Flatten Attention
介绍:最新注意力Flatten Attention:聚焦的线性注意力机制构建视觉 Transformer
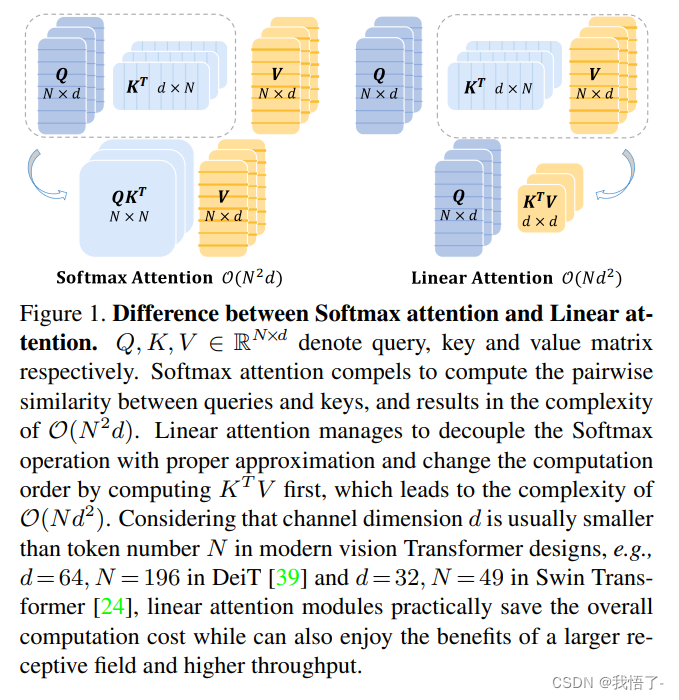
在将 Transformer 模型应用于视觉任务时,自注意力机制 (Self-Attention) 的计算复杂度随序列长度的大小呈二次方关系,给视觉任务的应用带来了挑战。各种各样的线性注意力机制 (Linear Attention) 的计算复杂度随序列长度的大小呈线性关系,可以提供一种更有效的替代方案。线性注意力机制通过精心设计的映射函数来替代 Self-Attention 中的 Softmax 操作,但是这种技术路线要么会面临比较严重的性能下降,要么从映射函数中引入额外的计算开销。
本文作者提出一种聚焦线性注意力机制 (Focused Linear Attention),力求实现高效率和高表达力。作者首先分析了是什么导致了线性注意力机制性能的下降?然后归结为了两个方面:聚焦能力 (Focus Ability) 和特征丰富度 (Feature Diversity),然后提出一个简单而有效的映射函数和一个高效的秩恢复模块来增强自我注意的表达能力,同时保持较低的计算复杂度。
原文地址:FLatten Transformer: Vision Transformer using Focused Linear Attention
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from einops.layers.torch import Rearrange
import torch.utils.checkpoint as checkpoint
import numpy as np
import time
from einops import rearrange
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'cswin_224': _cfg(),
'cswin_384': _cfg(
crop_pct=1.0
),
}
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class LePEAttention(nn.Module):
def __init__(self, dim, resolution, idx, split_size=7, dim_out=None, num_heads=8, attn_drop=0., proj_drop=0.,
qk_scale=None):
super().__init__()
self.dim = dim
self.dim_out = dim_out or dim
self.resolution = resolution
self.split_size = split_size
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
if idx == -1:
H_sp, W_sp = self.resolution, self.resolution
elif idx == 0:
H_sp, W_sp = self.resolution, self.split_size
elif idx == 1:
W_sp, H_sp = self.resolution, self.split_size
else:
print("ERROR MODE", idx)
exit(0)
self.H_sp = H_sp
self.W_sp = W_sp
stride = 1
self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim)
self.attn_drop = nn.Dropout(attn_drop)
def im2cswin(self, x):
B, N, C = x.shape
H = W = int(np.sqrt(N))
x = x.transpose(-2, -1).contiguous().view(B, C, H, W)
x = img2windows(x, self.H_sp, self.W_sp)
x = x.reshape(-1, self.H_sp * self.W_sp, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()
return x
def get_lepe(self, x, func):
B, N, C = x.shape
H = W = int(np.sqrt(N))
x = x.transpose(-2, -1).contiguous().view(B, C, H, W)
H_sp, W_sp = self.H_sp, self.W_sp
x = x.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)
x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp, W_sp) ### B', C, H', W'
lepe = func(x) ### B', C, H', W'
lepe = lepe.reshape(-1, self.num_heads, C // self.num_heads, H_sp * W_sp).permute(0, 1, 3, 2).contiguous()
x = x.reshape(-1, self.num_heads, C // self.num_heads, self.H_sp * self.W_sp).permute(0, 1, 3, 2).contiguous()
return x, lepe
def forward(self, qkv):
"""
x: B L C
"""
q, k, v = qkv[0], qkv[1], qkv[2]
### Img2Window
H = W = self.resolution
B, L, C = q.shape
assert L == H * W, "flatten img_tokens has wrong size"
q = self.im2cswin(q)
k = self.im2cswin(k)
v, lepe = self.get_lepe(v, self.get_v)
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # B head N C @ B head C N --> B head N N
attn = nn.functional.softmax(attn, dim=-1, dtype=attn.dtype)
attn = self.attn_drop(attn)
x = (attn @ v) + lepe
x = x.transpose(1, 2).reshape(-1, self.H_sp * self.W_sp, C) # B head N N @ B head N C
### Window2Img
x = windows2img(x, self.H_sp, self.W_sp, H, W).view(B, -1, C) # B H' W' C
return x
class FocusedLinearAttention(nn.Module):
def __init__(self, dim, resolution, idx, split_size=7, dim_out=None, num_heads=8, attn_drop=0., proj_drop=0.,
qk_scale=None, focusing_factor=3, kernel_size=5):
super().__init__()
self.dim = dim
self.dim_out = dim_out or dim
self.resolution = resolution
self.split_size = split_size
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
# self.scale = qk_scale or head_dim ** -0.5
if idx == -1:
H_sp, W_sp = self.resolution, self.resolution
elif idx == 0:
H_sp, W_sp = self.resolution, self.split_size
elif idx == 1:
W_sp, H_sp = self.resolution, self.split_size
else:
print("ERROR MODE", idx)
exit(0)
self.H_sp = H_sp
self.W_sp = W_sp
stride = 1
self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim)
self.attn_drop = nn.Dropout(attn_drop)
self.focusing_factor = focusing_factor
self.dwc = nn.Conv2d(in_channels=head_dim, out_channels=head_dim, kernel_size=kernel_size,
groups=head_dim, padding=kernel_size // 2)
self.scale = nn.Parameter(torch.zeros(size=(1, 1, dim)))
self.positional_encoding = nn.Parameter(torch.zeros(size=(1, self.H_sp * self.W_sp, dim)))
print('Linear Attention {}x{} f{} kernel{}'.
format(H_sp, W_sp, focusing_factor, kernel_size))
def im2cswin(self, x):
B, N, C = x.shape
H = W = int(np.sqrt(N))
x = x.transpose(-2, -1).contiguous().view(B, C, H, W)
x = img2windows(x, self.H_sp, self.W_sp)
# x = x.reshape(-1, self.H_sp * self.W_sp, C).contiguous()
return x
def get_lepe(self, x, func):
B, N, C = x.shape
H = W = int(np.sqrt(N))
x = x.transpose(-2, -1).contiguous().view(B, C, H, W)
H_sp, W_sp = self.H_sp, self.W_sp
x = x.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)
x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp, W_sp) ### B', C, H', W'
lepe = func(x) ### B', C, H', W'
lepe = lepe.reshape(-1, C // self.num_heads, H_sp * W_sp).permute(0, 2, 1).contiguous()
x = x.reshape(-1, C, self.H_sp * self.W_sp).permute(0, 2, 1).contiguous()
return x, lepe
def forward(self, qkv):
"""
x: B L C
"""
q, k, v = qkv[0], qkv[1], qkv[2]
### Img2Window
H = W = self.resolution
B, L, C = q.shape
assert L == H * W, "flatten img_tokens has wrong size"
q = self.im2cswin(q)
k = self.im2cswin(k)
v, lepe = self.get_lepe(v, self.get_v)
# q, k, v = (rearrange(x, "b h n c -> b n (h c)", h=self.num_heads) for x in [q, k, v])
k = k + self.positional_encoding
focusing_factor = self.focusing_factor
kernel_function = nn.ReLU()
scale = nn.Softplus()(self.scale)
q = kernel_function(q) + 1e-6
k = kernel_function(k) + 1e-6
q = q / scale
k = k / scale
q_norm = q.norm(dim=-1, keepdim=True)
k_norm = k.norm(dim=-1, keepdim=True)
q = q ** focusing_factor
k = k ** focusing_factor
q = (q / q.norm(dim=-1, keepdim=True)) * q_norm
k = (k / k.norm(dim=-1, keepdim=True)) * k_norm
q, k, v = (rearrange(x, "b n (h c) -> (b h) n c", h=self.num_heads) for x in [q, k, v])
i, j, c, d = q.shape[-2], k.shape[-2], k.shape[-1], v.shape[-1]
z = 1 / (torch.einsum("b i c, b c -> b i", q, k.sum(dim=1)) + 1e-6)
if i * j * (c + d) > c * d * (i + j):
kv = torch.einsum("b j c, b j d -> b c d", k, v)
x = torch.einsum("b i c, b c d, b i -> b i d", q, kv, z)
else:
qk = torch.einsum("b i c, b j c -> b i j", q, k)
x = torch.einsum("b i j, b j d, b i -> b i d", qk, v, z)
feature_map = rearrange(v, "b (h w) c -> b c h w", h=self.H_sp, w=self.W_sp)
feature_map = rearrange(self.dwc(feature_map), "b c h w -> b (h w) c")
x = x + feature_map
x = x + lepe
x = rearrange(x, "(b h) n c -> b n (h c)", h=self.num_heads)
x = windows2img(x, self.H_sp, self.W_sp, H, W).view(B, -1, C)
return x
class CSWinBlock(nn.Module):
def __init__(self, dim, reso, num_heads,
split_size=7, mlp_ratio=4., qkv_bias=False, qk_scale=None,
drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
last_stage=False,
focusing_factor=3, kernel_size=5, attn_type='L'):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.patches_resolution = reso
self.split_size = split_size
self.mlp_ratio = mlp_ratio
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.norm1 = norm_layer(dim)
if self.patches_resolution == split_size:
last_stage = True
if last_stage:
self.branch_num = 1
else:
self.branch_num = 2
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(drop)
assert attn_type in ['L', 'S']
if attn_type == 'L':
if last_stage:
self.attns = nn.ModuleList([
FocusedLinearAttention(
dim, resolution=self.patches_resolution, idx=-1,
split_size=split_size, num_heads=num_heads, dim_out=dim,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
focusing_factor=focusing_factor, kernel_size=kernel_size)
for i in range(self.branch_num)])
else:
self.attns = nn.ModuleList([
FocusedLinearAttention(
dim // 2, resolution=self.patches_resolution, idx=i,
split_size=split_size, num_heads=num_heads // 2, dim_out=dim // 2,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
focusing_factor=focusing_factor, kernel_size=kernel_size)
for i in range(self.branch_num)])
else:
if last_stage:
self.attns = nn.ModuleList([
LePEAttention(
dim, resolution=self.patches_resolution, idx=-1,
split_size=split_size, num_heads=num_heads, dim_out=dim,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
for i in range(self.branch_num)])
else:
self.attns = nn.ModuleList([
LePEAttention(
dim // 2, resolution=self.patches_resolution, idx=i,
split_size=split_size, num_heads=num_heads // 2, dim_out=dim // 2,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
for i in range(self.branch_num)])
mlp_hidden_dim = int(dim * mlp_ratio)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim, act_layer=act_layer,
drop=drop)
self.norm2 = norm_layer(dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H = W = self.patches_resolution
B, L, C = x.shape
assert L == H * W, "flatten img_tokens has wrong size"
img = self.norm1(x)
qkv = self.qkv(img).reshape(B, -1, 3, C).permute(2, 0, 1, 3)
if self.branch_num == 2:
x1 = self.attns[0](qkv[:, :, :, :C // 2])
x2 = self.attns[1](qkv[:, :, :, C // 2:])
attened_x = torch.cat([x1, x2], dim=2)
else:
attened_x = self.attns[0](qkv)
attened_x = self.proj(attened_x)
x = x + self.drop_path(attened_x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def img2windows(img, H_sp, W_sp):
"""
img: B C H W
"""
B, C, H, W = img.shape
img_reshape = img.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)
img_perm = img_reshape.permute(0, 2, 4, 3, 5, 1).contiguous().reshape(-1, H_sp * W_sp, C)
return img_perm
def windows2img(img_splits_hw, H_sp, W_sp, H, W):
"""
img_splits_hw: B' H W C
"""
B = int(img_splits_hw.shape[0] / (H * W / H_sp / W_sp))
img = img_splits_hw.view(B, H // H_sp, W // W_sp, H_sp, W_sp, -1)
img = img.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return img
class Merge_Block(nn.Module):
def __init__(self, dim, dim_out, norm_layer=nn.LayerNorm):
super().__init__()
self.conv = nn.Conv2d(dim, dim_out, 3, 2, 1)
self.norm = norm_layer(dim_out)
def forward(self, x):
B, new_HW, C = x.shape
H = W = int(np.sqrt(new_HW))
x = x.transpose(-2, -1).contiguous().view(B, C, H, W)
x = self.conv(x)
B, C = x.shape[:2]
x = x.view(B, C, -1).transpose(-2, -1).contiguous()
x = self.norm(x)
return x
class CSWinTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=96, depth=[2, 2, 6, 2],
split_size=[1, 2, 7, 7], la_split_size='1-2-7-7',
num_heads=[2, 4, 8, 16], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, use_chk=False,
focusing_factor=3, kernel_size=5, attn_type='LLLL'):
super().__init__()
# split_size = [1, 2, img_size // 32, img_size // 32]
la_split_size = la_split_size.split('-')
self.use_chk = use_chk
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
heads = num_heads
self.stage1_conv_embed = nn.Sequential(
nn.Conv2d(in_chans, embed_dim, 7, 4, 2),
Rearrange('b c h w -> b (h w) c', h=img_size // 4, w=img_size // 4),
nn.LayerNorm(embed_dim)
)
curr_dim = embed_dim
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, np.sum(depth))] # stochastic depth decay rule
attn_types = [(attn_type[0] if attn_type[0] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[0])]
split_sizes = [(int(la_split_size[0]) if attn_types[i] == 'L' else split_size[0]) for i in range(depth[0])]
self.stage1 = nn.ModuleList([
CSWinBlock(
dim=curr_dim, num_heads=heads[0], reso=img_size // 4, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
split_size=split_sizes[i],
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[i], norm_layer=norm_layer,
focusing_factor=focusing_factor, kernel_size=kernel_size,
attn_type=attn_types[i])
for i in range(depth[0])])
self.merge1 = Merge_Block(curr_dim, curr_dim * 2)
curr_dim = curr_dim * 2
attn_types = [(attn_type[1] if attn_type[1] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[1])]
split_sizes = [(int(la_split_size[1]) if attn_types[i] == 'L' else split_size[1]) for i in range(depth[1])]
self.stage2 = nn.ModuleList(
[CSWinBlock(
dim=curr_dim, num_heads=heads[1], reso=img_size // 8, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
split_size=split_sizes[i],
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[np.sum(depth[:1]) + i], norm_layer=norm_layer,
focusing_factor=focusing_factor, kernel_size=kernel_size,
attn_type=attn_types[i])
for i in range(depth[1])])
self.merge2 = Merge_Block(curr_dim, curr_dim * 2)
curr_dim = curr_dim * 2
attn_types = [(attn_type[2] if attn_type[2] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[2])]
split_sizes = [(int(la_split_size[2]) if attn_types[i] == 'L' else split_size[2]) for i in range(depth[2])]
temp_stage3 = []
temp_stage3.extend(
[CSWinBlock(
dim=curr_dim, num_heads=heads[2], reso=img_size // 16, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
split_size=split_sizes[i],
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[np.sum(depth[:2]) + i], norm_layer=norm_layer,
focusing_factor=focusing_factor, kernel_size=kernel_size,
attn_type=attn_types[i])
for i in range(depth[2])])
self.stage3 = nn.ModuleList(temp_stage3)
self.merge3 = Merge_Block(curr_dim, curr_dim * 2)
curr_dim = curr_dim * 2
attn_types = [(attn_type[3] if attn_type[3] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[3])]
split_sizes = [(int(la_split_size[3]) if attn_types[i] == 'L' else split_size[3]) for i in range(depth[3])]
self.stage4 = nn.ModuleList(
[CSWinBlock(
dim=curr_dim, num_heads=heads[3], reso=img_size // 32, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
split_size=split_sizes[i],
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[np.sum(depth[:-1]) + i], norm_layer=norm_layer, last_stage=True,
focusing_factor=focusing_factor, kernel_size=kernel_size,
attn_type=attn_types[i])
for i in range(depth[-1])])
self.norm = norm_layer(curr_dim)
# Classifier head
self.head = nn.Linear(curr_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.head.weight, std=0.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2d)):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {
'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
if self.num_classes != num_classes:
print('reset head to', num_classes)
self.num_classes = num_classes
self.head = nn.Linear(self.out_dim, num_classes) if num_classes > 0 else nn.Identity()
self.head = self.head.cuda()
trunc_normal_(self.head.weight, std=.02)
if self.head.bias is not None:
nn.init.constant_(self.head.bias, 0)
def forward_features(self, x):
B = x.shape[0]
x = self.stage1_conv_embed(x)
for blk in self.stage1:
if self.use_chk:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
for pre, blocks in zip([self.merge1, self.merge2, self.merge3],
[self.stage2, self.stage3, self.stage4]):
x = pre(x)
for blk in blocks:
if self.use_chk:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.norm(x)
return torch.mean(x, dim=1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {
}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
### 224 models
def FLatten_CSWin_64_24181_tiny_224(pretrained=False, **kwargs):
model = CSWinTransformer(patch_size=4, embed_dim=64, depth=[2, 4, 18, 1],
split_size=[1, 2, 7, 7], num_heads=[2, 4, 8, 16], mlp_ratio=4., **kwargs)
model.default_cfg = default_cfgs['cswin_224']
return model
def FLatten_CSWin_64_24322_small_224(pretrained=False, **kwargs):
model = CSWinTransformer(patch_size=4, embed_dim=64, depth=[2, 4, 32, 2],
split_size=[1, 2, 7, 7], num_heads=[2, 4, 8, 16], mlp_ratio=4., **kwargs)
model.default_cfg = default_cfgs['cswin_224']
return model
def FLatten_CSWin_96_36292_base_224(pretrained=False, **kwargs):
model = CSWinTransformer(patch_size=4, embed_dim=96, depth=[3, 6, 29, 2],
split_size=[1, 2, 7, 7], num_heads=[4, 8, 16, 32], mlp_ratio=4., **kwargs)
model.default_cfg = default_cfgs['cswin_224']
return model
### 384 models
def FLatten_CSWin_96_36292_base_384(pretrained=False, **kwargs):
model = CSWinTransformer(patch_size=4, embed_dim=96, depth=[3, 6, 29, 2],
split_size=[1, 2, 12, 12], num_heads=[4, 8, 16, 32], mlp_ratio=4., **kwargs)
model.default_cfg = default_cfgs['cswin_384']
return model