一、线性神经网络
线性神经网络在结构上与感知器非常相似,主要区别在于激活函数不同。感知器的激活函数只能输出两种可能值,分别是-1和1,而线性神经网络的输出可以取任意值,其激活函数属于线性函数,例如下图中的purelin函数。通常线性神经网络采用LMS(LeastMean Square)算法来调整网络的权值和偏置值。

LMS算法是Widrow和Hoff在对自适应线性元素的方案一模式识别进行研究时提出的,又称最小均方算法。LMS算法是基于维纳滤波,并借助于最速下降法发展起来的,以递归的方式逼近最优解。因此,LMS算法具有计算复杂程度低、利用有限精度实现算法稳定性的优势,使LMS算法成为自适应算法中稳定性最好、应用最广泛的算法。LMS算法的具体流程为:(1)确定参数,包括全局步长和层数(阶数);(2)对初始值进行初始化;(3)运算,包括结果输出、误差信号和权重更新。
线性神经网络最为常见的功能是用以解决线性回归问题和线性分类问题,而这两类问题又归属于机器学习中监督学习。监督学习是基于正确答案,用一个假设去逼近输入到给定输出的映射关系,典型的就是回归问题和分类问题。
以下对线性回归和线性分类问题进行展开讲述。
二、线性回归
回归(regression)是统计学中最有力的工具之一,适用于连续型分布数据的预测,当给定一个输入值时可以预测得到一个具体的数值。回归的目的就是建立一个回归方程用来预测目标值,通过一定的方法求解回归方程的回归系数,即可得到输出值关于输入值的映射关系。
基于映射关系的函数形式,又分为线性回归、二次回归、非线性回归等;根据输入值的维数又可分为一元回归、二元回归乃至多元回归。因此,线性回归就是给出一个点集D,用一个线性函数去拟合这个点集并使得点集与拟合函数间的误差最小,得到的线性函数即线性回归方程。
2.1 线性回归模型
线性回归首先需要进行如下的假设:(1)自变量x和因变量y之间的关系是线性的,即y可以表示为x中元素的加权和;(2)允许一定的随机扰动项(噪声)存在,其应具有随机性,如符合正态分布等。
具体到现实,研究者希望根据汽车品牌效应、汽车性能、车龄来预计二手车的市场价。为开发预测二手车市场价的模型,研究者需要收集真实数据集,包括品牌价值、性能、车龄和二手车市场价。在机器学习术语中,数据集成为训练数据集,每条数据成为样本或数据点,预测的目标(二手车市场价)称为标签,预测基于的自变量(品牌价值、性能、车龄)称为特征或协变量。我们可以用n来表示数据集的样本数,对索引为i的样本,其输入可以表示为:
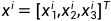
对应的标签为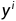 。
。
基于以上假设,可以将此关系设想为:
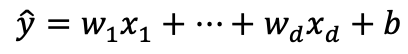
用向量则可表示为:
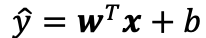
向量x对应于单个数据样本的特征,用X表示整个数据集的n个样本,其中X的每一行是一个样本,每一列是一种特征。
对于特征集合X,预测值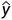 可以表示为:
可以表示为:

给定训练数据特征X和对应的已知标签y,线性回归的目标是找到一组权重向量w和偏置b,当给定从X的同分布中取样的新样本特征时,这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。
在开始寻找最好的模型参数w和b前,还需要衡量模型质量的方式以及提高模型质量的方法。
2.2 损失函数
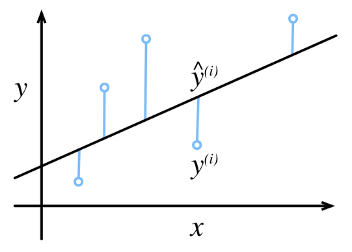
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。如下图所示,通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。回归问题中使用最多的损失函数是平方误差函数,当样本i的预测值为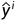 时,相应的真实标签为,则平方误差可定义为如下公式:
时,相应的真实标签为,则平方误差可定义为如下公式:
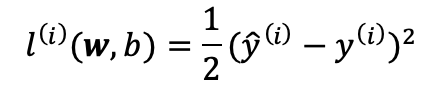
2.3 解析解
线性回归的解可以用一个公式简单地表达出来,这类解叫作解析解(analyticalsolution)。首先,我们将偏置b合并到参数w中,合并方法是在包含所有参数的矩阵中附加一列。我们的目的是最小化如下表达式:
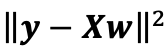
这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失极小点。将损失关于w的导数设为0,得到解析解:
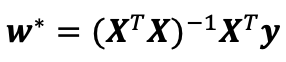
像线性回归这样的简单问题存在解析解,但并不是所有的问题都存在解析解。解析解可以进行很好的数学分析,但解析解对问题的限制很严格,导致它无法广泛应用在深度学习里。
2.4随机梯度下降
梯度下降的用法是计算损失函数关于模型参数的导数(梯度)。在每一次更新参数之前,需要遍历整个数据集,通常会在每次需要计算更新的时候随机抽取一小批样本,这种变体叫做小批量随机梯度下降。
在每次迭代中,我们首先随机抽样一个小批量,它是由固定数量的训练样本组成的。然后,我们计算小批量的平均损失关于模型参数的导数。最后,我们将梯度乘以一个预先确定的正数η,并从当前参数的值中减掉。
2.5 用python实现线性回归
首先生成数据集,使用线性模型参数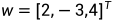 ,b = 4.2和噪声项ε生成数据集和标签的表达式:
,b = 4.2和噪声项ε生成数据集和标签的表达式:
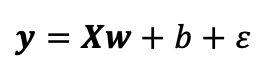
假设ε服从均值为0的正态分布,为简化问题,将标准差设为0.01。
# 根据带有噪声的线性模型构造一个人造数据集。我们使用线性模型参数
# w , b 和噪声d生成数据集及其标签
def synthetic_data(w, b, num_examples):
X = torch.normal(0,1,(num_examples, len(w))) ###生成mean=0, std=1, size=(num_examples, len(w)) 的向量
y = torch.matmul(X,w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1,1)) ### 将Y 转换为列向量
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0], '\nlabel:', labels[0])
plt.figure()
plt.scatter(features[:, 1].detach().numpy(),
labels.detach().numpy(),1)
plt.show()定义好数据生成函数后,我们可将X与y定义为特征和标签,数据图如下图所示。从图中的散点来看,数据分布满足线性要求。

定义好数据后,需要定义接受数据的函数,其中包含批次量、特征和标签。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) ## 打乱下标
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i:min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
batch_size = 10
for X, y in data_iter(batch_size,features, labels):
print(X, '\n',y )
break需要注意的是,因为数据要参加训练所以必须打乱,即random.shuffle,这里我们打印我们读取到的数据可以得到数据格式为(10, 2)。
tensor([[-0.9799, -0.5394],
[-0.1818, 0.4705],
[-1.0967, -2.5218],
[-1.4719, 0.4218],
[-0.7889, -1.4477],
[-0.2622, -0.1918],
[-1.1138, -0.8647],
[-0.5958, -0.3762],
[-1.6837, -2.3087],
[-1.5623, -0.2522]])
tensor([[ 4.0597],
[ 2.2267],
[10.5830],
[-0.1603],
[ 7.5412],
[ 4.3141],
[ 4.9181],
[ 4.2847],
[ 8.6720],
[ 1.9464]])在读取完数据后我们就可以进入训练阶段,主要步骤分为:(1)初始化权重w,因为w需要参与计算梯度;(2)初始化偏差标量b;(3)定义模型linreg;(4)定义损失函数;(5)定义梯度优化函数。
###定义初始化模型参数 w 与b
w = torch.normal (0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(size=(1,1), requires_grad=True) ## 因为偏差是个标量 所以size为1*1
def linreg(X, w, b):
'''线性回归模型'''
return torch.matmul(X, w) + b
def squared_loss(y_hat, y):
''''均方损失'''
return (y_hat-y.reshape(y_hat.shape))**2 / 2 ###向量大小可能不一样,所以统一reshape 成size(y_hat)
def sgd(params, lr, batch_size): ##
'''
1. params :给定所有参数
2. lr:学习率
3. batch_size: 输入的批次量大小
小批量随机梯度下降
'''
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_() ##torch不会自动将梯度重新设置为0,这里需手动设置之后即可进入训练阶段,需要设置好学习率和迭代次数。
lr = 0.03
num_epochs = 20
net = linreg
loss = squared_loss
for epoch in range (num_epochs):
for X,y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y)
l.sum().backward()
sgd([w,b], lr, batch_size)
with torch.no_grad():
train_1 = loss(net(features, w, b), labels)
print(f'epoch{epoch + 1}, loss{float(train_1.mean()):f}')
## 人工数据集 可以手动查看误差
print(f'w的估计误差:{true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差:{true_b - b}') ## b 是个标量 不需要resize三、线性分类
3.1 分类
线性神经网络也可用于解决分类问题,对于任意一个输入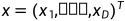 ,分类的任务就是其分配到K个类别之一的
,分类的任务就是其分配到K个类别之一的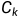 。属于类别的所有样本x构成的集合,称为类别的决策区域记为
。属于类别的所有样本x构成的集合,称为类别的决策区域记为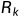 ,决策区域之间的边界称为决策边界。
,决策区域之间的边界称为决策边界。
所谓线性分类模型是指决策边界为线性边界的分类模型。即,线性分类模型的决策边界具有如下的形式:
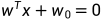
下图展示了二维输入空间的线性和非线性分类模型的情况。
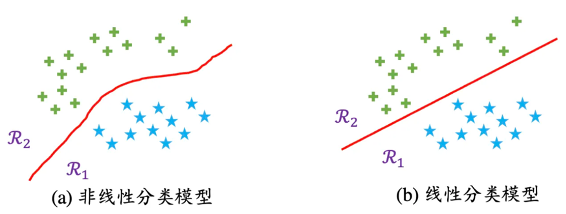
简单来说,分类问题就是对样本进行类别的划分,在实际生活中经常会面临这类问题。例如,把猫和狗分成不同的类,具体到不同品种,猫和狗又各自会分为不同的类型,这就是一种分类问题。抽象成散点来说,可以将图中的散点按照坐标分为两类,两种类型大致分布在各自的区域中。若要解决这个问题,就要让训练好的网络具有两个输入节点,分别输入x坐标和y坐标;还需要两个输出节点,输出分类编码。通常采用的分类编码在计算机学科中被称为独热编码(One-hot),如上图(b)中的散点可分为两类,可以让输出10代表第一类,01代表第二类。推广到多分类上,可以让100代表第一类,010代表第二类,001代表第三类。
关于二分类问题的输出也可以不采用独热编码,可以只有一个输出,输出的范围为0~1,代表输入被认定为是第一类或第二类的概率。这种情况下,输出层的激活函数一般用Sigmoid函数。
3.2 用python实现分类
为了简单起见和普适性,此处不引用猫狗识别这样的实际问题,而是采用具有一定随机性的散点分布进行展示。
3.2.1 准备工作
首先导入需要的模块,如下:
import torch ## 导入torch模块
import torch.nn as nn ## 简化nn模块
import matplotlib.pyplot as plt ## 导入并简化matplotlib模块我们希望构建大致在两种范围内的散点集,而这些散点还需要具有一定的随机性。此处引用torch中的normal()接口,该接口适用于产生符合均值为mean、标准差为std的正态分布随机数,其中mean和std不一定是一个值,也可以是一个数组,但两个数组的size必须相同。
torch.normal(mean,std)在参数均为数组的情况下,最后生成的Tensor变量的size也与数组size相同。
x = torch.ones(5)
y = torch.normal(x, 1)
print(y)上述代码运行后会产生一维随机数组,随机值符合均值为1,标准差为1的正态分布,运行结果如下:
tensor([1.5439, 0.8622, 1.4256, 0.0724, 1.1194])如果把x改成二维数组,如:
x = torch.ones(2, 2)运行结果如下:
tensor([[ 0.4945, 1.3048],
[-0.4960, 1.2658]])我们希望构建两种不同的样本集,但两种样本集又有着自己的总体特征,可以让两个不同的散点集合符合不同的正态分布,例如:
data = torch.ones(100,2) ## 数据总数(总框架)
x0 = torch.normal(2*data, 1) ## 第一类坐标
x1 = torch.normal(-2*data, 1) ## 第二类坐标
## 画图
for item in x0:
plt.scatter(item[0],item[1])
for item in x1:
plt.scatter(item[0],item[1])
plt.show()x0和x1均继承了data的尺寸,是一个二维数组,尺寸为100*2。因此,x0和x1均可代表一个点集,因为正态分布参数不同,所以两个点集是不同的点集,绘制的散点图如下图所示。
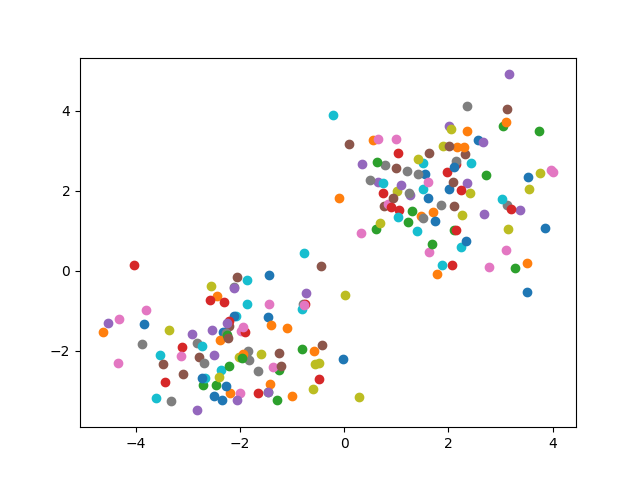
在训练网络时候,我们希望训练集是一个整体,所以将x0和x1合并成一个样本集。合并Tensor张量的接口为torch.cat(),例如:
import torch
x0 = torch.ones(2, 2) ## 创建二维Tensor张量
x1 = torch.zeros(2, 2)
print(x0)
print(x1)
x = torch.cat((x0, x1), 0) ## 按列合并
print(x)
x = torch.cat((x0, x1), 1) ## 按行合并
print(x)
x = torch.cat((x0, x1)) ## 默认按列合并
print(x)输出结果如下:
tensor([[1., 1.],
[1., 1.]])
tensor([[0., 0.],
[0., 0.]])
tensor([[1., 1.],
[1., 1.],
[0., 0.],
[0., 0.]])
tensor([[1., 1., 0., 0.],
[1., 1., 0., 0.]])
tensor([[1., 1.],
[1., 1.],
[0., 0.],
[0., 0.]])将样本按列合并之后,第一列代表所有的x坐标,第二列代表所有的y坐标。合并完成之后,为防止数据类型错误,将其转换成Float类型的Tensor变量,代码如下:
x = torch.cat((x0, x1)).type(torch.FloatTensor)之后,给散点集打上标签,告诉计算机哪些是第一类点,哪些是第二类点,可以将第一类标记为0,第二类标记为1,用y来储存这些标签。
y0 = torch.zeros(100) ## 第一类标签储存为0
y1 = torch.ones(100) ## 第二类标签储存为1
y = torch.cat((y0, y1)).type(torch.LongTensor)3.2.2 构建网络
根据分类问题的分析,网络需要有两个输入和输出,采用隐藏节点为15的隐含层,选择ReLU函数作为隐含层激活函数,Softmax函数作为输出层激活函数。

构建网络的方法和回归问题类似,代码如下:
class Net(nn.Module): ## 定义类,储存网络结构
def __init__(self):
super(Net, self).__init__() ## nn模块搭建网络
self.classify = nn.Sequential( ## nn模块搭建网络
nn.Linear(2, 15), ## 全连接层,2个输入,15个输出
nn.ReLU(), ## ReLU激活函数
nn.Linear(15, 2), ## 全连接层,15个输入,2个输出
nn.Softmax(dim=1)
)
def forward(self, x): ## 定义前向传播过程
classification = self.classify(x) ## 将x传入网络
return classification ## 返回预测值3.2.3 训练网络
构建网络后,需要对网络进行训练,训练的设置和前面设置的几乎一致,采用SGD算法进行优化。通常分类问题采用交叉熵函数作为损失函数,接口为CrossEntropyLoss(),代码如下:
net = Net()
optimizer = torch.optim.SGD(net.parameters(), lr=0.03) ## 设置优化器
loss_func = nn.CrossEntropyLoss() ## 设置损失函数
for epoch in range(100): # 训练部分
out = net(x) ## 实际输出
loss = loss_func(out, y) ## 实际输出和期望输出传入损失函数
optimizer.zero_grad() ## 清除梯度
loss.backward() ## 误差反向传播
optimizer.step() ## 优化器开始优化3.2.4 完整程序(附可视化过程)
使用神经网络解决分类问题的完整程序代码如下:
import torch ## 导入torch模块
import torch.nn as nn ## 简化nn模块
import matplotlib.pyplot as plt ## 导入并简化matplotlib模块
data = torch.ones(100, 2) ## 数据总数(总框架)
x0 = torch.normal(2 * data, 1) ## 第一类坐标
x1 = torch.normal(-2 * data, 1) ## 第二类坐标
y0 = torch.zeros(100) ## 第一类标签储存为0
y1 = torch.ones(100) ## 第二类标签储存为1
x = torch.cat((x0, x1)).type(torch.FloatTensor)
y = torch.cat((y0, y1)).type(torch.LongTensor)
class Net(nn.Module): ## 定义类,储存网络结构
def __init__(self):
super(Net, self).__init__() ## nn模块搭建网络
self.classify = nn.Sequential( ## nn模块搭建网络
nn.Linear(2, 15), ## 全连接层,2个输入,15个输出
nn.ReLU(), ## ReLU激活函数
nn.Linear(15, 2), ## 全连接层,15个输入,2个输出
nn.Softmax(dim=1)
)
def forward(self, x): ## 定义前向传播过程
classification = self.classify(x) ## 将x传入网络
return classification ## 返回预测值
net = Net()
optimizer = torch.optim.SGD(net.parameters(), lr=0.03) ## 设置优化器
loss_func = nn.CrossEntropyLoss() ## 设置损失函数
plt.ion ## 打开交互模式
for epoch in range(100): # 训练部分
out = net(x) ## 实际输出
loss = loss_func(out, y) ## 实际输出和期望输出传入损失函数
optimizer.zero_grad() ## 清除梯度
loss.backward() ## 误差反向传播
optimizer.step() ## 优化器开始优化
if epoch % 2 == 0: ## 每2poch显示
plt.cla() ## 清除上一次绘图
classification = torch.max(out, 1)[1] ## 返回每一行中最大值的下标
class_y = classification.data.numpy() ## 转换成numpy数组
target_y = y.data.numpy() ## 标签页转换成numpy数组
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=class_y,
s=100, cmap='RdYlGn') ## 绘制散点图
accuracy = sum(class_y == target_y) / 200 ## 计算准确率
plt.text(1.5, -4, f'Accuracy={accuracy}',
fontdict={'size': 20, 'color': 'red'}) ## 显示准确率
plt.pause(0.4) ## 时间0.4s
plt.show()
plt.ioff() ## 关闭交互模式
plt.show()输出结果大致变化过程如下图所示:
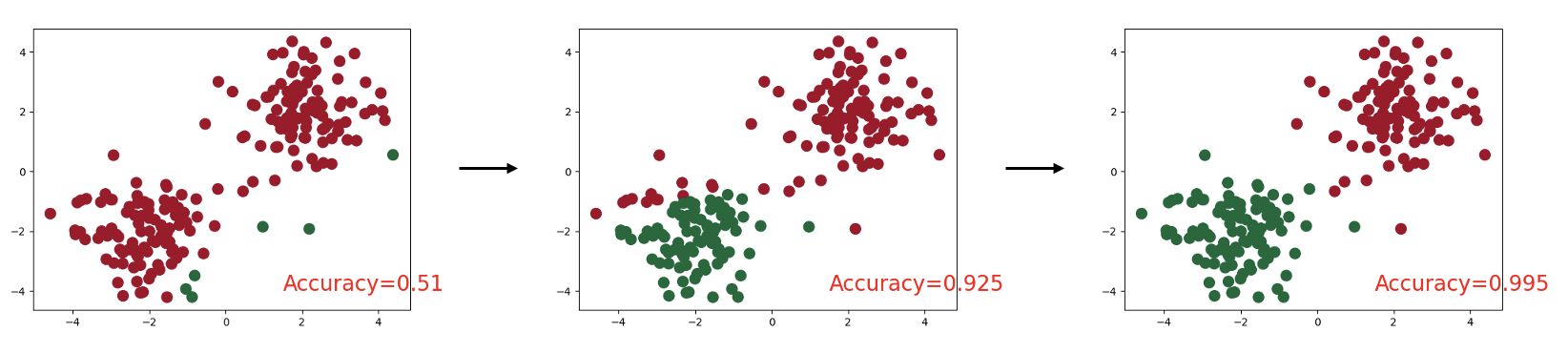
当准确率逼近1时,可以看到分类已经完成,且效果显著,说明训练的模型有效。