BAM注意力机制
瓶颈注意模块(BAM):关注深度神经网络中注意力机制的影响,提出了一个简单而有效的注意力模块,即瓶颈注意模块(BAM),可以与任何前馈卷积神经网络集成,沿着两个不同的路径(通道和空间)推断注意力映射。 将模块放在模型的每个瓶颈处(特征映射产生降采样),构建一个具有多个参数的分层注意,可以与任何前馈模型以端到端方式进行训练。
论文地址:https://arxiv.org/pdf/1807.06514.pdf
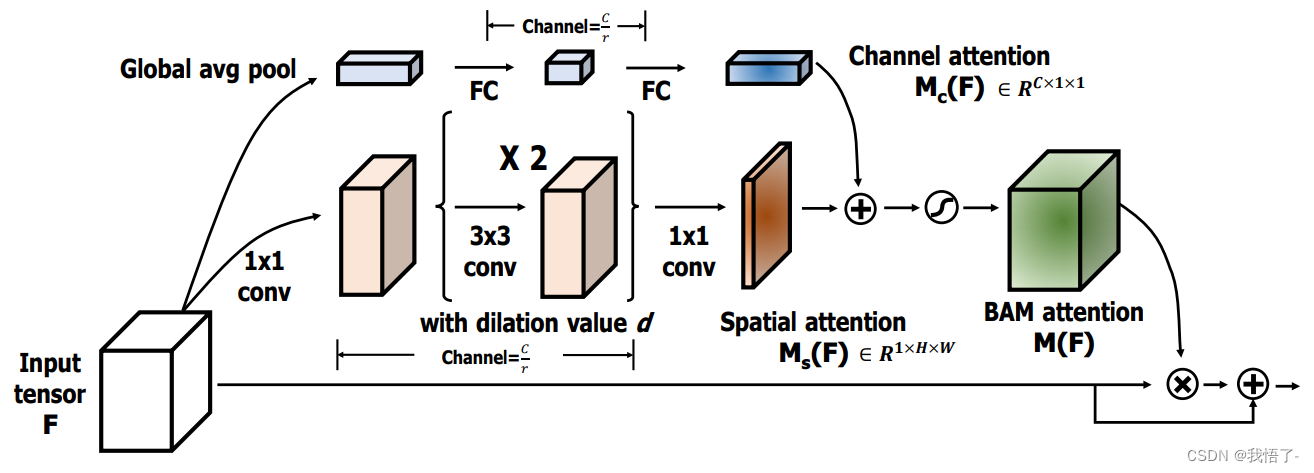
代码如下:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)
class ChannelAttention(nn.Module):
def __init__(self, channel, reduction=16, num_layers=3):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
gate_channels = [channel]
gate_channels += [channel // reduction] * num_layers
gate_channels += [channel]
self.ca = nn.Sequential()
self.ca.add_module('flatten', Flatten())
for i in range(len(gate_channels) - 2):
self.ca.add_module('fc%d' % i, nn.Linear(gate_channels[i], gate_channels[i + 1]))
self.ca.add_module('bn%d' % i, nn.BatchNorm1d(gate_channels[i + 1]))
self.ca.add_module('relu%d' % i, nn.ReLU())
self.ca.add_module('last_fc', nn.Linear(gate_channels[-2], gate_channels[-1]))
def forward(self, x):
res = self.avgpool(x)
res = self.ca(res)
res = res.unsqueeze(-1).unsqueeze(-1).expand_as(x)
return res
class SpatialAttention(nn.Module):
def __init__(self, channel, reduction=16, num_layers=3, dia_val=2):
super().__init__()
self.sa = nn.Sequential()
self.sa.add_module('conv_reduce1',
nn.Conv2d(kernel_size=1, in_channels=channel, out_channels=channel // reduction))
self.sa.add_module('bn_reduce1', nn.BatchNorm2d(channel // reduction))
self.sa.add_module('relu_reduce1', nn.ReLU())
for i in range(num_layers):
self.sa.add_module('conv_%d' % i, nn.Conv2d(kernel_size=3, in_channels=channel // reduction,
out_channels=channel // reduction, padding=1, dilation=dia_val))
self.sa.add_module('bn_%d' % i, nn.BatchNorm2d(channel // reduction))
self.sa.add_module('relu_%d' % i, nn.ReLU())
self.sa.add_module('last_conv', nn.Conv2d(channel // reduction, 1, kernel_size=1))
def forward(self, x):
res = self.sa(x)
res = res.expand_as(x)
return res
class BAMBlock(nn.Module):
def __init__(self, channel=512, reduction=16, dia_val=2):
super().__init__()
self.ca = ChannelAttention(channel=channel, reduction=reduction)
self.sa = SpatialAttention(channel=channel, reduction=reduction, dia_val=dia_val)
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
sa_out = self.sa(x)
ca_out = self.ca(x)
weight = self.sigmoid(sa_out + ca_out)
out = (1 + weight) * x
return out
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
bam = BAMBlock(channel=512, reduction=16, dia_val=2)
output = bam(input)
print(output.shape)