论文阅读:chain of thought Prompting elicits reasoning in large language models
跟着沐神读论文
视频链接:https://www.bilibili.com/video/BV1t8411e7Ug/?spm_id_from=333.788&vd_source=350cece3ec9a0c2aee50da8ccc315bf4
title:chain of thought Prompting elicits reasoning in large language models
arXiv:2201.11903
利用large language model求解推理任务的几种范式
CoT介绍
预训练大型语言模型(LLMs)被广泛应用于自然语言处理(NLP)的许多子领域,通常被称为具有特定任务示例的优秀少数镜头学习者。值得注意的是,最近的一种通过逐步回答示例来引出复杂的多步推理的技术——思维链(CoT)提示,在算术和符号推理方面取得了最先进的表现,这些困难的系统-2任务不遵循LLMs的标准比例定律。虽然这些成功通常归因于llm的少次学习能力,但我们通过在每个答案之前添加“让我们一步一步地思考”来证明llm是出色的zero-shot推理者。
一、续写任务中的zero—shot

二、manual CoT: chain of thought prompting elicits reasoning in large language models
也就是在输入问题之前,手动设计问题和答案的样例(也就是答案包含CoT的例子)。
我们探索了如何生成一个思维链——一系列中间推理步骤——显著提高大型语言模型执行复杂推理的能力。特别地,我们展示了这种推理能力是如何通过一种称为思维链提示的简单方法在足够大的语言模型中自然出现的,其中提供了一些思维链演示作为提示的示例。在三个大型语言模型上的实验表明,思维链提示提高了在一系列算术、常识和符号推理任务中的表现。经验上的收获可能是惊人的。例如,仅用8个思维链示例提示PaLM 540B就能在GSM8K数学字谜基准测试中达到最先进的精度,甚至超过了带有验证器的微调GPT-3。

论文的阅读
针对LLM在面对推理性的问题时的能力,论文提出了CoT来利用LLM去解决推理任务。
三、Zero-shot CoT 论文1:Large language models are zero-shot reasoners
续写任务中的zero—shot—CoT
预训练大型语言模型(LLMs)被广泛应用于自然语言处理(NLP)的许多子领域,通常被称为具有特定任务示例的优秀少数镜头学习者。值得注意的是,最近的一种通过逐步回答示例来引出复杂的多步推理的技术——思维链(CoT)提示,在算术和符号推理方面取得了最先进的表现,这些困难的系统-2任务不遵循LLMs的标准比例定律。虽然这些成功通常归因于llm的少次学习能力,但我们通过在每个答案之前添加“让我们一步一步地思考”来证明llm是出色的zero-shot推理者。实验结果表明,使用相同的单个提示模板,我们的zero-shot - cot在各种基准推理任务(包括算术(MultiArith, GSM8K, AQUA-RAT, SVAMP),符号推理(最后一个字母,硬币投掷)和其他逻辑推理任务(日期理解,跟踪shuffle对象)上的性能显著优于零-shot LLM,而没有任何手工制作的少量示例。例如,使用大规模InstructGPT模型(text-davinci002)将MultiArith的准确度从17.7%提高到78.7%,将GSM8K的准确度从10.4%提高到40.7%,以及使用另一个现成的大型模型540B参数PaLM进行类似的改进。这一单一提示在非常多样化的推理任务中的通用性暗示了llm尚未开发和未被充分研究的基本零目标能力,这表明简单的提示可以提取高级的、多任务的广泛认知能力。我们希望我们的工作不仅可以作为具有挑战性的推理基准的最小最强零目标基线,而且还强调了在制作微调数据集或少数目标示例之前,仔细探索和分析隐藏在llm内部的大量零目标知识的重要性。


认为:在每个answer之前加上“let’s think step by step ”,就可以立即在2个困难的数学问题数据集中显著涨点。

四、auto-CoT 论文2:automatic chain of thought prompting in large language models
https://arxiv.org/abs/2210.03493
继论文1之后,论文2认为
模型不仅需要let’s think step by step
更需要let’s think not just step by step, but also one by one.
自动生成样例

大型语言模型(LLMs)可以通过生成中间推理步骤执行复杂的推理。为提示演示提供这些步骤称为思维链提示。CoT提示有两种主要模式。一种是利用简单的提示,如“让我们一步一步地思考”,以促进在回答问题之前一步一步地思考。另一种是逐个使用一些手动演示,每个演示都由一个问题和一个推理链组成,从而得到答案。第二个范例的卓越性能取决于手工制作的特定于任务的演示。我们表明,通过利用llm和“让我们一步一步地思考”提示来逐个生成演示的推理链,可以消除这种手工工作,也就是说,让我们不仅一步一步地思考,而且要一个一个地思考。然而,这些生成的链经常会出现错误。为了减轻这种错误的影响,我们发现多样性对于自动构建演示很重要。我们提出了一种自动CoT提示方法:AutoCoT。它对具有多样性的问题进行采样,并生成推理链来构建演示。在GPT-3的10个公共基准推理任务中,Auto-CoT始终匹配或超过需要手动设计演示的CoT范例的性能。代码可从https://github.com/amazon-research/auto-cot获得

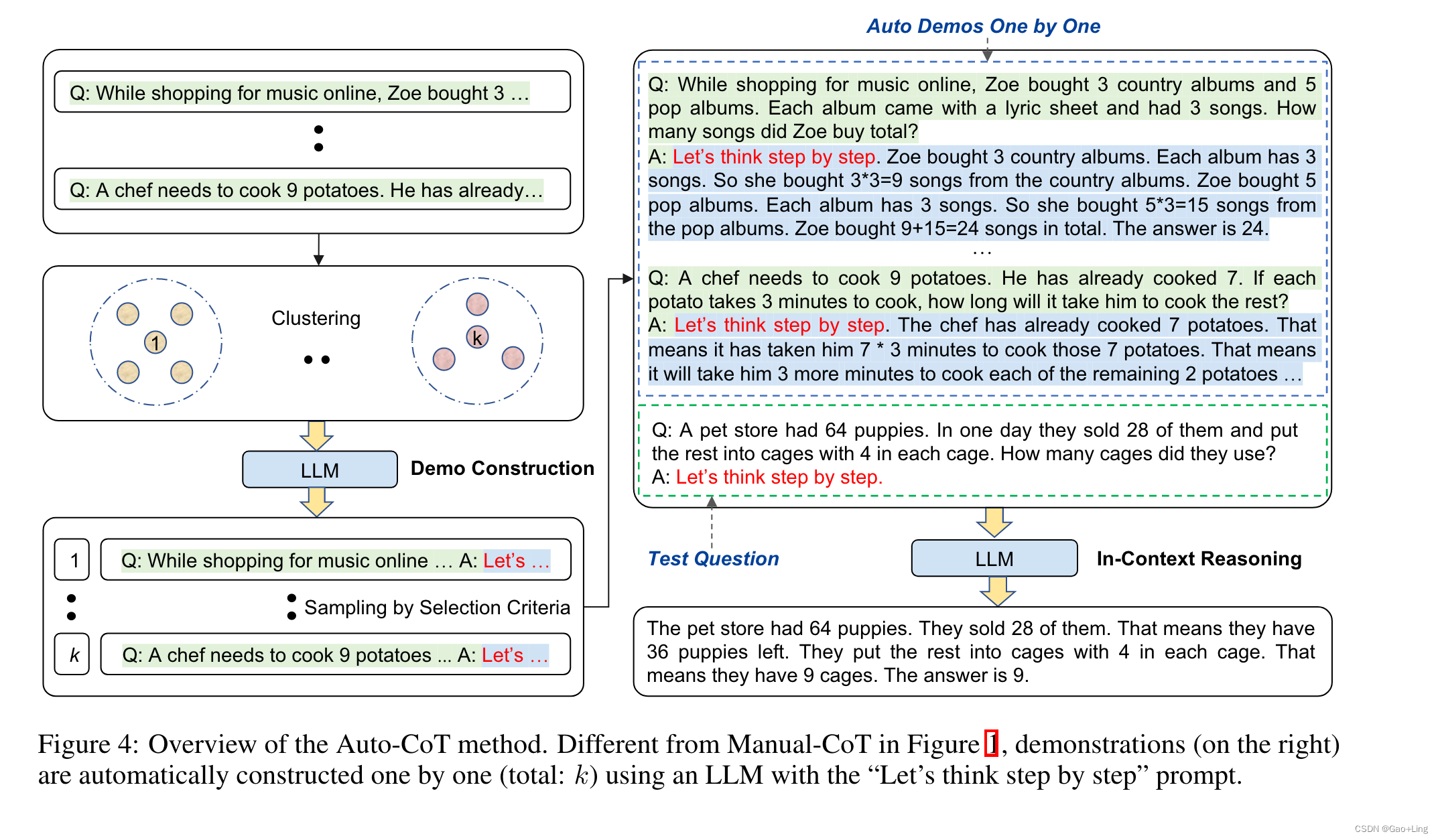
我们提出了一种Auto-CoT方法来自动构造带有问题和推理链的演示。
Auto-CoT包括两个主要阶段:
(i ) 问题聚类 : 将给定数据集的问题划分为几个聚类;
(ii) 示范抽样 : 从每个聚类中选择一个具有代表性的问题,并使用简单的启发式方法用Zero-Shot-CoT生成其推理链。
整个过程如下图所示:
我们在10个基准推理任务上评估Auto-CoT,包括:
(i)算术推理(MultiArith [Roy和Roth, 2015], GSM8K [Cobbe等,2021],AQUA-RAT [Ling等,2017],SVAMP [Patel等,2021]);
(ii)常识推理(CSQA [Talmor等人,2019],StrategyQA [Geva等人,2021]);(iii)符号推理(最后一个字母串联,抛硬币)[Wei等人,2022a]。实验结果表明,在GPT-3中,Auto-CoT的性能始终达到或超过需要手动设计的manual - cot。这表明llm可以通过自动构造演示来执行CoT推理。
4.1 问题聚类
由于基于多样性的聚类可能会减轻相似性造成的误导(第3.3节),我们对给定的一组问题Q进行聚类分析。我们首先通过Sentence-BERT [Reimers和Gurevych, 2019]为Q中的每个问题计算向量表示。对上下文化向量进行平均,以形成固定大小的问题表示。然后,用k-means聚类算法对问题表示进行处理,生成k个问题聚类。对于每个聚类i中的问题,按照到聚类i中心的距离从小到大的顺序,将它们排序成一个列表q(i) = [q(i) 1, q(i) 2,…],这个问题聚类阶段在算法1中总结。

4.2 示范抽样
在第二阶段,我们需要为这些抽样问题生成推理链,然后是满足我们选择标准的样本演示。
更具体地说,我们为每个聚类i (i = 1,……)构建了一个演示demonstration d(i)(一个问题、一个基本原理和一个答案的串联)(concatenation of a question, a rationale, and an answer)。对于聚类i,我们迭代排序列表q(i) = q(i) 1, q(i) 2,…中的问题,直到满足我们的选择条件。换句话说,更接近聚类i中心的问题被更早地考虑。假设正在考虑第j个最接近的问题q(i) j。一个提示输入被表述为:[Q: q(i) j . A: [P]] ,其中[P]是一个单一的提示“让我们一步一步地思考”。使用Zero-Shot-CoT将此形成的输入喂入LLM [Kojima等人,2022],以输出由基本原理r(i) j和提取的答案a(i) j组成的推理链。然后,通过连接问题、原理和答案来构造第i个聚类的候选演示d(i) j:[Q: q(i) j , A: r(i) j ◦ a(i) j ]。
类似于Wei等人[2022a]中手工制作演示的标准,我们的选择标准遵循简单的启发式criteria follow simple heuristics,以鼓励采样更简单的问题和理由:如果选择的演示d(i)有一个问题q(i) j不超过60个tokens,并且有一个不超过5个推理步骤的原因rationale r(i) j,则将其设置为d(i) j
