论文解读:Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models

核心要点
- 针对大模型幻觉问题进行综述,从detection、explanation和mitigation三个方面进行介绍;
- 对幻觉现象和评估基准进行归纳,分析现有的缓解幻觉的方法,讨论未来潜在的研究发展
- 相关文献整理:https://github.com/HillZhang1999/llm-hallucination-survey
一、什么是大模型的幻觉
大模型幻觉的三种类型:
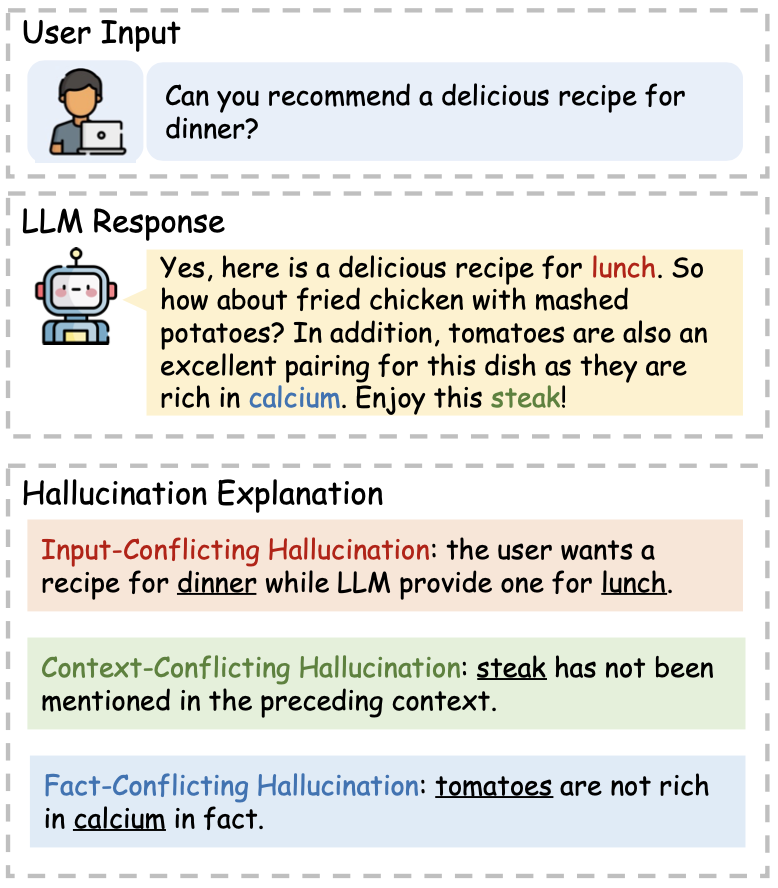
- 生成的内容与输入存在冲突:Input-conflicting hallucination, where LLMs generate content that deviates from the source input provided by users;
- 生成的内容中,前后矛盾:Context-conflicting hallucination, where LLMs generate content that conflicts with previously generated information by itself;
- 生成的内容中有事实性错误:Fact-conflicting hallucination, where LLMs generate content that is not faithful to established world knowledge.
更多的例子如下表所示:
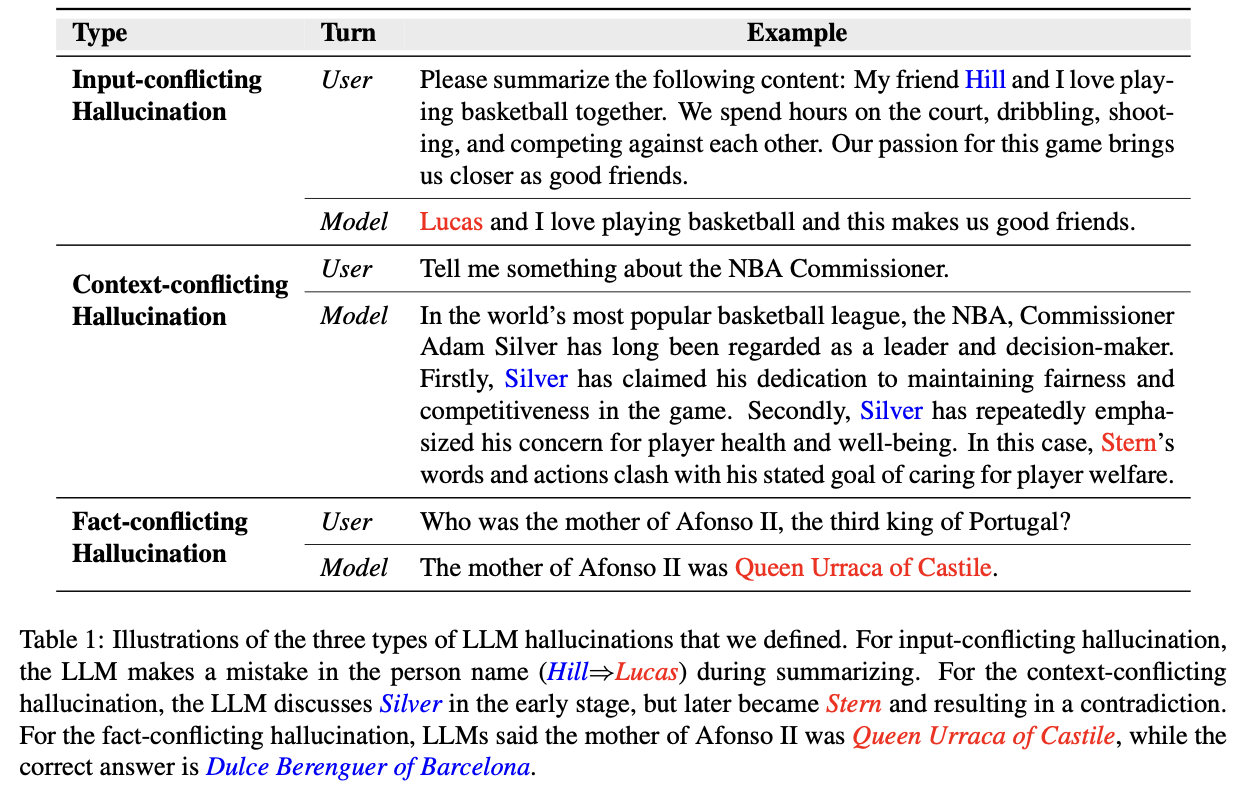
(1)Input-conflicting hallucination
通常存在两种情况:
- 输入的input是一个用户指令,而大模型给出的结果与指令不相关,或存在一些冲突;
- 输入的input是一个文档,例如做文本摘要和机器翻译任务,大模型给出的结果与文档内容存在冲突;
例如下表,Lucas与Hill存在冲突问题。

(2)Context-conflicting hallucination
表示大模型生成的内容存在自相矛盾的现象。通常出现这种情况是因为:
- 大模型在上下文状态追踪和一致性上存在缺陷;
- 在长程记忆方面存在不足;
如下表,一直在说Silver,可是说着说着提到了Stern。

(3)Fact-conflicting hallucination
大模型生成的内容存在一些事实错误,即与事实知识和常识存在冲突。
如下表:询问一个事实性问题时,大模型给出的结果是错误的。

大模型的幻觉问题相比其他特定任务(例如摘要、翻译),具备下面三个新的特性:
- 大模型的训练数据是超大规模的,对于消除编造、过时和存在偏见的信息较为困难;
- 大模型的功能广泛:通用大模型在跨任务、跨语言和跨领域环境中表现出色,这对综合评估和缓解幻觉提出了挑战;
- 错误难以察觉:大模型可能会生成出看起来非常可信的虚假信息,这使得模型甚至人类都难以检测幻觉。
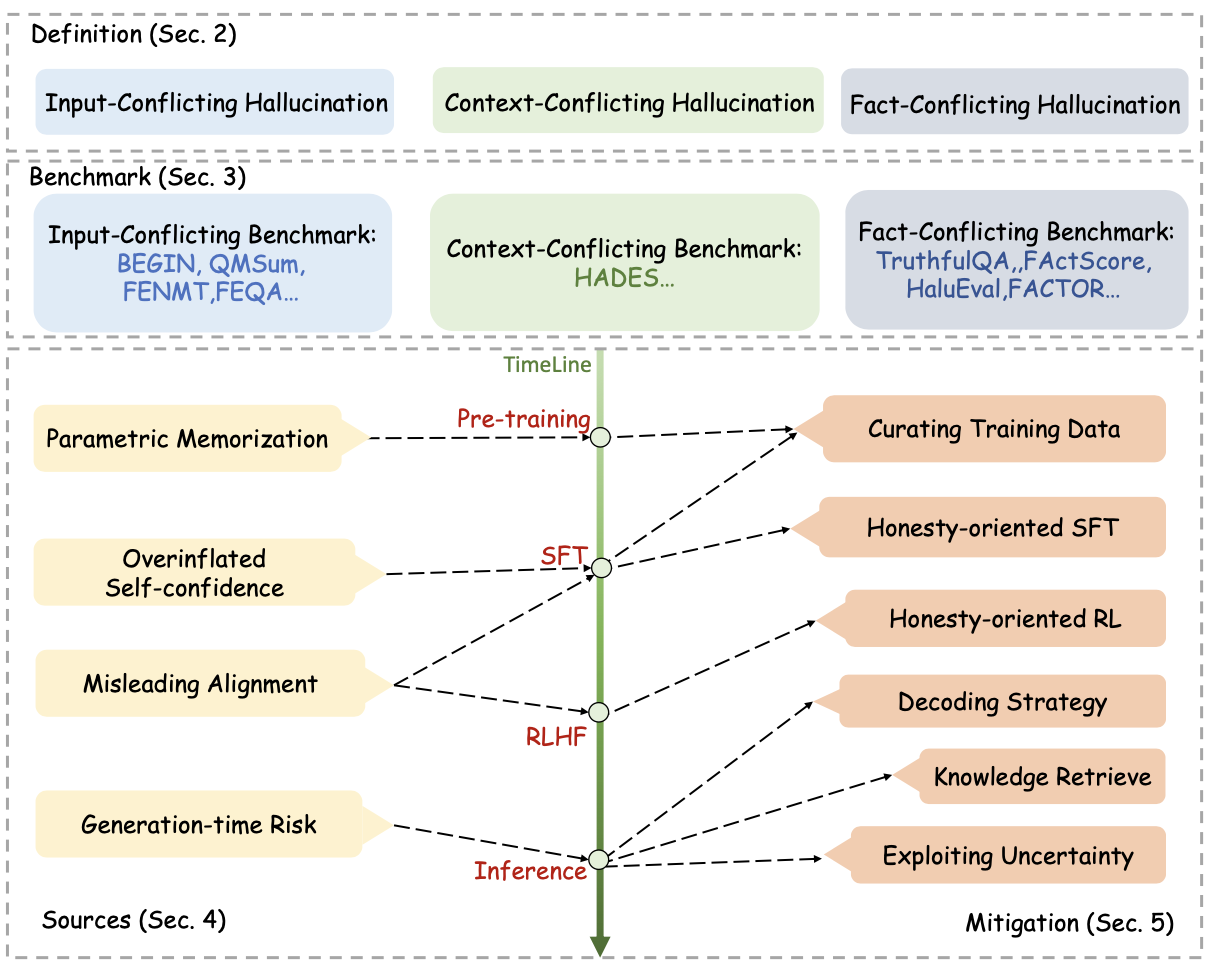
大模型幻觉定义、评测基准和各个阶段缓解幻觉的方法总揽图:
二、大模型的幻觉评估方法与评价指标
两种主要的幻觉评估模式:
(1)Generation:直接评测大模型生成的文本中事实陈述部分是否正确。
通常是一个事实性问题,直接让大模型生成结果,然后去判断生成的结果是否正确;

一些经典的generation评估方法:
- TruthfulQA:人工构建若干问题,其中437个困难问题(GPT-3无法准确回答)和380个常规问题。人工评估时,根据大模型在对这些问题的回答,进行人工打分;自动评估时,在这些问题上训练一个GPT-3-6B的模型,然后用这个模型对大模型生成的内容进行打分。参考博客:TruthfulQA: Measuring How Models Mimic Human Falsehoods 论文解读
- FActScore:通过人物传记来判断模型生成的内容是否符合事实。
还有一种是Knowledge Probing,设计一些事实性相关的完形填空类型的问题(或者填空在文本末尾),让模型生成结果。可以是多项选择模式,也可以是填空题目。
(2)Discrimination:让大模型能够区分是否符合事实。
通常是一个多项选择的问题,判断大模型是否能够做对选择题。

一些经典的discrimination方法:
- HalEval:给定一个问题和正确答案,设计一些指令让GPT-4生成存在幻觉的文本,构造出类似多项选择题,通过模型筛选出高难度幻觉的文本,并通过人工标注方法标注出存在幻觉的区间。在评估大模型事实性时候,设计prompt让大模型从所有选项中选出正确答案,或者直接让大模型判断给定的一个生成结果是否符合事实。参考博客:HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models_华师数据学院·王嘉宁的博客-CSDN博客
- FACTOR:类似一个多项选择,判断大模型对正确的选项给出的likelihood是否是最大的;
- TruthfulQA:也提供了多项选择的模式;
下表展示了几种评估基准方法:
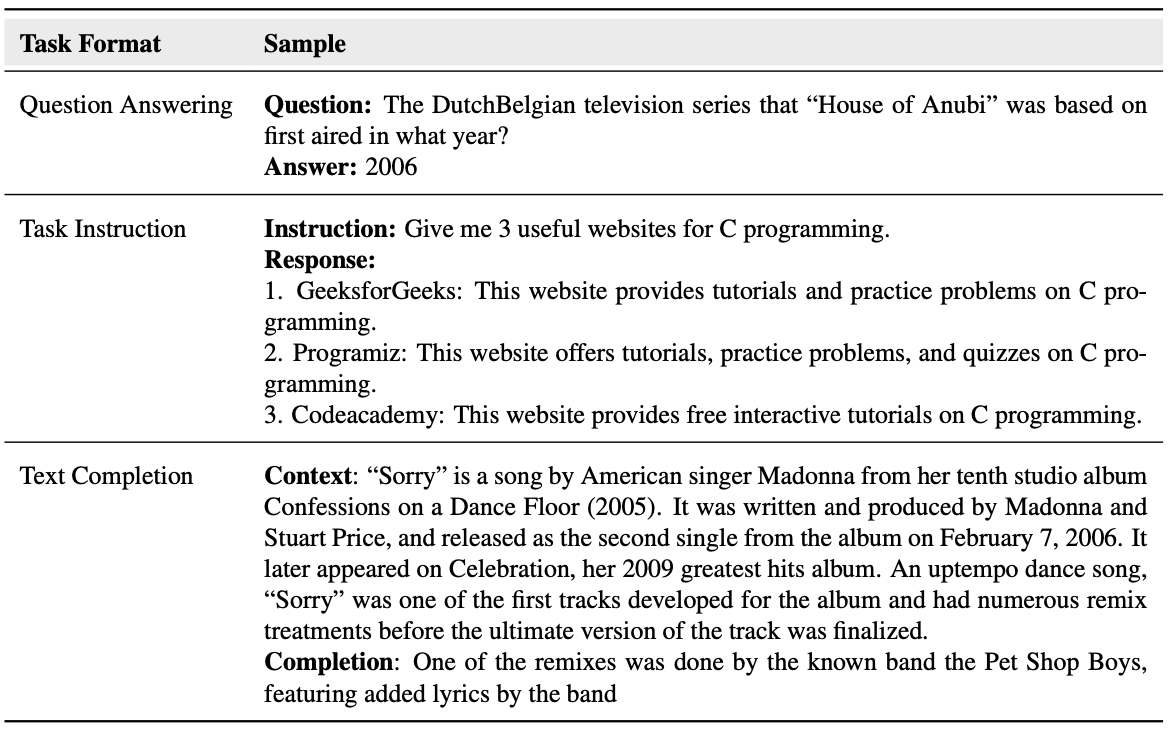
- QA:设计一些问题,让大模型进行生成,然后通过人工或者自动评估方法进行打分。典型代表:TruthfulQA;
- 任务指令:设计一些指令让大模型生成结果;典型代表:HalEval
- 补全类:给出一些prefix,让大模型接着生成,判断生成的内容是否符合事实,是否与prefix存在冲突。典型代表:FACTOR
评估的指标通常有两种:
(1)人工评估
通常是对标注人员进行培训。当给定一个问题和一个候选答案时,要求标注人员根据特定要求对候选答案进行打分。典型代表:TruthfulQA、FactScore。
但是人工评估方法存在有偏性,同时成本比较高。
(2)基于模型的自动评估
通常是在构建好的评测基准上,训练一个打分模型。
- TruthfulQA:在几百个设计标注的基准上,使用GPT-3-6.7B训练一个二分类模型GPT-Judge,这个二分类模型的准确性可以达到90~96%的准确性,因此当给出一个新的问题和候选答案时,可以较为准确地给予事实性得分。
- AlignScore:提出一个Align函数,来判断大模型生成的内容与输入的内容是否符合事实一致性。其从大量的NLI、QA、paraphrasing等任务上训练一个二分类模型,用来判断两个文本是否存在蕴含关系;
- FactScore:当给定一个问题和大模型生成的答案。首先根据问题,使用一个通用的T5模型作为retriever,检索相关的知识,其次使用一个LLaMA-65B模型来根据检索到知识,来判断大模型生成的答案是否符合事实性。最后用F1和错误率来判断这种评估方法的可靠性,并与人类评估进行相关性分析。
- Self-contradictory:让大模型对一个问题生成两次,并使用一个ChatGPT来判断生成的两个内容是否冲突。
(3)基于规则的自动评估
对于discrimination的评估方法,可以直接使用准确率作为评价指标。如果对于generation方法,可以判断生成的内容和输入内容中实体的重叠率,可以采用Rouge-L或F1指标完成。
三、引起大模型幻觉的因素
(1)大模型缺乏领域相关的知识,或者训练时注入错误的知识
- 训练数据中和目标测试问题存在分布差异性,模型生成内容更偏向于训练数据,但是却是错误的内容;
- 训练数据可能是有偏的、过时的,或者存在大量的谎言
(2)大模型高估了自己的生成能力
大模型通常会对自己生成的内容给予很高的置信度,但是实际上是错误的内容。
大模型有时候没有拒识能力,对自己的知识边界比较模糊。
(3)存在问题的对齐策略可能会让模型退化
- 大模型的对齐需要简历在其具备某个必备的知识,如果本身不具备这个知识,那么对齐可能就会促使模型生成幻觉问题;
- 大模型可能会被用户干扰、诱骗,从而生成幻觉内容;
(4)大模型的生成策略存在不足
- 滚雪球式幻觉:大模型生成是自回归模式,可能先前生成的错误信息,大模型无法对其进行纠正,导致错上加错;
- 模型训练和推理阶段存在差异;
- top-p采样问题,p值越大模型的创造性越强,越容易产生幻觉;
四、缓解大模型幻觉的方法
根据大模型训练的四个生命周期,分别介绍缓解幻觉的方法。
4.1 预训练阶段
模型在训练过程中,如果存在错误的知识,会在根源上让大模型产生幻觉。
因此缓解的方法是对预训练数据进行处理,筛除掉可能错误的数据。(the curation of pre-training corpora)
本人认为还有一个关键要素是需要在预训练阶段注入事实知识。
4.2 SFT阶段
(1)curating sft data
在SFT阶段缓解幻觉的方法也是对数据进行处理,筛除错误数据。在TruthfulQA上实验表明,经过curating的指令微调数据上训练明显要好于原始操作。
(2)行为克隆
SFT的另一个解释是行为克隆,即SFT只是教会模型如何回答一个问题(类似强化学习中action),但是并不知道如何较为准确地回答(相当于没有一个策略引导)。
SFT阶段本质上是让大模型如何利用好参数内的知识来与人类进行交互。然而,SFT训练数据中包含的知识可能是大模型预训练阶段没有见过的,从而间接教会大模型编造,大模型在生成时可能会寻找与之类似的信息。即需要大模型具备自我知识边界认知能力(拒识能力)。
forcing LLMs to answer questions that surpass their knowledge boundaries.
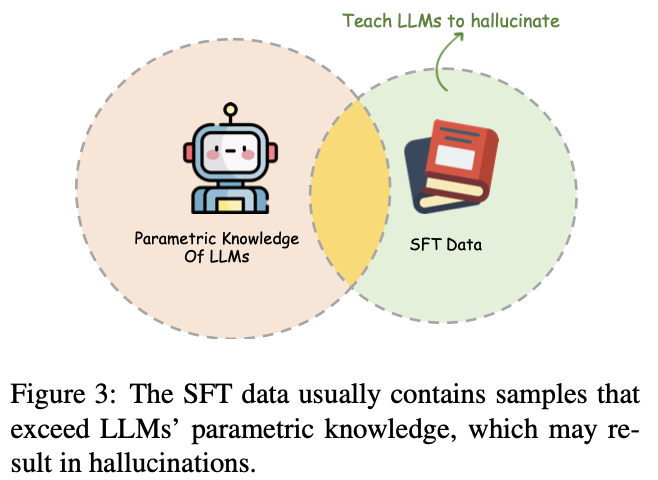
解决方法是honesty-oriented SFT,即在sft数据中添加一些“Sorry,I don’t know”的数据。
本人认为拒识数据需要划分两种类别:
- 针对问题本身的拒识:掺入一些本身就没有答案的问题,例如“宇宙的直径是多少”;
- 针对模型的拒识:问题本身是存在正确答案的,但是如果模型本身如果没有学习过这个知识,不能胡编乱造。例如让一个医疗大模型去回答文学问题,它不能胡编乱造。
另外还要防止模型过度拒识。
4.3 RLHF阶段
对齐阶段的目标就是让大模型能够在helpful、honest和harmless等方面与人类价值观对齐,通常训练一个reward模型来评价文本在这几个方面的得分,并采用PPO算法不断地优化SFT模型。
在RLHF阶段缓解幻觉的简单思路就是单独再设计一个针对幻觉的reward score,并直接在RLHF阶段优化即可,如下所示:
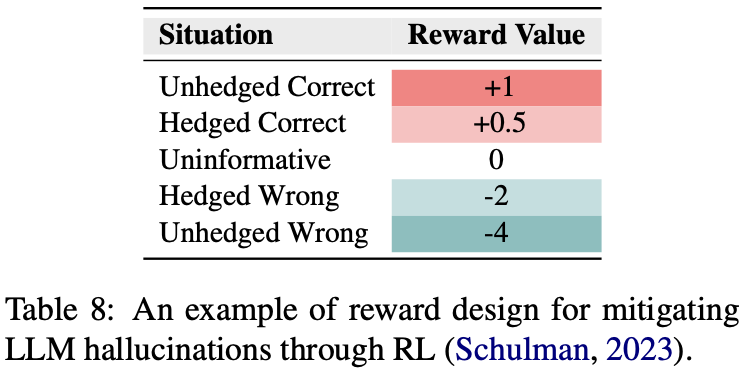
这类似于在SFT阶段执行拒识。
不过RLHF存在一些挑战:
- 可能会让模型过度“保守”(over-conservatism)
- 过度避开回答一些大模型本身知道的问题,或者重复生成等问题;
4.4 模型推理阶段
(1)Decoding策略
- Top-p采样(核采样)方法是一种贪心采样方法,会导致模型生成的结果更具有创造力,但也会降低事实性。一种方法就是设计动态top-p采样。代表方法为《Factuality Enhanced Language Models for Open-Ended Text Generation》。
动态的necleus probability p p p:
p t = max { ω , p × λ t − 1 } p_t=\max\{\omega, p\times\lambda^{t-1}\} pt=max{ ω,p×λt−1}
- λ \lambda λ-decay:随着生成的token数量 t t t增加,逐渐衰减 p p p的取值;
- p p p-reset:当一个句子生成完毕后, p p p的值会因为 t t t的增加而变得很小,当生成新的句子时,期望 p p p能够恢复到原始的值;
- ω \omega ω-bound:为了避免 p p pdecay后过小,设置一个lower bound;
事先分析模型在正确答案上预测时,每个token对应每一层Transformer中每个head的logits。
1)在LLM的每个注意力头之上安装一个二分类器,以识别一组在回答事实问题时表现出卓越的线性探测精度的头
2)在推理过程中,沿着这些与事实相关的方向移动模型激活。
- Context-aware Decoder:《Trusting Your Evidence: Hallucinate Less with Context-aware Decoding》 两种Decoder模式的集成:
- p ( y ∣ c , x ) p(y|c, x) p(y∣c,x)表示给定检索的上下文 c c c和query x x x的条件下,生成各个结果的概率;
- p ( y ∣ x ) p(y|x) p(y∣x)表示只给定query x x x的条件下,生成各个结果的概率;
- 如果对于某个答案的预测,如果两个概率差异很大,则说明该答案更多来自于上下文而不是来自模型参数的知识,这个答案则越有可能是正确的。
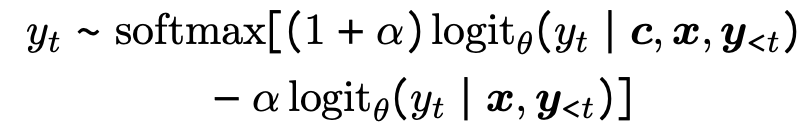
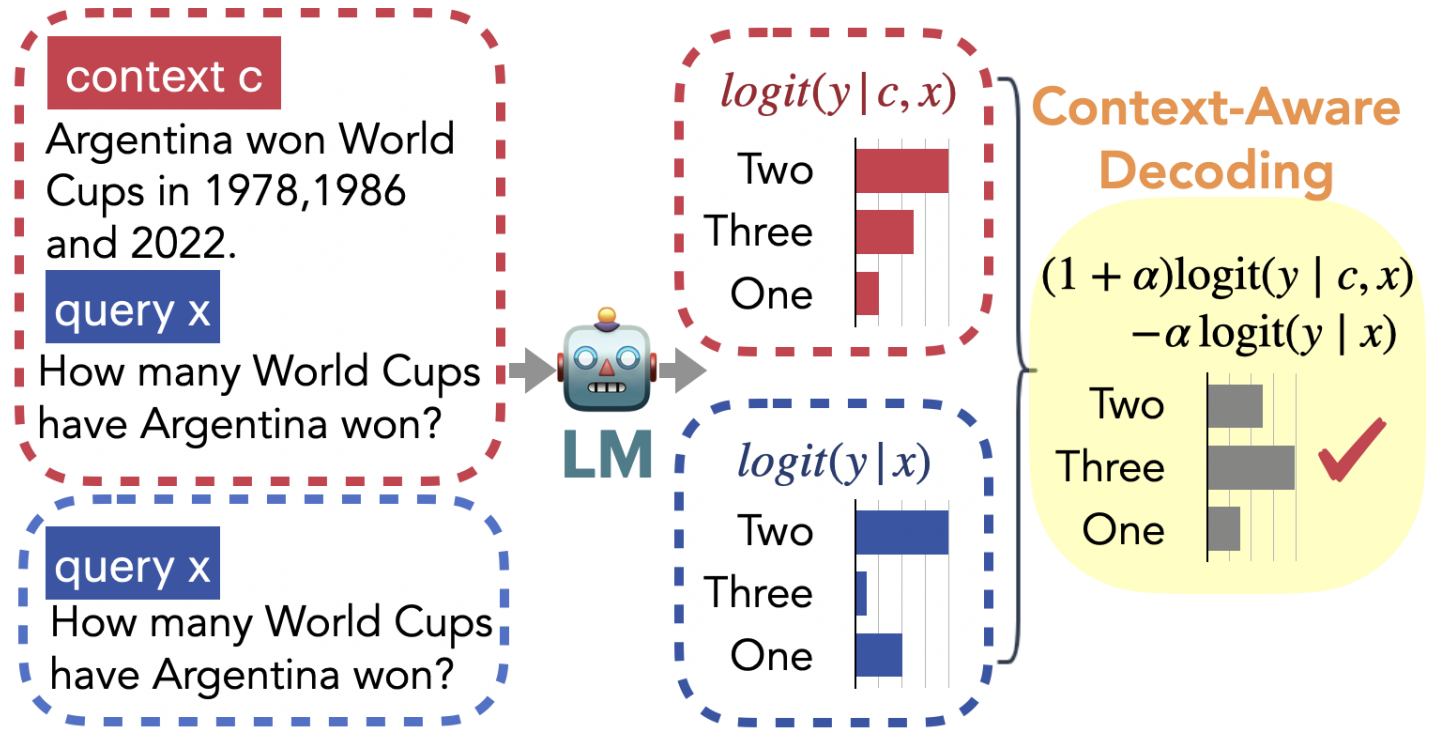
(2)检索外部知识
检索外部知识实现检索式增强是一种直接缓解幻觉的方法。
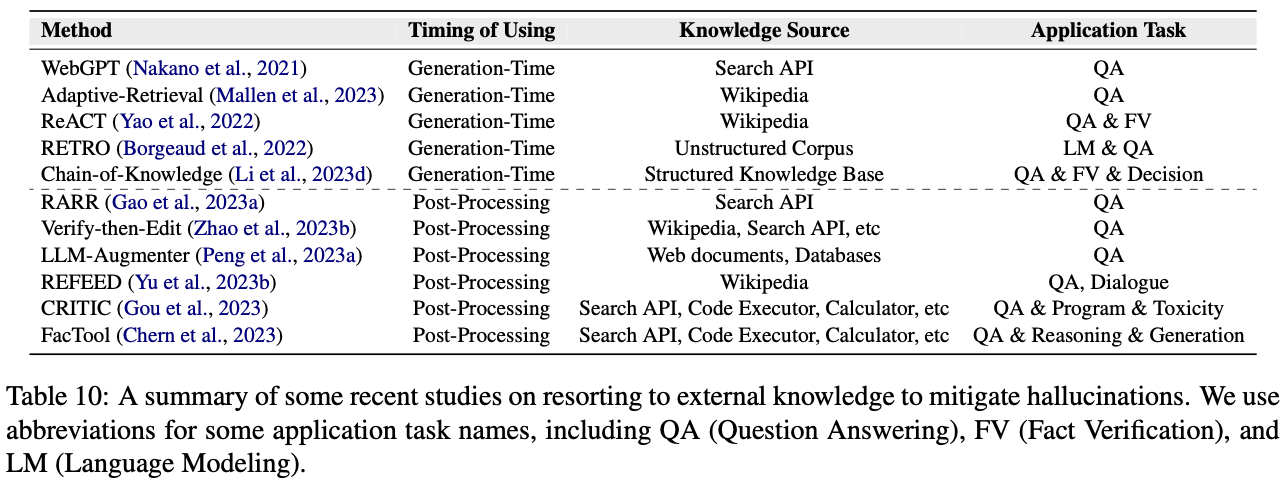
外部知识主要有两种类型:
- 外部知识库:包括互联网上知识库、维基百科、知识图谱等。一般采用BM25、Dense Retrieve、搜索引擎等。
- 外部工具:FacTool开发一些外部API来为不同特定的任务解决幻觉,例如谷歌学术API来检测学术审稿中的准确性等;CRITIC则让达模型与不同的tools进行交互,并对错误的结果进行纠正。
利用外部知识来缓解幻觉的两种思路如下所示:
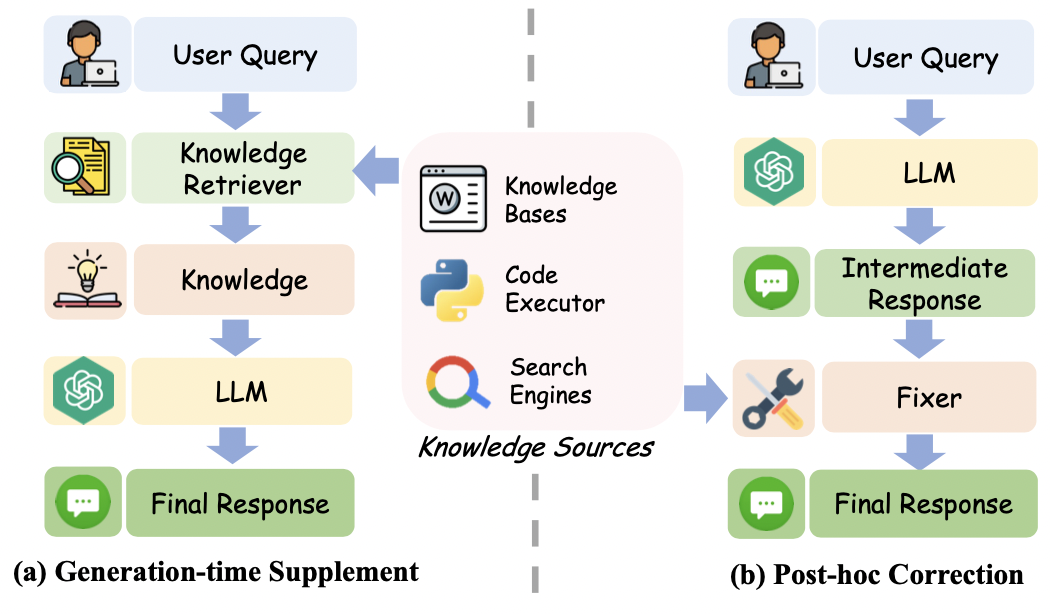
- 将检索到的知识直接与query拼接。
- 将检索到的知识用于生成结果的检验与纠正,此时LLM可以借助外部知识作为一个fixer。
- RARR:让大模型从多个方面寻找content中需要纠正的地方,然后让LLM根据检索到的知识进行纠错;
- Verify-then-Edit:对于模型推理的中间结果进行检验,并检索外部知识对错误的推理过程进行纠正。
- LLM-Augmenter:先让LLM对检索到的知识进行摘要,再让fixer根据摘要对幻觉文本进行纠正
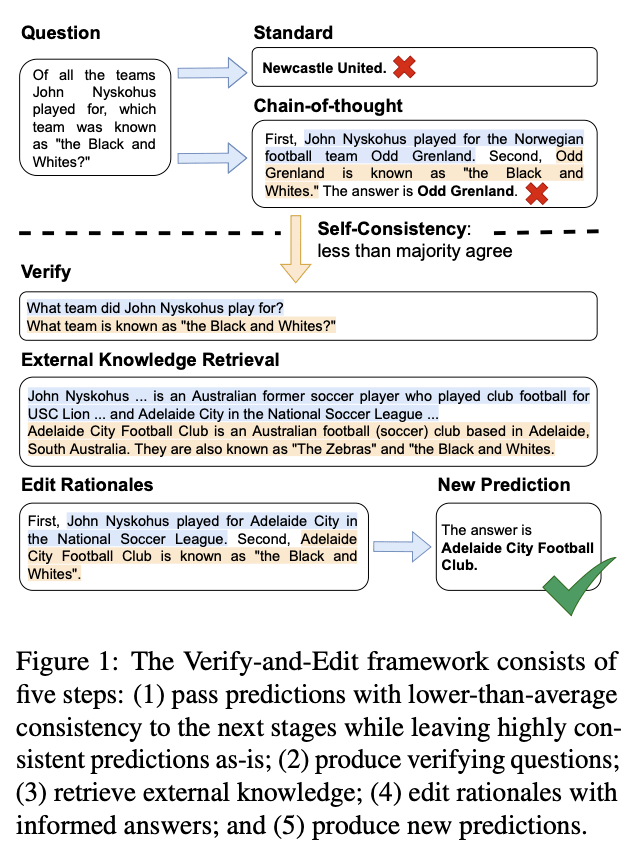
检索式增强有如下几个挑战:
- 检索的知识通常也是来自于互联网,依然会存在错误伪造的信息,因此检索到的知识如何能够验证其可靠性也很关键;
- retriever和fixer的准确性和时间效率也是很重要的部分。确保检索知识和纠错的性能很高才可以;
- 检索到的知识与参数知识可能存在冲突
(3)不确定性
模型预测结果的不确定性可以评估模型对生成结果的确信程度。如果能够准确地获取到模型生成的结果的不确定程度,则可以有效地对这部分内容进行筛除或改写。
评估模型生成结果的不确定性,关键工作为《Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms》,主要有三种方法:
- 根据logits或信息熵来评估。代表工作:《On calibration of modern neural networks.》
- 代表方法:《A stitch in time saves nine: Detecting and mitigating hallu- cinations of llms by validating low-confidence generation》通过logits寻找存在幻觉的部分,然后用外部知识和额外的LLM作为fixer进行纠正;
requires access to the model logits and typically mea- sures uncertainty by calculating token-level probability or entropy.
- Verbalize-based:设计指令,直接让模型输出其对该问题回答的确信程度。例如添加指令:Please answer and provide your confidence score (from 0 to 100)。可以配合CoT来提升效果;
- 代表方法:《Do language models know when they’re hallucinating references?》
- Consistency:让模型对同一个问题生成多次,并根据答案的一致性来判断。如果模型生成的多次结果过于不一致,则说明其对该问题会产生幻觉;
- 代表方法:SelfCheckGPT
4.5 其他方法
(1)多智能体交互
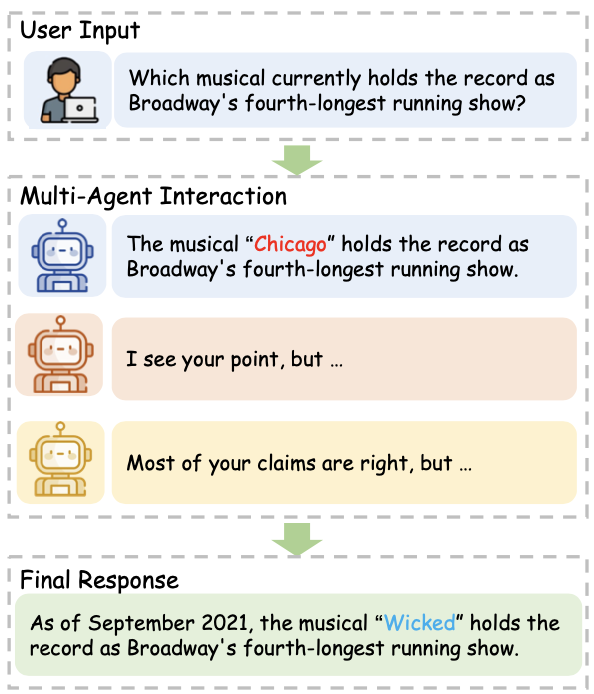
- 如果只让一个大模型生成结果,则比较容易产生幻觉。但是如果多个大模型辩论的形式回答,则可以缓解这个问题:《Improv- ing factuality and reasoning in language mod- els through multiagent debate》
- 设计两个LLM,一个负责生成内容,一个负责检查:《Lm vs lm: Detecting factual errors via cross examination》
- 一个LLM同时扮演多个角色:《A task-solving agent through multi- persona self-collaboration.》
(2)提示工程
不同的prompt也可能会导致幻觉。可以采用CoT提升推理能力避免幻觉。另一方面设计system prompt时,告知模型不要胡编乱造,例如在LLaMA2-Chat中,设置“If you don’t know the answer to a question, please don’t share false information”
(3)Human-in-the-loop
代表工作:《Mitigating language model hallucination with interactive question-knowledge alignment》
(4)优化模型结构
更多丰富的decoder结构:
- multi-branch decoder:《Controlling hal- lucinations at word level in data-to-text generation》
- uncertainty-aware decoder:《On hallucination and predictive uncertainty in conditional language generation》
- 双向decoder结构:《Batgpt: A bidirectional autoregessive talker from gener- ative pre-trained transformer》
五、其他方面
(1)更合适的评估方法
目前的评估方法还有一些不足,表现在:
- 自动评估方法与人类的评估存在差异;
- discrimination和generation两种类型的评估方法是否能够准确表示模型的幻觉,在不同的任务上是否能够具有通用性等问题,还有待继续研究;
(2)多语言幻觉
同一个问题,英文提问时可以回答的准确,但是换成中文提问时则会出错,说明模型的幻觉会在不同语言上表现不同。这往往容易出现在low-resource language上。

(3)多模态幻觉
一些多模态模型,会将视觉encoder更换为LLM。但是此时也会出现幻觉问题。
多模态场景下的一些幻觉评测基准包括:
- GPT4-Assisted Visual Instruc- tion Evaluation (GAVIE)
- M-HalDetect
(4)模型编辑
模型编辑有两种类型,直接在模型参数或结构上消除模型的幻觉:
- 利用一个辅助的sub-network:《Memory-based model editing at scale》、《One mistake worth one neuron》
- 直接更改模型的参数:《Locating and editing factual associations in gpt》
(5)攻击与防御
如何防止有些prompt是恶意的和精心设计的圈套,避免模型吐出幻觉或错误的信息。
- 《Jailbroken: How does llm safety training fail?》
- 《Promptbench: Towards evaluating the robustness of large language models on adversarial prompts》
Several studies show that LLMs can be manipulated using techniques like meticulously crafted jailbreak prompts to elicit arbitrary desired responses
(6)其他
LLM-as-a-agent场景下,大模型如何缓解幻觉是一个新的挑战。