文章目录
摘要
讨论了机器语言智能的发展,特别是大规模预训练语言模型(PLMs)。该综述详细介绍了语言模型从统计语言模型,神经语言模型到预训练语言模型(PLMs)的演变。作者强调,大规模LLM超出某一参数大小的模型扩展导致了新的能力的出现。这种现象导致了强大的人工智能聊天机器人的创建,例如ChatGPT,可以解决复杂的任务,展现了与人类极佳的对话能力。该综述强调了评估和了解LLMs的性能的必要性,包括它们的预训练、适应性调整、利用和容量评估。本文解释了LLMs的发展不仅仅限于学术研究,而且还涉及大规模数据处理和分布式并行计算的实践经验。该综述对LLMs的文献进行了全面回顾,对研究人员和工程师都是一个有用的资源。
介绍
语言是人类最重要的交流方式,但机器不能自然地掌握和使用人类语言。语言建模是提高机器语言智能的主要方法之一,它旨在预测未来(或缺失)令牌的概率。LM的研究已经经历了四个发展阶段。实现让机器像人类一样阅读、写作和交流一直是一个研究挑战。
- 统计语言模型(SLMs)是基于马尔可夫假设的单词预测模型,通过预测下一个单词来提高任务性能,在信息检索(IR)中广泛应用。N-gram语言模型是一种特殊的SLMs,其中固定上下文长度n,如bigram和trigram语言模型。然而,高阶语言模型估计存在数据稀疏问题,导致很难准确估计转换概率,因此需要专门设计的平滑策略,如后退估计和Good-Turing估计。
- 神经语言模型(NLM)是通过神经网络表征单词序列的概率的模型。NLM的发展经历了许多里程碑式的研究,如引入单词的分布式表示的概念、通过扩展学习单词或句子有效特征的思想,开发了一种通用神经网络方法,并且构建了一个简化的浅层神经网络word2vec来学习分布式单词表示。这些研究开创了语言模型在表示学习中的应用,对自然语言处理领域产生了重要影响。
- 预训练语言模型(PLM)是NLP任务中的重要工具,早期的尝试如ELMo和基于自注意机制的高度并行化Transformer架构的BERT被提出。这些预先训练的上下文感知词表示作为通用语义特征非常有效,可以极大地提高NLP任务的性能标准。后续工作引入了各种不同的架构和改进的预训练策略。通常需要对PLM进行微调以适应不同的下游任务。
- 缩放大型语言模型(PLM)通常会提高模型容量和性能,研究团体为这些大型PLM创造了术语“大型语言模型(LLM)”。虽然缩放主要是在模型大小上进行的,但大型PLM与小型PLM表现出不同的行为,并在解决复杂任务时表现出惊人的能力。ChatGPT2是LLM的一个显著应用,可以与人类进行惊人的对话。
本文介绍了自然语言生成模型(LLM)的最新进展,重点关注了其开发和使用的技术和方法,概述了预训练、适应调整、利用和能力评估四个方面的最新进展。LLM与小型PLM具有三个主要的区别,包括展示出令人惊讶的涌现能力、改变了人类开发和使用AI算法的方式以及在培训中涉及了大规模数据处理和分布式并行训练等工程问题。虽然LLM取得了进步和影响,但其基本原则仍未得到很好的探索。此外,由于模型预训练成本巨大且许多细节不对公众透露,研究界很难为其培训有能力的LLM。文章指出,LLM的研究与开发具有机遇与挑战并存的特点,值得重视。最后,文章总结了本次调查的主要发现,并讨论了未来工作的剩余问题。
回顾
在本节中,我们将介绍LLM的背景,包括关键术语、能力和技术。
背景 大型语言模型是指拥有数千亿参数的在大量文本数据上进行训练的语言模型,其采用Transformer架构和预训练目标,并通过缩放模型大小、预训练数据和总计算来提高理解自然语言和生成高质量文本的能力。模型大小的增加大致遵循比例定律,但一些能力只有当模型大小超过一定水平时才能观察到。
LLM具有紧急能力 其涌现能力在大型模型中出现,而在小型模型中不存在。当涌现能力出现时,当量达到一定水平时,其绩效显著高于随机水平。LLM的涌现模式与物理学中的相变现象密切相关。LLM具有三种典型涌现能力,可以应用于解决多个任务的一般能力。
- GPT-3可以进行上下文内学习,通过完成输入文本的单词序列为测试实例生成预期的输出,而不需要额外的训练或梯度更新;
- 通过指令调优,它能够在不使用显式示例的情况下通过理解任务指令来执行新的任务,从而提高泛化能力;
- 使用思维链推理策略,可以利用包含中间推理步骤的提示机制解决复杂任务。这种能力可能是通过代码训练获得的。
LLM的关键技术 LLMs是一种具有高学习能力的机器学习模型,经过长时间的发展,其关键技术不断提升,提高了LLMs的能力,其中几个成功的重要技术包括:技术提高了LLMs的精度和效率。
本文讨论了语言模型的优化方法,主要包括可伸缩性、激发能力、对齐调整和使用外部工具。可伸缩性是提高模型容量的关键因素,该方法需要考虑模型大小、数据大小和总计算量三个方面的最优调度。激发能力涉及到设计合适的任务指令或特定的情境策略来培养模型的解决问题的能力。对齐调整是保证模型与人类价值观相一致的方法,避免模型产生有毒、有偏见、对人类有害的内容。最后,使用外部工具可以弥补模型在文本生成和获取最新信息方面的缺陷。通过这些方法,可以构建更加可靠和有效的语言模型。
此外,许多其他因素(如硬件的升级)也有助于LLM的成功。同时,我们将讨论局限于开发llm的技术方法和关键发现。
LLMS资源
开发或复制LLM并不容易,考虑到技术问题和计算资源需求。一种可行的方法是利用现有LLM经验和公共资源进行增量开发或研究,这包括开源模型检查点和api、可用的语料库以及LLM的有用库。本节主要总结这些资源。
公开可用的模型检查点或API
模型预训练所需的巨额成本使得良好训练的模型检查点至关重要。由于参数规模是使用LLMs的关键因素,因此我们将这些公共模型分为两个规模级别(即数十亿参数或数百亿参数),这有助于用户根据其资源预算选择适当的资源。此外,对于推断,我们可以直接使用公共API来执行任务,而无需在本地运行模型。本节简要总结了LLMs的公共检查点和API的使用情况。
具有数十亿个参数的模型
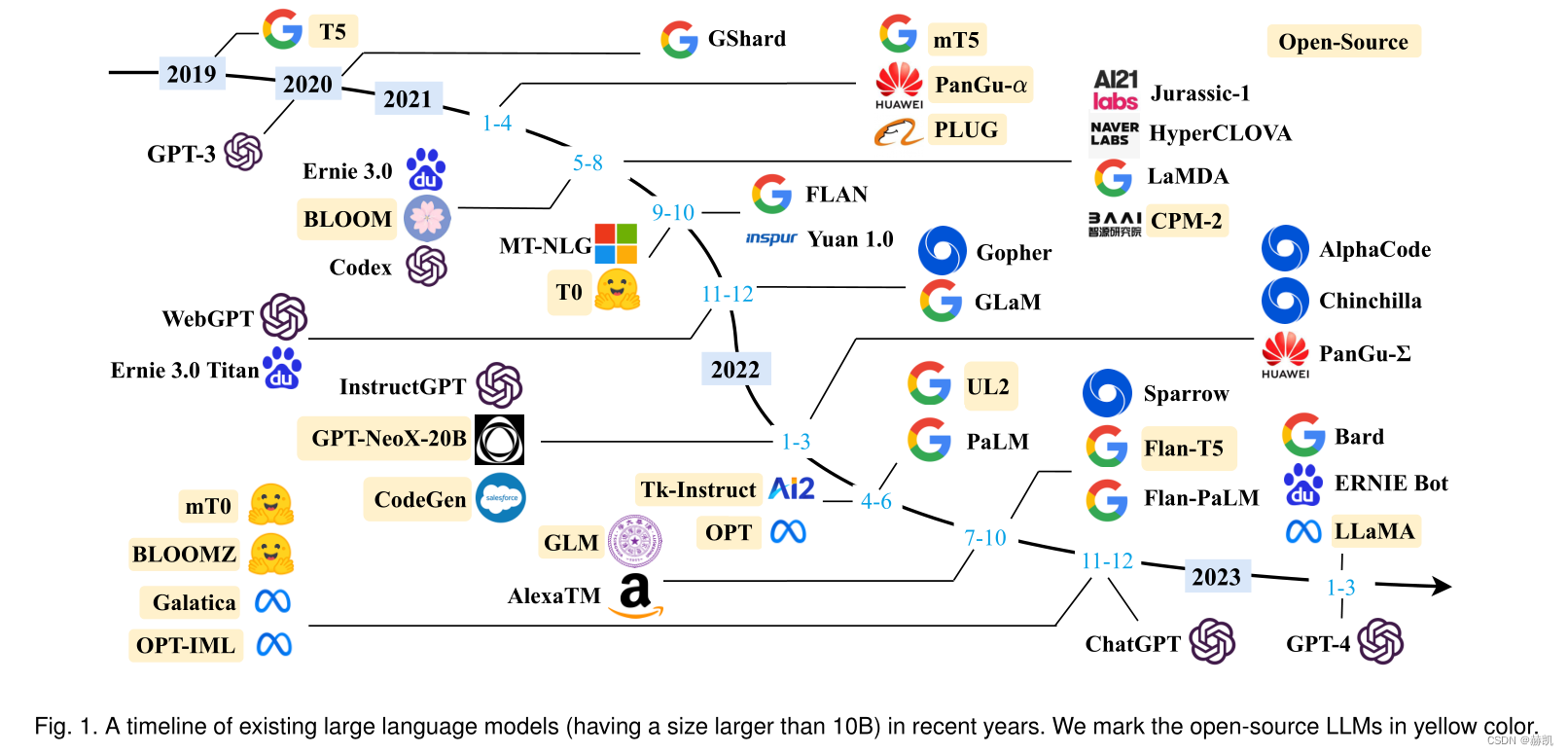
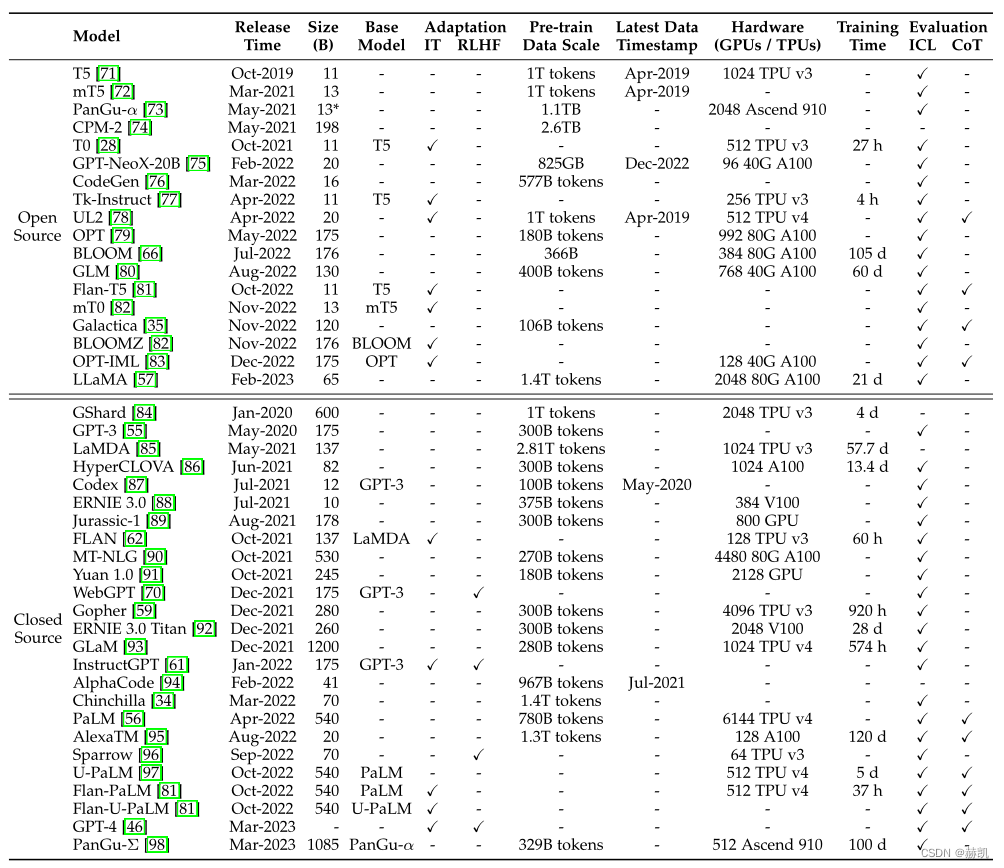
大多数开源模型的参数规模在10B-20B之间,而LLaMA最大版本包含65B个参数。其他模型包括mT5、T0、GPT-NeoX-20B、CodeGen、UL2、Flan-T5、mT0和pangua。在这些模型中,Flan-T5(11B版本)适合指令调优研究,CodeGen(11B版本)适合生成代码。多语言任务可以考虑mT0(13B版本)。盘古-α在中文下游任务中表现良好,最大版本有200B个参数,而LLaMA则需要数千个gpu或tpu。例如,GPT-NeoX-20B使用12个超微服务器,而LLaMA使用2048个A100-80G gpu。建议使用FLOPS来评估所需的计算资源。
具有数千亿个参数的模型
一些具有数千亿个参数的模型,只有少数被公开发布,如OPT[79]、OPT-iml[83]、BLOOM[66]和BLOOMZ[82]等。其中,OPT(175B版本)被用于开源共享,能够用于大规模可重复的研究。这些模型需要数千个gpu或tpu进行训练。Galactica、GLM和OPT-IML已经使用指令进行调优,可能成为研究指令调优效果的良好候选者。BLOOM和BLOOMZ可以作为跨语言泛化研究的基础模型。
LLM公开API
该API不需要在本地运行模型,为用户提供方便的使用方式。其中GPT系列模型的API被广泛应用,包括7个主要接口:ada、babbage、curie、davinci、text-ada-001、text-babbage-001和text-curie-001。这些接口可以在OpenAI的主机服务器上进一步调优。巴贝奇、居里和达芬奇分别对应不同版本的GPT-3模型,此外还有与食典相关的API和GPT-3.5系列等增强版本。最近发布了GPT-4系列API,具体选择取决于应用场景和响应要求。详情请参见项目网站。
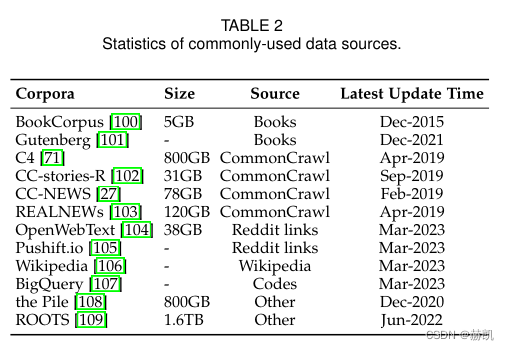
常用语料库
LLMs需要更多的训练数据,因为它由大量参数组成,需要涵盖广泛的内容。为了满足这一需求,越来越多的训练数据集被发布用于研究。根据内容类型,这些语料库被分为六组:书籍、CommonCrawl、Reddit链接、维基百科、代码和其他。
书籍
BookCorpus和古腾堡计划是常用的小规模和大规模图书语料库,其中后者包括7万多本不同的文学书籍。GPT-3使用的较大的Books1和Books2目前还没有公开发布。这些数据集被广泛用于机器翻译、自然语言生成和其他语言处理任务的训练。
CommonCrawl
开源网络爬行数据库CommonCrawl是最大的之一,包含千兆级数据量,但由于web数据中的噪声和低质量信息,需要进行预处理。现有工作中常用的过滤数据集有四个:C4、CCStories、CC-News和RealNews。其中C4包括5个变体,已被用于训练多种模型。CC-Stories是CommonCrawl数据的子集,已经不可用,但有复制版本。此外,从CommonCrawl中提取的两个新闻语料库REALNEWS和CC-News也常被用作预训练数据。
Reddit链接
Reddit是一种允许用户分享链接和文字帖子的社交媒体平台,其他用户可以通过投票来评价这些帖子的质量。一些高质量的帖子可以被用来创建高级数据集,如WebText和PushShift.io。WebText是由来自Reddit平台的高赞帖子组成的一个语料库,但该资源并不是公开的。作为替代方案,人们可以利用开源工具OpenWebText,而PushShift.io则提供了实时更新和全历史数据的数据集,方便用户搜索并进行初步处理和调查。
维基百科
维基百科是一个高质量的在线百科全书,涵盖广泛的主题和领域,并以说明性的写作风格组成。其英文过滤版本常被用于LLMs中,包括GPT-3、LaMDA和LLaMA。同时,维基百科还有多种语言版本,可以在不同语言环境中使用。
代码
工作主要从互联网上抓取开放源代码许可代码,主要来源包括 GitHub 和 StackOverflow;谷歌已经发布了 BigQuery 数据集,包含各种编程语言的开源许可代码片段,CodeGen 利用其中一个子集 BIGQUERY 训练了多语言版本。
其他
Pile是一个大规模、多样化、开源的文本数据集,包括超过800GB的数据,由22个高质量子集组成。Pile数据集被广泛应用于不同参数尺度的模型。ROOTS则涵盖了59种不同的语言,共1.61 TB文本,用于训练BLOOM。
LLMs现在采用多个数据源进行预训练而不是单个语料库。目前的研究使用了多个现成数据集混合处理,还需要从相关来源提取数据来丰富预训练数据。其中,GPT-3、PaLM和LLaMA是具有代表性的LLMs,它们的预训练语料库包括多个来源,如CommonCrawl、WebText2、Wikipedia、社交媒体对话、Github等。其中GPT-3在175B的混合数据集上进行训练,而PaLM和LLaMA的预训练数据集大小分别为540B和1.0T~1.4T令牌。
库资源
介绍了若干可用于语言模型开发的库。其中最受欢迎的是由Hugging Face维护的Transformers,它使用Transformer结构,提供预训练模型和数据处理工具。Microsoft的DeepSpeed和NVIDIA的Megatron-LM都支持分布式训练和优化技术。Google Brain的JAX提供硬件加速支持,EleutherAI的Colossal-AI则是在JAX的基础上开发了ColossalChat模型。OpenBMB的BMTrain注重简单性和可用性,FastMoE则支持Mixture-of-Experts模型的训练。除了这些库外,现有的深度学习框架(如PyTorch、TensorFlow等)也提供了并行算法的支持。