使用Pytorch实现SE通道注意力机制。
注意力机制就是在特征中添加权重,使得网络对重要特征特征进行关注,充分发挥重要特征的作用,从而提升网络模型的整体效果。
通道注意力机制SE就是在通道上添加权重,如果哪个通道更加重要,那么这个通道上的权重就会增加。
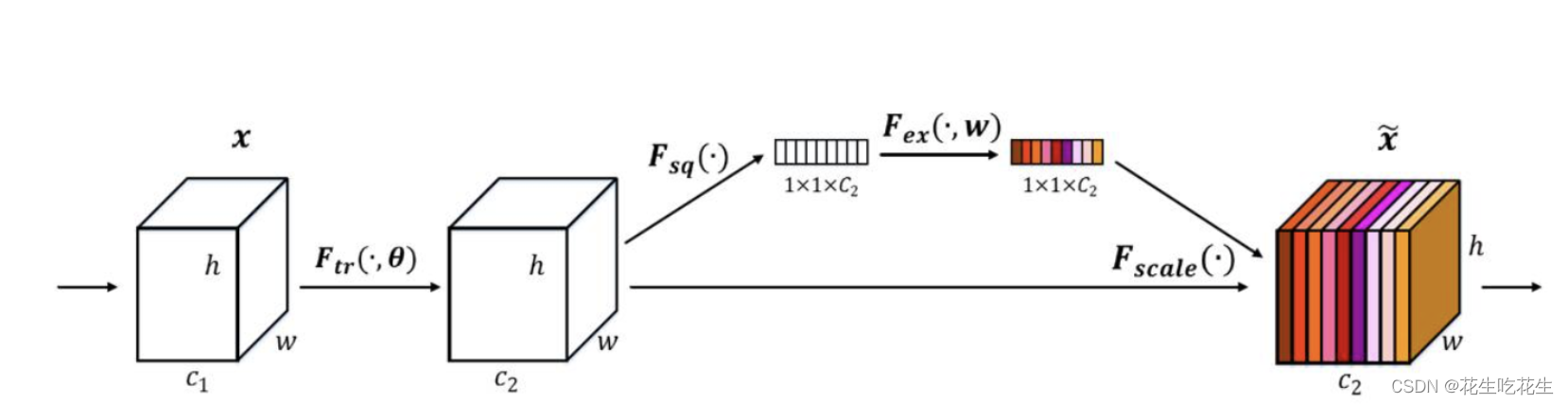
SE步骤
- 对输入的特征图进行全局最大池化。输入特征图为
(b,c,h,w),经过最大池化变成(b,c,1,1),相当于把特征图变成了细长条。 - 对经过全局平均池化的细长条进行全连接,先把通道缩小,比率为ratio。
(b,c,1,1)->(b,c/ratio,1,1) - 再次进行全连接,使得通道数量恢复正常。
(b,c/ratio,1,1)->(b,c,1,1),这个就作为权重。 - 将原始特征图与权重相乘输出。
代码:
import torch
import torch.nn as nn
class SE(nn.Module):
def __init__(self, channel,ratio = 4):
super(SE,self).__init__()
# 第一步:全局平均池化,输入维度(1,1,channel)
self.avg = nn.AdaptiveAvgPool2d(1)
# 第二步:全连接,通道数量缩减
self.fc1 = nn.Linear(channel, channel//ratio,False)
self.act = nn.ReLU()
self.fc2 = nn.Linear(channel// ratio, channel,False)
self.act2 = nn.Sigmoid()
def forward(self,x):
b, c, h, w = x.size()
# b, c, 1, 1->b,c
y = self.avg(x).view(b,c)
y = self.fc1(y)
y = self.act(y)
y = self.fc2(y)
y = self.act2(y).view(b,c,1,1)
# print(y)
return x * y
model = SE(8)
model = model.cuda()
input = torch.randn(1, 8, 12, 12).cuda()
output = model(input)
print(output.shape) # (1, 8, 12, 12)