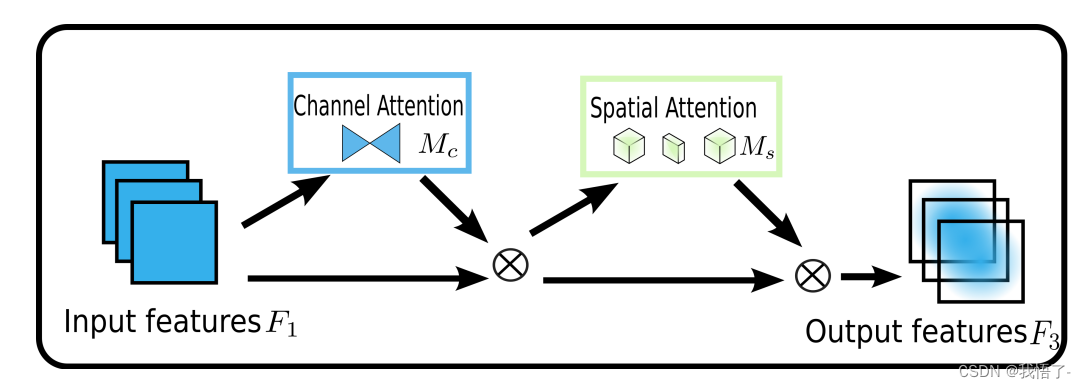
GAM注意力机制
GAM注意力机制——“全局”注意力机制,跨越空间通道维度,保留信息以放大“全局”跨维度的交互作用。
论文地址:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
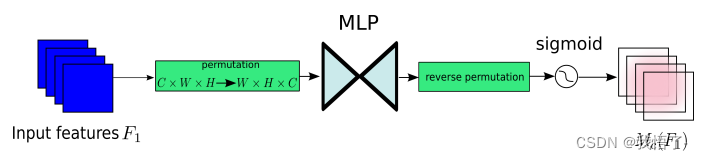
通道注意力子模块
通道注意子模块使用三维排列来在三个维度上保留信息。然后,它用一个两层的MLP(多层感知器)放大跨维通道-空间依赖性。(MLP是一种编码-解码器结构,与BAM相同,其压缩比为r);通道注意子模块如图所示:
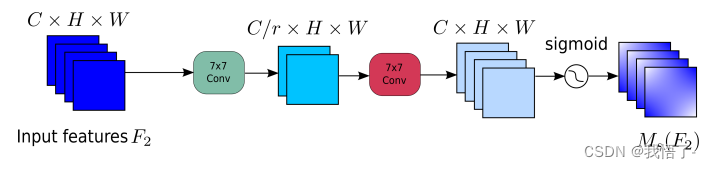
空间注意力子模块
在空间注意力子模块中,为了关注空间信息,使用两个卷积层进行空间信息融合。还从通道注意力子模块中使用了与BAM相同的缩减比r。与此同时,由于最大池化操作减少了信息的使用,产生了消极的影响。这里删除了池化操作以进一步保留特性映射。因此,空间注意力模块有时会显著增加参数的数量。为了防止参数显著增加,在ResNet50中采用带Channel Shuffle的Group卷积。无Group卷积的空间注意力子模块如图所示:
代码实现:
import torch.nn as nn
import torch
class GAM_Attention(nn.Module):
def __init__(self, in_channels, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(in_channels, int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(in_channels / rate), in_channels)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(int(in_channels / rate), in_channels, kernel_size=7, padding=3),
nn.BatchNorm2d(in_channels)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2).sigmoid()
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
out = x * x_spatial_att
return out
if __name__ == '__main__':
x = torch.randn(1, 64, 20, 20)
b, c, h, w = x.shape
net = GAM_Attention(in_channels=c)
y = net(x)
print(y.size())