MHSA注意力机制
MHSA是多头自注意力机制(Multi-Head Self-Altention),是自然语言处理领域中用于语言模型中的一种特殊机制。它能够让模型在预测下一个词的时候,更好地关注句子中不同位置的词,以适应不同的语言场景。MHSA的核心思想是将一个线性变换分成多个头,每个头执行自注意力操作,并将所有头的输出拼接在一起作为最终的表示。在自注意力操作中,每个头都计算出一个注意力矩阵,该矩阵在整个序列中对不同位置的词进行加权求和,以得到每个位置的表示。MHSA的应用已被证明在许多自然语言处理任务中具有很好的效果。
论文地址:MHSA注意力机制原论文
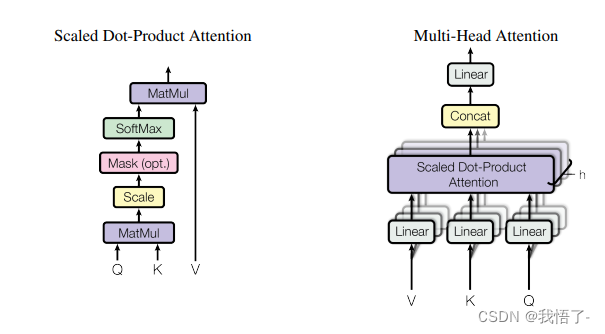
代码实现:
import torch
import torch.nn as nn
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]),
requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]),
requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k) # 1,C,h*w,h*w
c1, c2, c3, c4 = content_content.size()
if self.pos:
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(
0, 1, 3, 2) # 1,4,1024,64
content_position = torch.matmul(content_position, q) # ([1, 4, 1024, 256])
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2)) # 1,4,256,64
out = out.view(n_batch, C, width, height)
return out
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
mhsa = MHSA(n_dims=512)
output = mhsa(input)
print(output.shape)