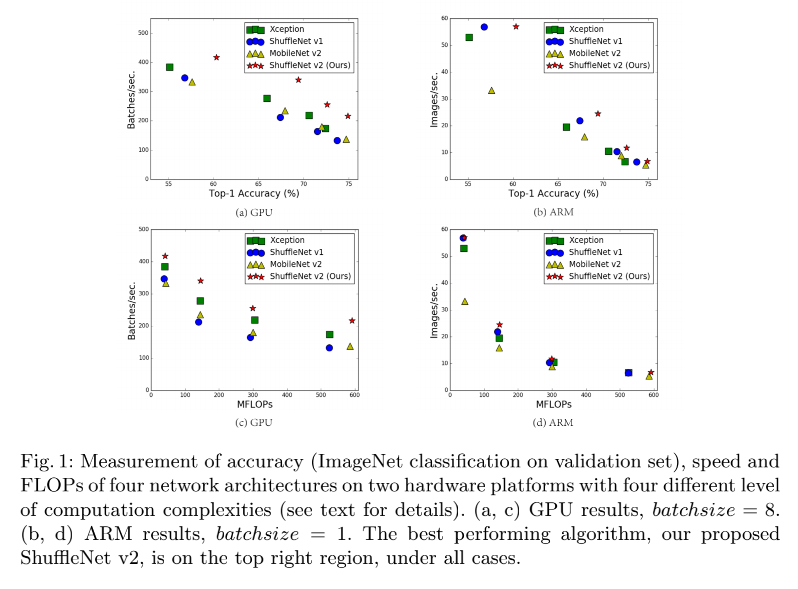
如图 1 所示,MobileNet v2 是 NASNET-A 快很多,但 FLOPs 却基本没差别,也证明了有相同 FLOPs 的模型可能速度有很大的不同,所以,只使用 FLOPs 作为衡量指标不是最优的。
FLOPs 和 speed 之间的不对等可能有以下两个原因:
- 第一个原因:很多对速度有影响的因子没有被考虑到 FLOPs 中去,如内存访问成本 (MAC)。在某些操作 (如组卷积) 中,这种代价构成了运行时的很大一部分。它可能会成为具有强大计算能力的设备的瓶颈,例如 gpu。在设计网络体系结构时,不应该简单地忽略这个代价。另一个是并行度。在相同的 FLOPs 下,具有高并行度的模型可能比另一个具有低并行度的模型快得多。
- 第二个原因:FLOPs 相同的一些操作的运行速度可能不同。如 tensor 分解,能够加速矩阵乘法,但也有研究证明分解后可能在 GPU 上运行更慢,虽然 FLOPs 降低了 75%。这是由于新版的 CUDNN 针对 3x3 卷积进行了优化,所以不一定 3x3 的卷积就比 1x1 的卷积慢。
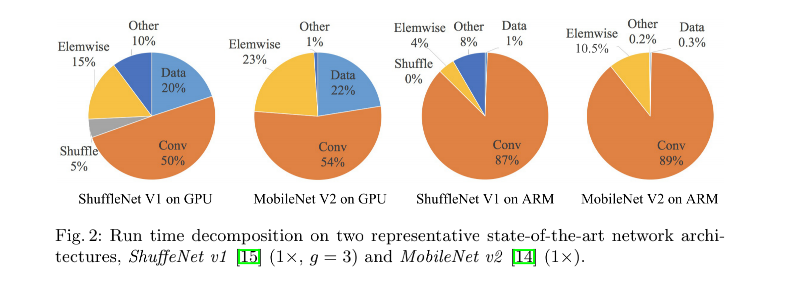
如下图 2 所示,FLOPs 主要衡量卷积部分,虽然这一部分可能很耗时,但其他的如 data shuffle、element-wise operation(AddTensor、ReLU)等等也同样很耗费时间,所以 FLOPs 不应该作为唯一的衡量指标。
基于上面的分析,作者认为一个方法高效与否应该从下面两个方面来衡量:
- 使用直接方法来度量效果而非间接方法
- 所以的度量要在对应的硬件设备上进行
2.2 方法
2.2.1 高效网络的设计准则
ShuffleNetV2 首先提出了 4 条设计高效网络的方法:
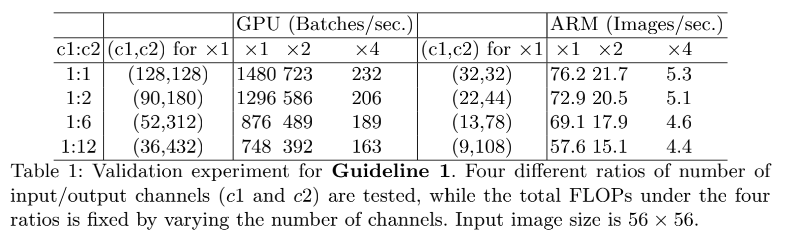
- G1:Equal channel width minimizes memory access cost (MAC):当卷积层的输入特征矩阵与输出特征矩阵 channel 相等时 MAC 最小 (保持FLOPs不变时)
- G2: Excessive group convolution increases MAC:当 GConv 的 groups 增大时(保持FLOPs不变时),MAC 也会增大,所以建议针对不同的硬件和需求,更好的设计对应的分组数,而非盲目的增加
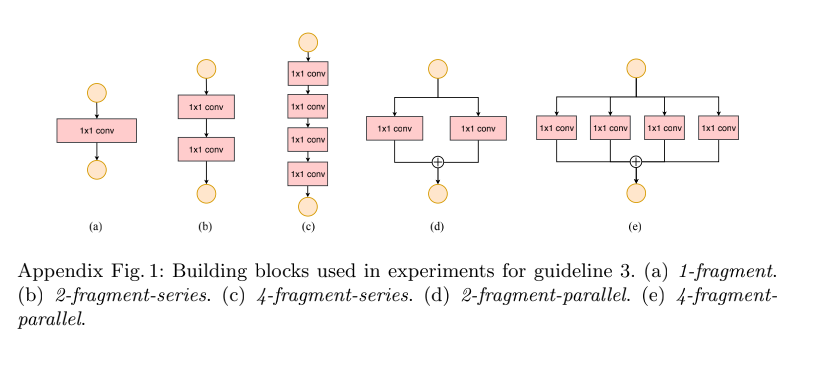
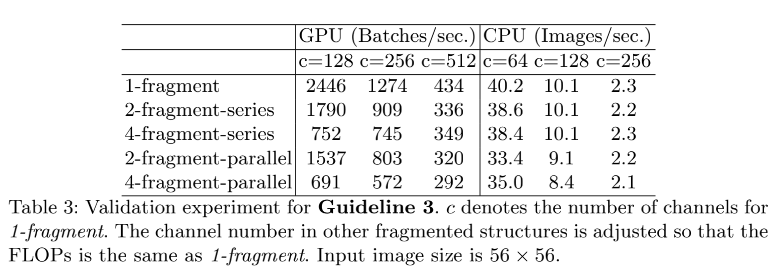
- G3: Network fragmentation reduces degree of parallelism:网络设计的碎片化程度(或者说并行的分支数量)越高,速度越慢(Appendix Fig 1)
- G4:Element-wise operations are non-negligible:Element-wise操作,即逐点运算,带来的影响是不可忽视的,轻量级模型中,元素操作占用了相当多的时间,特别是在GPU上。这里的元素操作符包括 ReLU、AddTensor、AddBias 等。将 depthwise convolution 作为一个 element-wise operator,因为它的 MAC/FLOPs 比率也很高
1、G1:输入输出通道相同的时候,MAC 最小,模型最快
很多网络都使用了深度可分离卷积,但其中的逐点卷积(1x1 卷积)计算量很大,1x1 卷积的计算量和其输入通道数 c 1 c_1 c1 和输出通道数 c 2 c_2 c2 有很大的关系,1x1 卷积的 FLOPs = h w c 1 c 2 hwc_1c_2 hwc1c2
假设内存很大,则内存消耗 MAC = h w ( c 1 + c 2 ) + c 1 c 2 hw(c_1+c_2)+c_1c_2 hw(c1+c2)+c1c2,和输入输出通道数相关性非常大,也有 M A C > = 2 ( h w B ) + B h w MAC >= 2 \sqrt(hwB) + \frac{B}{hw} MAC>=2(hwB)+hwB, MAC 的下线是由 FLOPs 决定的,当 1x1 卷积的输入输出通道数量相同的时候,MAC 最小。
如表 1,当固定 FLOPs 时,输入输出通道相同的时候,MAC 最小,模型最快。
2、G2:当分组卷积的分组数增大时(保持FLOPs不变时),MAC 也会增大,所以建议针对不同的硬件和需求,更好的设计对应的分组数,而非盲目的增加
1x1 分组卷积的 MAC 和 FLOPs 如下:
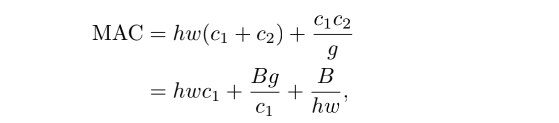
- g g g 是分组数量, B = h w c 1 c 2 / g B = hwc_1c_2/g B=hwc1c2/g 是 FLOPs
- 给定固定的输入尺度和 FLOPs,MAC 会随着分组数量的增大而增大
- 所以建议针对不同的硬件和需求,更好的设计对应的分组数,而非盲目的增加
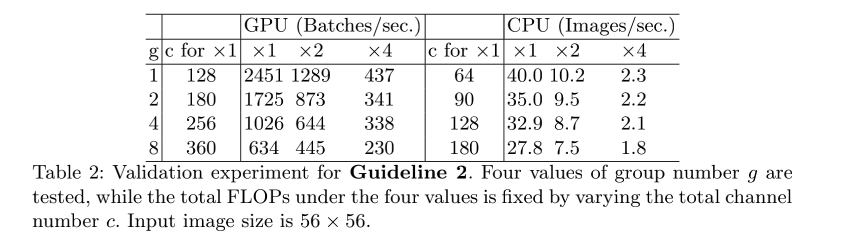
3、G3:网络设计的碎片化程度越高(或者说并行的分支数量越多),速度越慢(Appendix Fig 1)
如表 3 所示,4 分支并行的网络约比单分支的网络慢 3x
4、G4:不要过多的使用逐点运算
如图 2,点乘操作会耗费很长时间,点乘会出现在 ReLU、AddTensor、AddBias 等操作中,虽然 FLOPs 很低,但 MAC 很高。深度可分离卷积也有点乘操作,所以也有高的 MAC/FLOPs ratio。
比如使用 ResNet 中的 bottleneck (1x1 + 3x3 + 1x1,ReLU,shortcut)做实验,将 ReLU 和 shortcut 去掉后,提升了 20% 的速度。
所以基于上述准则,设计高效网络要遵循如下准则:
- 使用输入输出通道相同的卷积
- 了解使用分组卷积的代价,合理的设定分组格式
- 降低网络并行的分支
- 减少逐点运算
2.2.2 ShuffleNet V2 的结构
1、首先回顾一下 ShuffleNet V1 的设计
ShuffleNetV1 如图 3a 和 3b
使用了 channel shuffle 的操作,来降低 1x1 卷积带来的复杂计算
但由于 pointwise 分组卷积和 bottleneck 结构会提升 MAC(G1 和 G2),其计算消耗是不可忽略的,尤其是小模型。
使用大的分组数会不符合 G3
残差连接中的逐点相加操作也会带来大量计算,不符合 G4
所以,如果想要同时实现高容量和计算效率,关键问题是如何使用大量且等宽的 channel,而不是很多的分组
2、ShuffleNet V2 中提出了 Channel Split:在 block 刚开始的时候,就将 channel 一分为二
为了实现上述的目标,V2 引入了 channel split,如图 3c 为基本结构,下采样时候的结构如图 3d
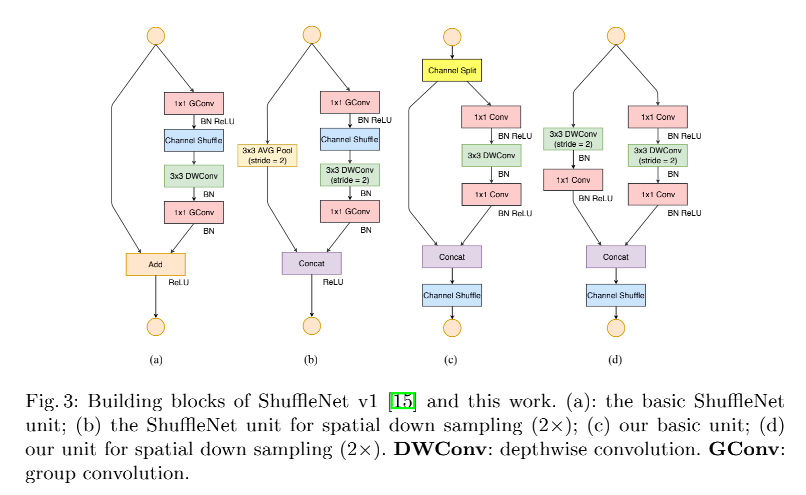
- 在每个 unit 的起始,将输入的 c c c 维通道分为两份,也就是两个分支
- 为了遵守 G3,一个分支保留恒等映射
- 为了遵守 G1,另外一个分支使用 3 层卷积,且输入输出相同
- 为了遵守 G2,两个 1x1 卷积不使用 group-wise,因为分成两个分支,原理上已经进行了分组
- 得到两个分支的输出后,concat 起来,然后 channel 数量就和输入相同了(遵守了 G1),然后使用 channel shuffle 来让两个分支的信息进行交互
- channel shuffle 之后,就开始了下一个 unit
- 要注意的是,这里没有使用 V1 中的相加操作,ReLU 和深度可分离卷积也只存在于一个分组中
- 为了遵循 G4,将 concat、channel shuffle、channel split 这三个操作进行了 merge,合并成了一个 element-wise 操作
- 下采样时,unit 会进行修改,如图 3d,移除了 channel split,输出的 channel 数量会翻倍
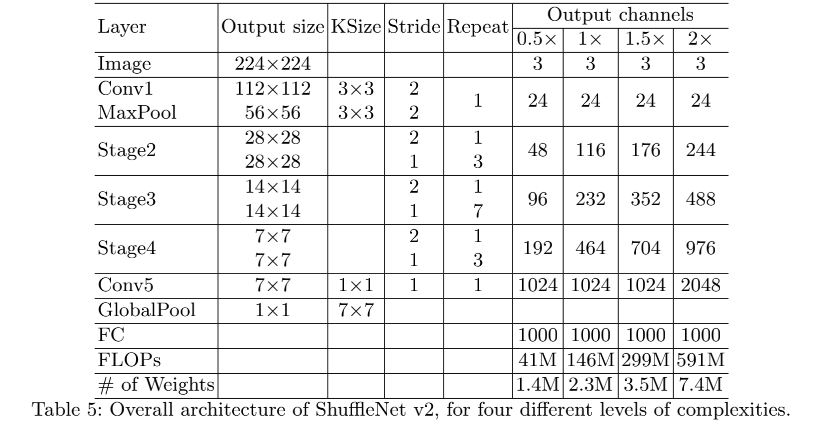
- 整个 V2 的网络结构是重复的堆叠起来的,为了简化, c ′ = c / 2 c'=c/2 c′=c/2,整个网络结构和 V1 也很类似,只有一个不同点,就是在 global average pooling 之前加了一个 1x1 卷积,用于特征混合。
3、ShuffleNetV2 网络准确性的分析
ShuffleNetV2 不仅仅高效,而且准确性也有保证,主要有两个原因:
- 每个 block 都是高效的,这就允许网络使用更大的 channel 数量
- 每个 block 中,只使用约一半的 channel 经过本个 block 的层进行特征提取,另外一半的 channel 直接输入下一个 block,可以看做特征重用
2.3 效果