版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/CSDN_fzs/article/details/81437154
pandas里的数据结构
Series(类似于一维数组---有索引的一维数组)
- 数组与标签
- 可以通过标签选取数据
- 定长的有序字典
DataFrame
- 表格型数据结构
- 行索引、列索引
import numpy as np
import pandas as pd
import sys
from pandas import Series,DataFrame
#Series
obj = Series([4,5,-8,6])
print(obj.values) #获取数组的值
#[ 4 5 -8 6]
print(obj.index) #获取索引的值
#RangeIndex(start=0, stop=4, step=1)
obj2 = Series([4,5,-6,3],index = ['a','b','c','d']) #手动设置索引
print(obj2.index)
#Index(['a', 'b', 'c', 'd'], dtype='object')
print(obj2['a']) #输出索引为'a'的值
#4
obj2['a'] = 10 #修改索引为'a'的值为10
print(obj2[obj2>0]) #输出obj2中>0的值
#a 10
#b 5
#d 3
#dtype: int64
print(obj2**2) #输出整个数组的平方
#a 100
#b 25
#c 36
#d 9
#dtype: int64
print(np.exp(obj2)) #进行运算也会保留索引
#a 22026.465795
#b 148.413159
#c 0.002479
#d 20.085537
#dtype: float64
'g' in obj2 #查询索引是否在一个数组中
#False#DataFrame
data = {'name':['apple','小米','华为','oppo'],
'price':[5888,1588,2499,2199],
'num':[2000,4588,7412,1501]}
frame = DataFrame(data) #列的排序是默认的,索引也是默认的(1、2、3、4......)
frame
frame1 = DataFrame(data,columns=['name','price','num'],index=['one','two','three','four']) #设置列(columns)的顺序,以及索引的值
print(frame1.columns)
print(frame1.index)
frame1
frame1.ix['one'] #输出索引为'one'的值
frame1['hhh'] = np.arange(4.) #添加一个列并赋值
frame1
del frame1['hhh'] #删除列
frame1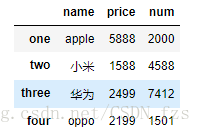
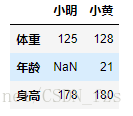
data = {'小明':{'身高':'178','体重':'125'},
'小黄':{'身高':'180','体重':'128','年龄':'21'}}
frame3 = DataFrame(data) #外面的键'小明'、'小黄'作为列,里面的'身高键'、'体重'、'年龄'为行
frame3
frame3.T #转置frame3
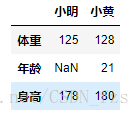
转置后:
frame3.T #转置 python数据分析 pandas