Pandas特点:
1.它提供了一个简单、高效、带有默认标签(也可以自定义标签)的 DataFrame 对象。
2.能够快速得从不同格式的文件中加载数据(比如 Excel、CSV 、SQL文件),然后将其转换为可处理的对象;
3.能够按数据的行、列标签进行分组,并对分组后的对象执行聚合和转换操作;
4.能够很方便地实现数据归一化操作和缺失值处理;
5.能够很方便地对 DataFrame 的数据列进行增加、修改或者删除的操作;
6.能够处理不同格式的数据集,比如矩阵数据、异构数据表、时间序列等;
提供了多种处理数据集的方式,比如构建子集、切片、过滤、分组以及重新排序等。
Pandas内置数据结构
有两个主要数据结构分别是 Series(一维数据结构)DataFrame(二维数据结构):
Series 是带标签的一维数组,这里的标签可以理解为索引,但这个索引并不局限于整数,它也可以是字符类型,比如 a、b、c 等;
DataFrame 是一种表格型数据结构,它既有行标签,又有列标签。

1.Series
首先要明白索引有行索引(0~N的整数)与列索引(0~N的整数)
创建Series对象

上面的索引没有定义所以从0开始(隐式索引)
下面是显式索引”的方法定义索引标签

dict创建Series对象 (为数据指定索引)

DataFrame(简单的看成一个Excel表格,当创建数组时可以自动生成行索引(index)与列索引(columns))
列
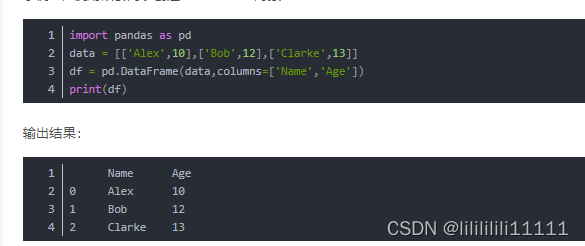
行
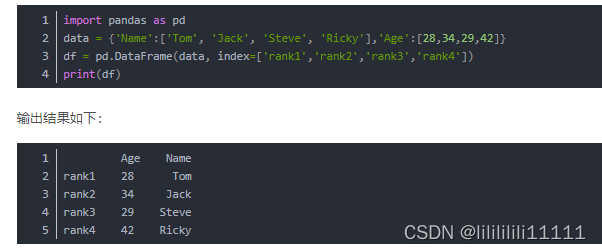
利用索引获取某列数据
element=df_obj['要获取的哪列数据名称'] #df_obj是基于数组创建DataFrame对象的名称可以自己修改
element #输出结果
type(element) #查看返回的结果利用名称获取某列数据
element=df_obj.No2 #No2就是要获取的那列数据名称根据自己需求自己修改
element为DataFrame添加一列数据
df_obj['No4']=['g','h'] #添加的列名称为No4,第一行为g,第二行为h。
df_obj为DataFrame删除一列数据
del df_obj['No3'] #删除No3的一列数据
df_objpandas索引对象的可修改或者不可修改

pandas的重置索引

重置索引时指定填充的填充值

索引操作

DataFrame的索引操作

pandas按索引排序

pandas统计计算和描述
import numpy as np
import pandas as pd
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj)
print('求和')
print(df_obj.sum())
print('求最大值')
print(df_obj.max())
print('按行求最小值')
print(df_obj.min(axis=1))
层次化索引
http://t.csdn.cn/6pGGD(很好的实例文章)
读写数据操作

作业:


程序题
答案:
import numpy as np
arr = np.zeros(5)
print(arr)
答案:
import numpy as np
arr = np.zeros((8,8),dtype=int)
arr[1::2,::2] = 1
arr[::2,1::2] = 1
print(arr)