大模型使用的关键在于Prompt,然而大模型存在幻觉现象,如何减少这种现象的发生成为迫切解决的问题。外部知识库+LLM的方法可以缓解大模型幻觉,但是如何撰写Prompt才能发挥LLM的性能。下面介绍这篇论文说明上下文信息出现在Prompt什么位置使模型表现最佳,以及上下文文本长度对LLM性能的影响。
Title: Lost in the Middle How Language Models Use Long Contexts
URL: https://arxiv.org/pdf/2307.03172.pdf
Code: https://github.com/nelson-liu/lost-in-the-middle
1. Motivate
最近的语言模型能够将长上下文作为输入,然而人们对语言模型在多大程度上支持长上下文还了解不多。因此本文针对从输入上下文中识别相关信息的任务:多文档问题解答和键值检索,对语言模型的性能进行了分析。
2. Experiment
2.1 多文档问答
2.1.1 目的
探索输入上下文长度和相关信息在输入上下文的位置对LLM输出影响。
2.1.2 模型
- claude-1.3
- claude-1.3-100k
- gpt-3.5-turbo-16k-0613
- mpt-30b-instruct
- longchat-13b-16k
全部模型统一使用贪婪解码策略。
评估指标:使用准确性作为评估指标,判断预测输出中是否出现任何正确答案。
2.1.3 结果分析

为了调整此任务中的输入上下文长度,增加或减少不包含答案的检索文档的数量。(见下图)
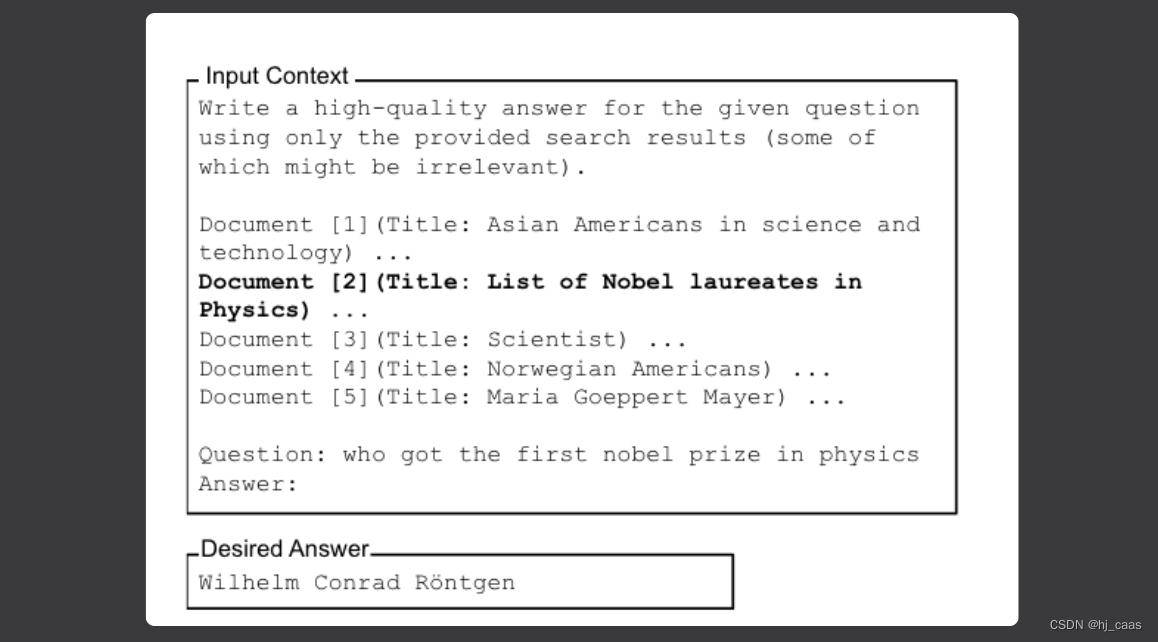
为了调整相关信息在输入上下文中的位置,我们调整输入上下文中文档的顺序,以更改包含答案的文档的位置。(见下图)
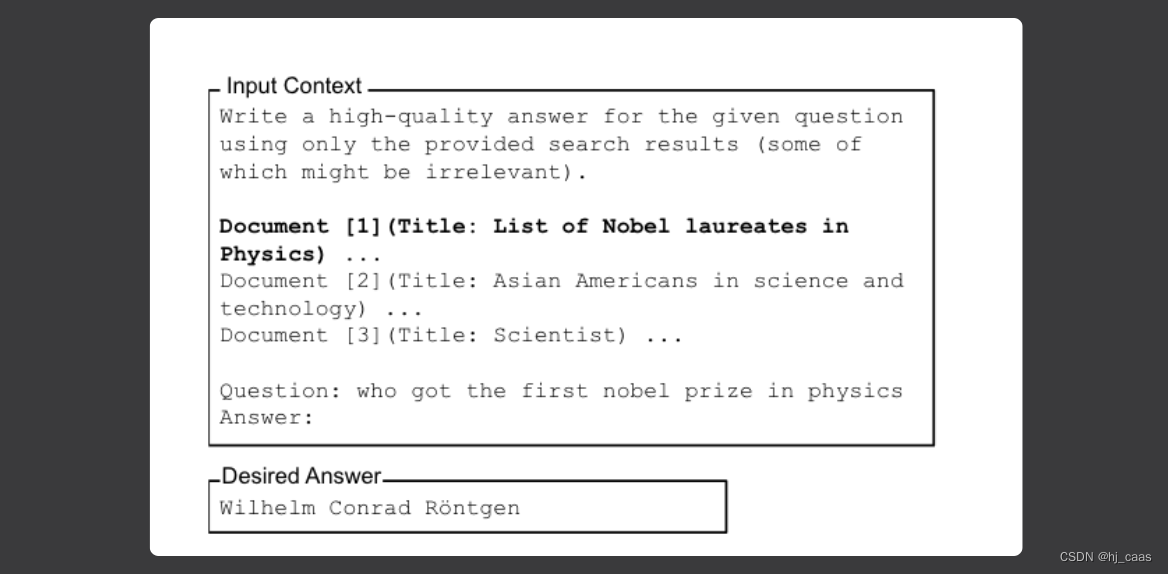
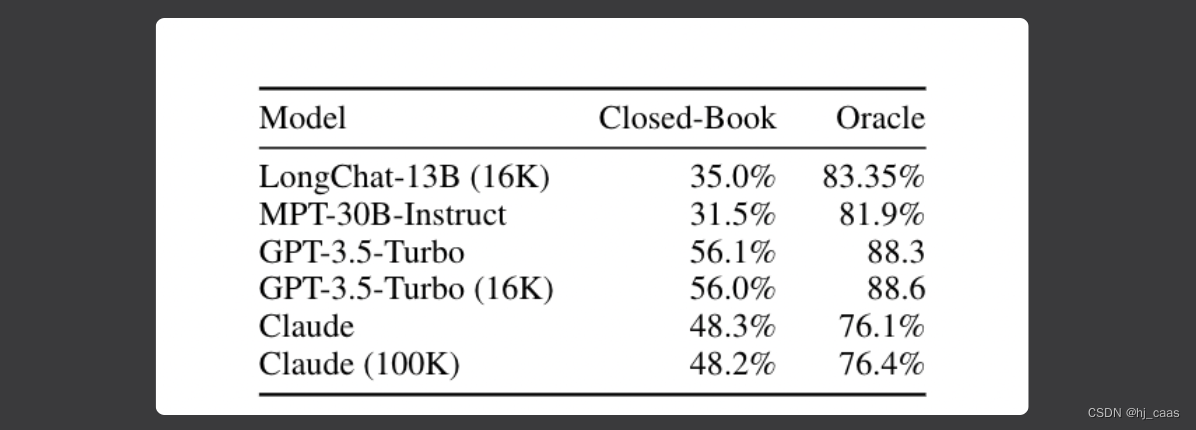
论文设置Closed-Book和Oracle两种实验环境,实验结果表明当输入含有上下文信息时,模型输出正确答案的概率大幅度提高。
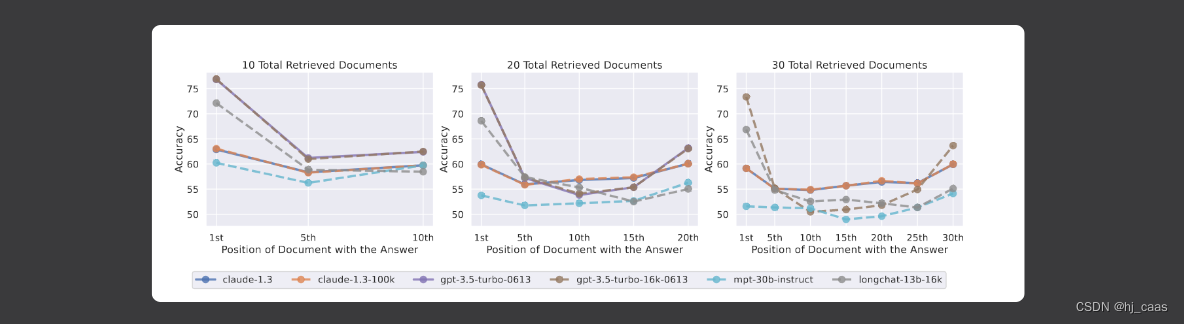
实验结果显示当相关信息出现在输入上下文的开头或结尾时,模型性能最高。相关信息出现在上下文中间位置时模型表现最差。这些结果表明模型在执行下游任务时无法有效的推断其内部上下文窗口,模型更容易使用上下文开始或者结束的信息。如下图所示。
实验结果显示,随着输入上下文的增长,模型性能显著下降,表明模型很难从长输入上下文中检索和使用相关信息。当将模型与其相应的扩展上下文版本进行比较时,这种趋势仍在继续。尽管扩展上下文模型可以处理更长的输入上下文,但它们可能无法更好地对其上下文中的信息进行推理(查看GPT-3.5-Turbo-0613和GPT-3.5-Turbo-16k-0613)。
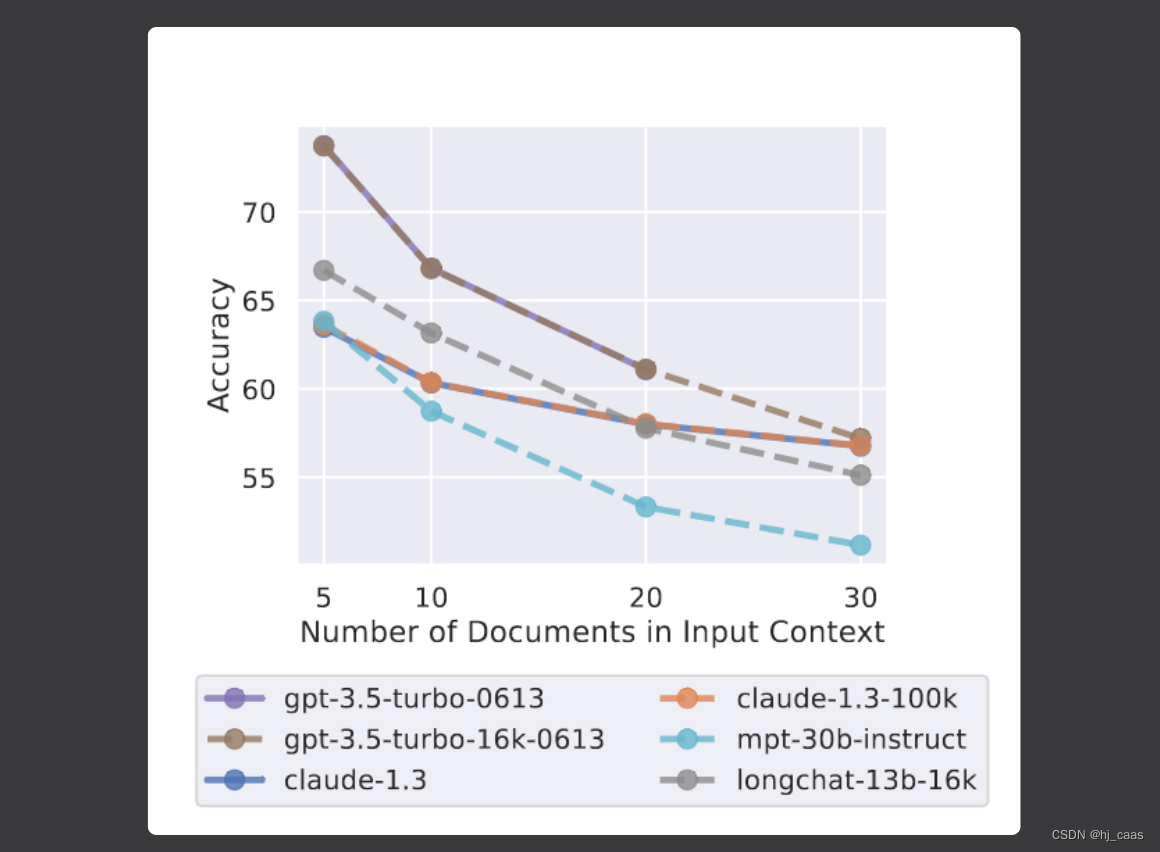
扩展上下文模型不一定更擅长使用输入上下文。在输入上下文模型及其扩展上下文对应模型的上下文窗口的设置中,我们可以看到它们之间的性能几乎是相同的。这些结果表明,具有较长最大上下文窗口的模型在使用这种扩展上下文方面并不一定更好。
2.2 键-值检索
2.2.1 目的
探索输入上下文中匹配和检索相关信息的基本能力
2.2.2 模型
- claude-1.3
- claude-1.3-100k
- gpt-3.5-turbo-16k-0613
- mpt-30b-instruct
- longchat-13b-16k
评估指标:使用准确性作为评估指标,评估预测输出中是否出现了正确的值。
2.2.3结果分析

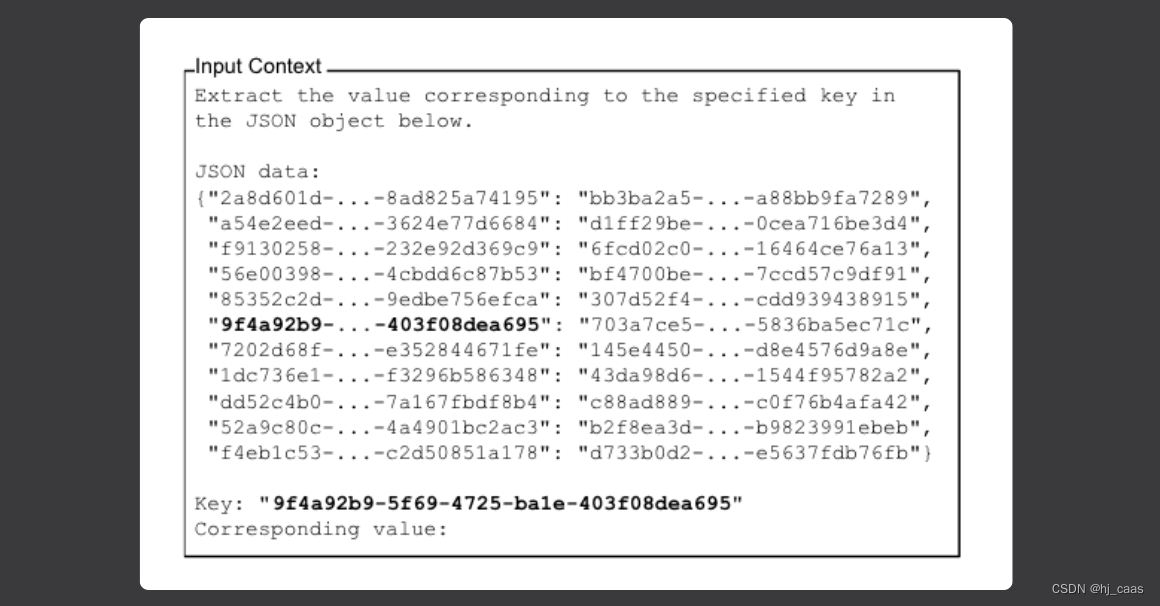
为了调整该任务中的输入上下文长度,通过添加或删除随机键来改变输入JSON键值对的数量,从而改变干扰器键值对的数目。(见下图)
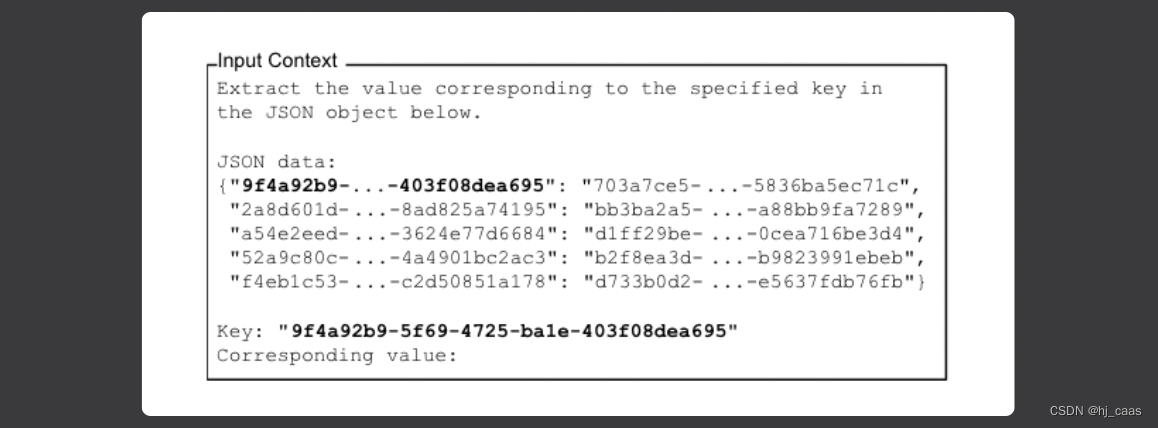
为了调整输入上下文中相关信息的位置,在序列化的JSON对象中更改要检索的键的位置。(见下图)
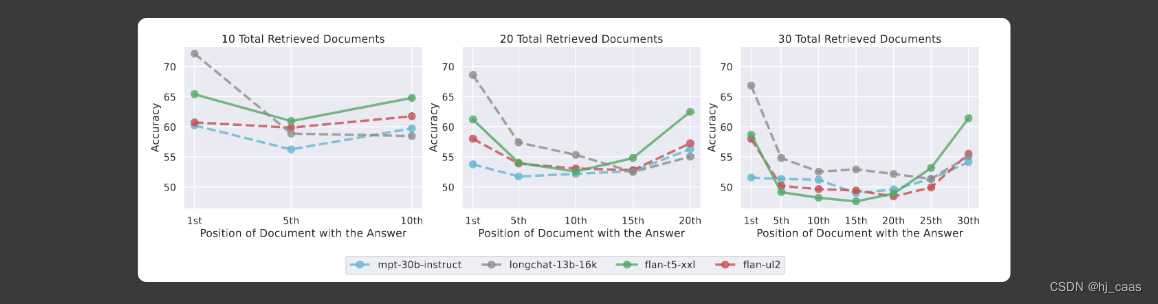
实验结果显示在输入上下文的中间访问键值对时,模型性能最差。此外,这种设置下的模型性能通常也会随着输入上下文的增加而降低。
LongChat-13B(16K)在140键值设置中是一个显著的优势;当相关信息位于输入上下文的开头时,它倾向于生成代码来检索键,而不是输出值本身。

2.3 模型架构分析
2.3.1目的
为了更好地理解模型架构对语言模型使用上下文的潜在影响,比较了仅解码器和编码器-解码器语言模型。
2.3.2 结果分析
Flan-UL2在其2048训练时间上下文窗口内的序列上进行评估,其性能对输入上下文中相关信息的位置变化相对稳健。当在序列长于2048个令牌的设置上进行评估时,当相关信息位于中间时,Flan-UL2性能开始降级。Flan-T5-XXL显示了类似的趋势,当将相关信息放在输入上下文的中间时,输入上下文越长,性能下降越大。
实验结果表明编码器-解码器模型可能会更好地利用其上下文窗口,因为它们的双向编码器允许在未来文档的上下文中处理每个文档,从而可能增强文档之间的相对重要性。
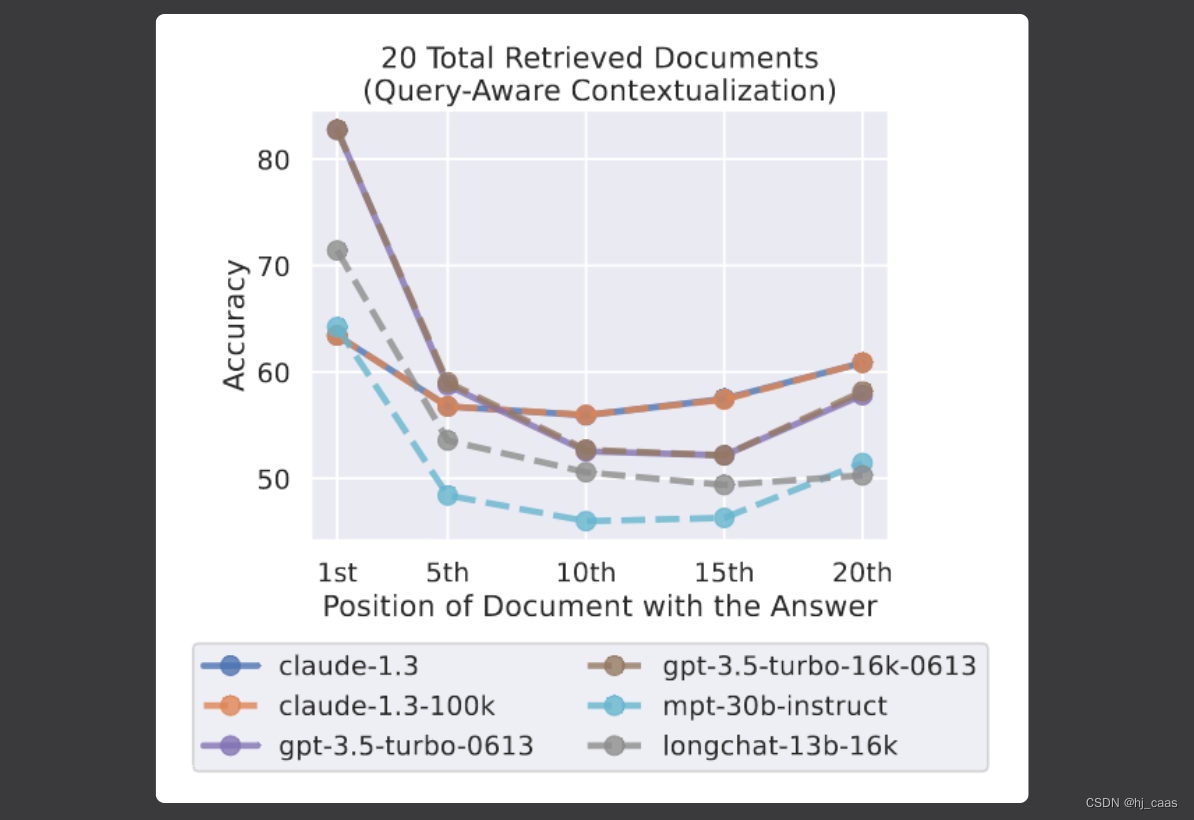
当相关信息出现在最开始时,查询感知上下文化(即,将问题放在输入上下文中的文档之前和之后)提高了多文档QA性能,但在其他情况下会略微降低性能。
实验过程显示下图两种模型都有一条U形性能曲线,当相关信息出现在输入上下文的开始或结尾时,性能要高得多,这表明指令调优过程本身不一定对这些性能趋势负责。

2.4 总结
多文档问答和键值检索结果表明,当语言模型必须在长输入上下文中访问相关信息时,其性能会显著下降。
在对文档或键值对进行上下编码时,只有解码器的模型无法查询标记,因为查询只出现在提示的末尾,而只有解码器的模型在每个时间步只能处理前面的标记。另一方面,编码器-解码器模型使用双向编码器对输入上下文进行上下编码,并且似乎对输入上下文中相关信息的位置变化更具鲁棒性——可以使用这种直觉,通过在数据之前和之后放置查询,启用文档的查询感知上下文化(或键值对),来提高仅解码器模型的性能。查询感知的上下编码大大提高了键值检索任务的性能。
当使用指令格式的数据提示时,语言模型能够使用更长范围的信息(即输入上下文的开始)。增加输入上下文长度通常是一种折衷——为指令调整语言模型提供更多信息可能有助于改善下游任务性能,但也会增加模型必须推理的内容量。
3. Conclusion
实验证实将相关信息放在长输入上下文的开始或结尾有利于检索。长输入上下文越长模型性能越低。
仅解码器模型更加关注相关信息的位置,编码器-解码器模型对相关信息的位置具有一定的鲁棒性。
Reference
- https://www.writebug.com/article/1fc384b0-1f88-11ee-ad3c-0242ac1b000f