Pandas 库
数据分析三剑客:NumPy Pandas Matplotlib
一、Series
Series是一种类似于一维数组的对象由两部分组成
· index:相关的所居索引标签
· values:一组数据(ndarray类型)
1、创建
Series(data=None,index=None,dtype=None, name=None, copy=False, fastpath=False)
data:一组数据
index:索引(默认为 0,1,2,…)
name:这个对象的名字
注意:传入的索引要和数据对应,多传或少传会报错
1)简单直接创建
#直接传入一个列表即可创建,索引默认
>>> Series([1,2,3,4])
0 1
1 2
2 3
3 4
dtype: int64
#传入数据和索引
>>> Series(data=[1,2,3,4],index=['A','B','C','D'])
A 1
B 2
C 3
D 4
dtype: int64
#一般这样传入比较简单
>>> Series(data=[1,2,3,4],index=list('ABCD'))
2)字典形式创建
一般不这样创建,比较麻烦
>>> Series({'A':1,"B":2,"C":3,"D":4})
A 1
B 2
C 3
D 4
dtype: int642、索引和切片
单个元素的索引与列表索引类似,返回单个索引类型
取多个索引,返回的是一个series类型
1)字符索引取值:
· 使用index中的元素作为索引值
· 使用 .loc[ ] 取值(推荐)
· 注意:字符索引是闭区间 [ start, end ]
2)数字索引取值:
· 使用整数作为索引值
· 使用 .iloc[ ] 取值(推荐)
· 注意:字符索引是左闭右开区间 [ start, end )
>>> s = Series(data=[1,2,3,4],index=list('ABCD'))
>>> s
A 1
B 2
C 3
D 4
dtype: int64
############ 索引 ######################
>>> s[0] #基础索引
1
>>> s.loc["A"] #字符索引
1
>>> s.iloc[0] #数字索引
1
############# 切片 ###################
>>> s[0:2] #基础切片(基础切片不能单个截取)
A 1
B 2
dtype: int64
>>> s.loc["A","C"] # 注意 !!! 这样指要获取最外层的 A 里面的 C 要
想获取 s 里的 A 和 C 这样
>>> s.loc[["A","C"]] #单个截取(字符索引)
A 1
C 3
dtype: int64
>>>> s.loc["A":"C"] #区间截取(字符索引)
A 1
B 2
C 3
dtype: int64
>>>> s.iloc[[0,3]] #单个截取(数字索引)
A 1
D 4
dtype: int64
>>> s.iloc[0:3] #区间截取(数字索引)
A 1
B 2
C 3
dtype: int643、Series的属性和方法
属性
1)形状 shape
2)个数 size
方法
1)查看前面 head()
s.head(n=5)
2)查看后面 tail()
s.head(n=5)
'''
n:取几个,默认为5个
'''
>>> s
A 1
B 2
C 3
D 4
dtype: int64
>>> s.head(2)
A 1
B 2
dtype: int64
>>> s.tail(2)
C 3
D 4
dtype: int643)求和
s.sum(axis=None,skipna=None,level=None,numeric_only=None, min_count=0, **kwargs)
'''
对于Series中的求和会将None会被自动转化为NAN,而且在计算时会自动将NAN转化为0
多维数组中的None在求和时会报错
'''
# Series 求和
>>> s2 = Series([1,2,3,None,np.NAN])
>>> s2
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
>>> s2.sum()
6.0
# ndarray 求和
>>> nd = np.array([1,2,3,None,np.NAN])
>>> nd
array([1, 2, 3, None, nan], dtype=object)
>>> np.sum()
报错~~4)isnull()/ notnull()
isnull()
功能:检测None / NaN,为空返回Ture,不为空返回False
>>> s2
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
>>> s2.isnull()
0 False
1 False
2 False
3 True
4 True
dtype: boolnotnull()
功能:检测None / NaN,为空返回False,不为空返回Ture
>>> s2
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
>>> s2.notnull()
0 True
1 True
2 True
3 False
4 False
dtype: bool5)name属性
功能:来区分两个相同的数组
注意:在创建的时候设置了才有name属性,如果没有设置,则返回为空
6)unique()去重
>>> s1 = Series(['tom','lili','hehe','tom','lili'])
>>> s1
0 tom
1 lili
2 hehe
3 tom
4 lili
dtype: object
>>> s1.unique()
array(['tom', 'lili', 'hehe'], dtype=object)4、Series的运算
1)Series的加减乘除
广播机制:给Series对象进行运算
>>> s
A 1
B 2
C 3
D 4
dtype: int64
#注意返回之后不会改变原数据的值
>>> s+1
A 2
B 3
C 4
D 5
dtype: int642)Series的运算
s.add(other,fill_value=None, axis=0)
'''
other:另一个Series
fill_value:相加是不对称的地方的NAN以这个值来填充
'''
>>> s1 = Series(data=np.random.randint(1,5,size=5),index=list('abcde'))
>>> s1
a 1
b 1
c 3
d 1
e 2
dtype: int32
>>> s2 = Series(data=np.random.randint(1,5,size=3),index=list('abc'))
>>> s2
a 2
b 3
c 1
dtype: int32
>>> s1.add(s2) #没有fill_value=0
a 3.0
b 4.0
c 4.0
d NaN
e NaN
dtype: float64
>>> s1.add(s2,fill_value=0) #有fill_value=0
a 3.0
b 4.0
c 4.0
d 1.0
e 2.0
dtype: float64
二、DataFrame
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(多个series共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
行索引:index
列索引:columns
值:values(numpy的二维数组)
1、创建DataFrame
DataFrame(data=None, index=None,columns=None, dtype=None, copy=False)
1)一般创建方法
'''
data:数据
index:行索引(默认为 0,1,2....)
columns:列索引(默认为 0,1,2....)
注意:行索引和列索引要和所创建的数据维度对应!否则报错
'''
# 成绩表
nd = np.random.randint(0,150,size=(5,4))
nd = array([[125, 19, 45, 25],
[ 62, 128, 139, 2],
[ 99, 142, 134, 98],
[ 3, 114, 142, 102],
[ 47, 110, 70, 112]])
index=['张三','李四','王老五','赵六','田七']
columns = ['python','java','c','math']
df = DataFrame(data=nd,index=index,columns=columns)
df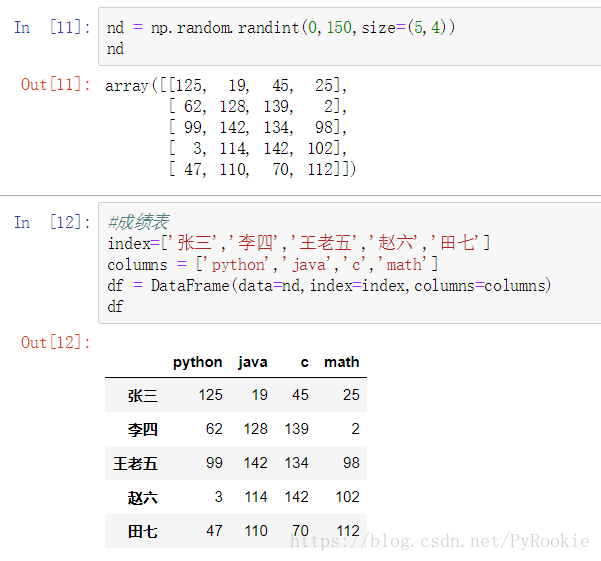
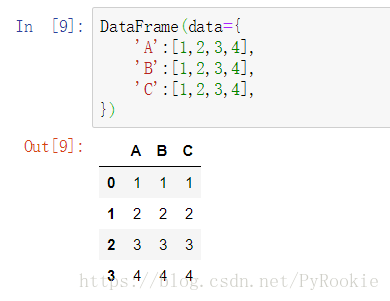
2)字典创建方法
话不多说,上图
3)通过导入csv文件创建
文件内容:

DataFrame创建:
pd.read_csv(“文件路径“)
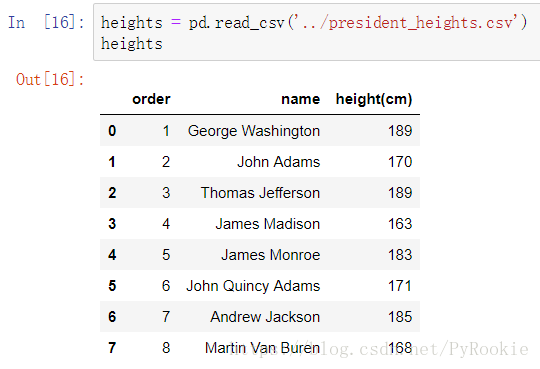
文件导入后会默认添加行索引。
疑问:csv文件导入到DataFrame后第一行是否一定是列索引?
2、DataFrame的属性
以上面创建的成绩表为 s 其中的数值不一样
1)values 值
返回值是一个多维数组
s.values
array([[100, 102, 50, 85],
[ 69, 136, 71, 100],
[129, 90, 18, 121],
[149, 87, 143, 129],
[ 40, 80, 129, 61]])2)columns 列索引
s.index
Index(['张三', '李四', '王老五', '赵六', '田七'], dtype='object')3)index 行索引
s.columns
Index(['python', 'java', 'c', 'math'], dtype='object')4)shape 形状
行叫样本
列叫特征
s.shape
(5, 4) # 5 个样本,4 个特征5)query 查询
>>> df1 = DataFrame({'name':['tom','lucy','tom','peppy','lucy'],'age':[12,13,12,11,15]})
>>> df1
name age
0 tom 12
1 lucy 13
2 tom 12
3 peppy 11
4 lucy 15
>>> df1.query('name=="lucy"') #查询name是”lucy“的样本
name age
1 lucy 13
4 lucy 15
>>> df1.query('name=="lucy"&age>14') #查询name是lucy同时age大于 14的样本
name age
4 lucy 153-1、DataFrame的单层索引
以上面创建的成绩表为 s 其中的数值不一样
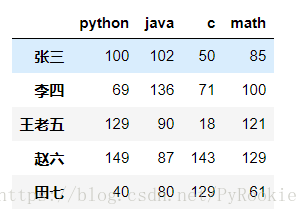
1)对列进行索引与切片
- 通过类似字典的方式
- 通过属性的方式
'''
返回值:一个Series对象
'''
s['python'] #通过字典的方式
张三 100
李四 69
王老五 129
赵六 149
田七 40
Name: python, dtype: int32
s.python #通过属性的方式
张三 100
李四 69
王老五 129
赵六 149
田七 40
Name: python, dtype: int322)对行进行索引
- 使用.loc[ ] 加index来进行行索引
- 使用.iloc[ ] 加整数来进行行索引
'''
返回值:一个Series对象
'''
s.loc['张三'] #使用.loc[] 索引
python 100
java 102
c 50
math 85
Name: 张三, dtype: int32
s.iloc[1] #使用.iloc[] 索引
python 69
java 136
c 71
math 100
Name: 李四, dtype: int323)对元素进行索引
- 使用列索引,再进行元素索引
- 使用行索引,再进行元素索引
- 使用整数数组形式的索引
- 取 任意顺序 的 任意元素
#使用列索引,再取元素值
s['python']
s['python'].loc['张三']
s['python'].iloc[0]
100
#使用行索引,再取元素值
s.loc['张三']
s.loc['张三'].loc['python']
s.loc['张三'].iloc[0]
100
#使用整数数组的索引形式取元素值
s.loc['张三','python'] #先行后列
100
#使用整数数组的索引形式取 任意顺序 的 任意元素
s.loc[['张三','李四'],'python'] #将前一部分视为行,后一部分视为列
张三 100
李四 69
Name: python, dtype: int32
4)对元素进行切片
##行列连续切片
s.loc['张三':'李四','python':"c"]
python java c
张三 100 102 50
李四 69 136 71
##行列间隔间断切片
s.loc[['张三','李四','李四'],['python',"c","c"]] #将前一部分视为行,后一部分视为列
python c c
张三 100 50 50
李四 69 71 71
李四 69 71 71
3-2、多层索引数据
1. 创建多层行/列索引
一般情况下
多层行索引的index,columns :indexes,columns
多行列索引的index,columns :features,samples
其他的都基本相同
1)隐式构造(构造Series的多层索引)
最简单的方法是给DataFrame构造函数的index参数传递两个或更多的数组
创建一个Series对象的多层索引
'''
这里的index里的每个元素里的个数必须相同
'''
>>> data = np.random.randint(0,100,size=4)
>>> s1 = Series(data,index=[['期中','期中','期末','期末'],['语文','数学','语文',' 数学']])
>>> s1
期中 语文 68
数学 73
期末 语文 96
数学 36
dtype: int32在多层索引的Series中取值
>>> s1.loc['期中','数学']
732)显式构造(直接创建多层索引)
(1)使用数组
pd.MultiIndex.from_arrays(arrays,sortorder=None, names=None)
功能:将数组转化为多层索引
'''
这里的index里的每个元素里的个数必须相同
'''
>>> indexes = pd.MultiIndex.from_arrays([['期中','期中','期中','期末','期末','期末'],['语','数','外','语','数','外']])
>>> columns = ['tom','jack','rose']
>>> data = np.random.randint(0,150,size=(6,3))
>>> DataFrame(data=data,index=indexes,columns=columns)
tom jack rose
期中 语 72 23 108
数 45 21 72
外 124 70 108
期末 语 13 140 45
数 142 96 99
外 147 47 38(2)使用元祖
pd.MultiIndex.from_tuples(tuples,sortorder=None,names=None)
功能:将元组转化为多层索引
>>> indexes = pd.MultiIndex.from_tuples([('期中','语'),('期中','数'),('期中','外'),('期末','语'),('期末','数'),('期末','外')])
>>> columns = ['tom','jack','rose']
>>> data = np.random.randint(0,150,size=(6,3))
>>> DataFrame(data=data,index=indexes,columns=columns)
tom jack rose
期中 语 55 79 47
数 126 128 35
外 37 79 85
期末 语 27 19 0
数 77 34 9
外 6 87 32(3)使用product(乘积)
pd.MultiIndex.from_product(iterables,sortorder=None,names=None)
功能:从多个迭代的笛卡尔积中创建一个多索引
(将传入的多个列表以乘积的形式作索引)
'''
data中的size为(indexes乘积,columns)
'''
>>> indexes = pd.MultiIndex.from_product([['期中','期末'],['语','数','外']])
>>> columns = ['张三','李四']
>>> data = np.random.randint(0,150,size=(6,2))
>>> DataFrame(data=data,index=indexes,columns=columns)
张三 李四
期中 语 82 103
数 45 2
外 18 15
期末 语 140 66
数 52 41
外 50 1372. 多层索引对象的索引与切片操作
1)Series的索引与切片
(1)索引
常规:
'''
依旧使用Series.loc["字符索引"]
最外层可以取,内层不能使用.loc[]
依旧使用Series.iloc["字符索引"]
数字索引可以在多层索引中使用
'''
>>> s1 = Series([100,90,80,70,60,50],index=pd.MultiIndex.from_product([['期中','期末'],['语','数','外']]))
>>> s1
期中 语 100
数 90
外 80
期末 语 70
数 60
外 50
dtype: int64注意:
>>> s1.loc['语':'外']
Series([], dtype: int64)
>>> s1.loc[['期中','期末']]
期中 语 100
数 90
外 80
期末 语 70
数 60
外 50
dtype: int642)DataFrame的索引与切片
(1)索引
常规:可以直接使用列名称来进行 列索引 以及 使用loc()对行索引
'''
依旧使用.loc["字符索引"]
最外层可以取,内层不能直接使用.loc[]
依旧使用.iloc["字符索引"]
数字索引可以在多层索引中使用
'''
>>> indexes = pd.MultiIndex.from_product([['期中','期末'],['语','数','外']])
>>> columns = pd.MultiIndex.from_product([['一班','二班'],['01','02','03']])
>>> data = np.random.randint(0,150,size=(6,6))
>>> df1 = DataFrame(data,index=indexes,columns=columns)
>>> df1
一班 二班
1 2 3 1 2 3
期中 语 81 21 60 64 148 131
数 26 138 101 129 119 103
外 47 75 141 26 146 33
期末 语 18 55 131 149 118 126
数 124 127 61 16 70 110
外 10 61 141 145 130 128普通用法
>>> df1['一班'] #对外层的索引获取到的是DataFrame
1 2 3
期中 语 81 21 60
数 26 138 101
外 47 75 141
期末 语 18 55 131
数 124 127 61
外 10 61 141
>>> df1['一班']['01'] #第二层索引,获取到的是Series对象
期中 语 81
数 26
外 47
期末 语 18
数 124
外 10
Name: 01, dtype: int32
iloc[ ] 索引/切片(推荐使用)
>>> df1.iloc[0] #使用iloc[数字索引]获取,和单层相同
一班 01 81
02 21
03 60
二班 01 64
02 148
03 131
Name: (期中, 语), dtype: int32
>>> df1.iloc[:,0:2] #使用iloc,还是类似于二维数组的索引(推荐使用)
一班
01 02
期中 语 81 21
数 26 138
外 47 75
期末 语 18 55
数 124 127
外 10 61
.loc[ ]索引/切片(坑深,误入,去上面)
>>> df1.loc["期中",'一班'].loc["语":'数','01':'02'] #比较复杂。
01 02
语 81 21
数 26 1383. 索引的堆(stack)
对DataFrame的行和列进行转换,转换后的数据不改变,标题层级不会改变。
先指定一个(DataFrame) df
'''
level:堆的层级由内向外分别是 0,1,2....
默认为 -1 最内层索引转换为另一个索引
'''
>>> data=np.random.randint(0,150,size=(2,8))
>>> index=["rose","jack"]
>>> columns=pd.MultiIndex.from_product([["期中","期末"],["一模","二模"],["语文"," 英语"]])
>>> df = DataFrame(data,index,columns)
>>> df
期中 期末
一模 二模 一模 二模
语文 英语 语文 英语 语文 英语 语文 英语
rose 130 100 112 10 3 130 120 136
jack 139 128 57 94 2 26 144 1201) df.stack(level=-1, dropna=True)
功能:将列堆转到行堆
官方翻译:将指定的级别从列堆到索引堆。
>>> df.stack() #默认将最内层的列索引转换为行行索引
期中 期末
一模 二模 一模 二模
rose 英语 100 10 130 136
语文 130 112 3 120
jack 英语 128 94 26 120
语文 139 57 2 144>>> df.stack(1) #将从内向外的第二个列转换为行索引
期中 期末
英语 语文 英语 语文
rose 一模 100 130 130 3
二模 10 112 136 120
jack 一模 128 139 26 2
二模 94 57 120 144
>>>
>>> df.stack([0,1]) #还可以传入列表,将指定的行索引一起转换
英语 语文
rose 期中 一模 100 130
二模 10 112
期末 一模 130 3
二模 136 120
jack 期中 一模 128 139
二模 94 57
期末 一模 26 2
二模 120 144
>>>2) df.unstack(level=-1, dropna=True)
与 df.stack 的用法一模一样,区别是将行索引转换为列索引。
转换后的数据不变
4. 聚合操作(sum,max,min…)
- ndarray是对整个数据的操作,df默认是对列操作
- 通过指定axis,可以对行操作
ndrray的聚合操作:
>>> data = np.random.randint(0,5,size=(5,5))
>>> data
array([[2, 3, 3, 2, 0],
[3, 0, 4, 3, 2],
[3, 4, 4, 0, 2],
[4, 3, 0, 4, 1],
[1, 0, 4, 0, 0]])
>>> data.sum() #求和
52
>>> data.mean() #求平均值
2.08
>>> data.min() #求最小值
0
>>> data.max() #求最大值
4DataFrame的聚合操作
'''
axis:指定 行/列 (默认为 None(0) 列, 1 行)
'''
>>> data = np.random.randint(0,5,size=(5,5))
>>> columns = list('ABCDE')
>>> df = DataFrame(data=data,columns=columns)
>>> df
A B C D E
0 4 2 2 1 0
1 3 0 2 3 0
2 4 3 3 3 4
3 4 0 4 0 4
4 4 2 2 2 1
>>> df.sum() #默认对列求和
A 19
B 7
C 13
D 9
E 9
dtype: int64
>>> df.sum(axis=1) #对行求和
0 9
1 8
2 17
3 12
4 11
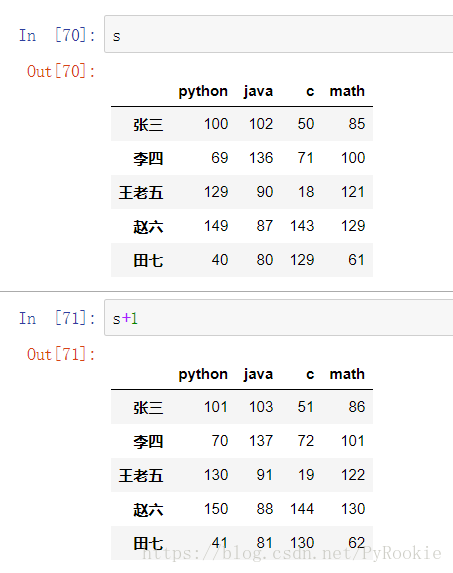
dtype: int644、DataFrame的运算
1)DataFrame与数字的加减乘除
广播机制:给DataFrame对象进行的每个元素进行运算
2)DataFrame之间的运算
| Python Operator | Pandas Method(s) |
|---|---|
+ |
add() |
- |
sub(), subtract() |
* |
mul(), multiply() |
/ |
truediv(), div(), divide() |
// |
floordiv() |
% |
mod() |
** |
pow() |
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
s.add(other,axis=’columns’, fill_value=None)
'''
other:于s相加的表格
axis:以哪个索引为基础进行运算(默认为columns,列索引,index,行索引)
fill_value:用来替代NaN
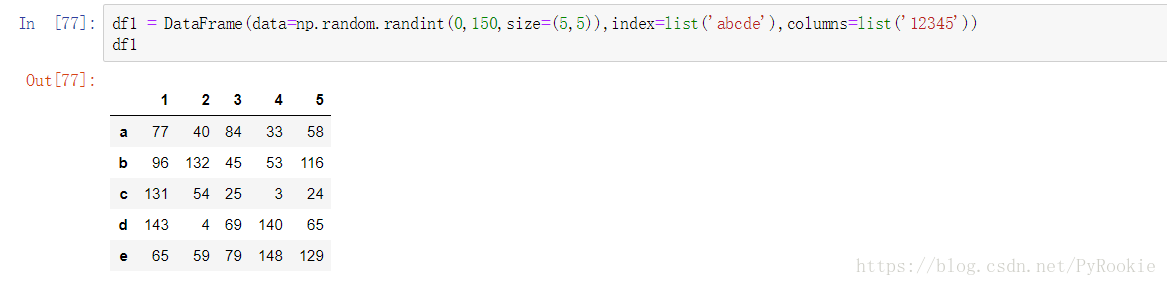
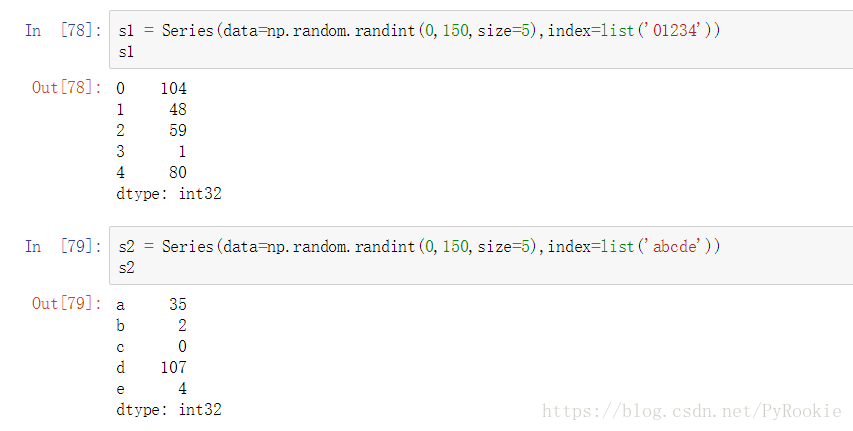
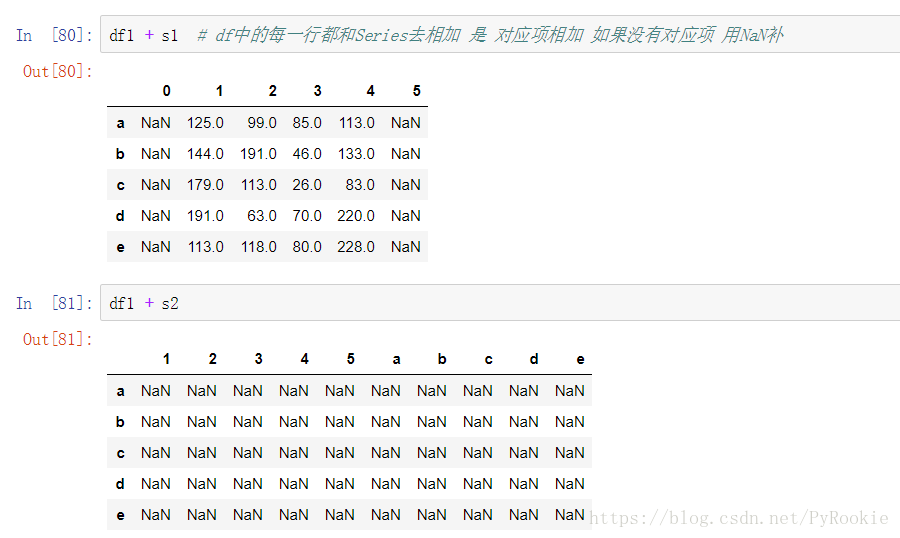
'''3)Series与DataFrame之间的运算
使用Python操作符:以行为单位操作(参数必须是行),对所有行都有效。(类似于numpy中二维数组与一维数组的运算,但可能出现NaN)
使用pandas操作函数:
axis=0:以列为单位操作(参数必须是列),对所有列都有效。 axis=1:以行为单位操作(参数必须是行),对所有行都有效。
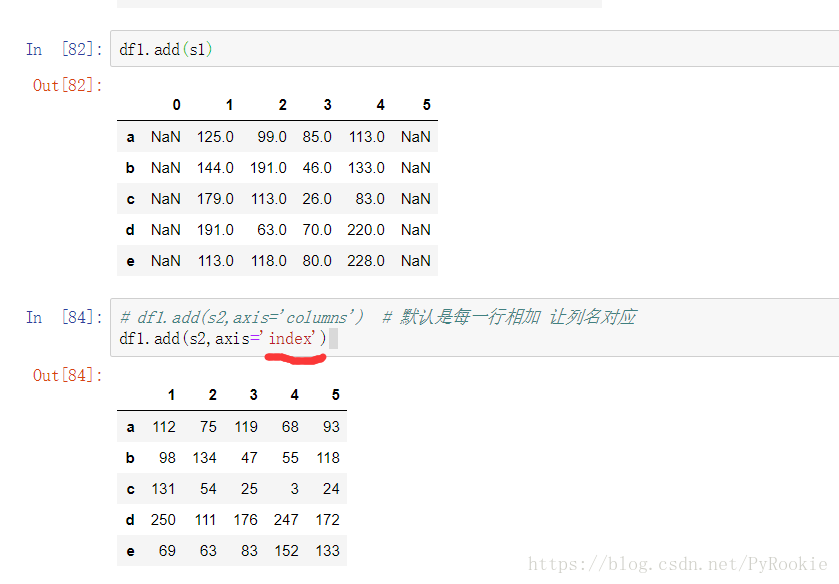
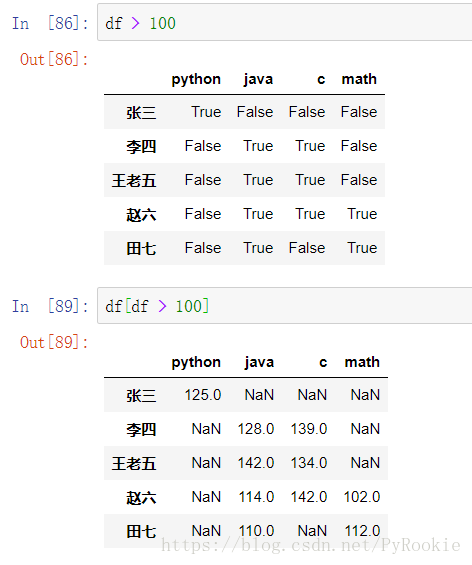
5、DataFrame的值处理
1)值的筛选/过滤
2)isnull()
功能:
用来判断元素的值,是nan就是True 不是就是False
一般与any()两用,用来判断行/列里的值是否有空值
df.isnull().any(axis=1) #来判断 列 中是否有nan/None,True代表有,False则代表没有
a True
b True
c False
d False
e True
dtype: bool
df.isnull().any(axis=0) #来判断 行 中是否有nan/None,True代表有,False则代表没有
0 True
1 True
2 False
3 True
4 False
dtype: bool
3)notnull()
是nan就是False不是就是Ture(和上面的相反)
4)dropna()删除空值
df.dropna(axis=0, how=’any’)
功能:删除nan
'''
how:['any', 'all']
默认为"any" :删除所有包含nan的行或列
'all' :删除行或列中所有元素都是nan的 行或列
axis:轴线 默认为 0 横 , 1 竖
'''
5)fillna()填充空值
df.fillna(value=None,method=None,axis=None, inplace=False, limit=None,inplace=False, **kwargs)
功能:对数据中的nan进行填充
'''
value:可以指定填充的值
method:可以从表里找一些值来填充(没有找到的还是NaN)
{'backfill', 'bfill', 'pad', 'ffill', None}
None:使用value参数填充
bfill:将后面的值填充进去
ffill:将前面的值填充进去
backfill:---
pad:
axis:填充是沿着那个轴线,默认是None,以列来找。1,以行来找
limit:限制连续填充nan的个数
inplace:是否替换原数据表
'''6、pandas的拼接操作
pandas的拼接分为两种:
- 级联:pd.concat, pd.append (没有重复数据)
- 合并:pd.merge, pd.join (有重复数据)
1) 使用pd.concat()级联
pd.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, names=None, sort=None)
功能:拼接两个DataFrame数据
返回值:返回一个新的DataFrame对象
'''
objs:要级联的对象
axis:以哪个轴拼接 默认为0,以纵向拼接
join:控制拼接的方式
{'inner', 'outer'}, default 'outer'
'inner'
join_axes:可以设定按照哪些索引对象拼接
ignore_index:忽略原来的索引 重新分配索 默认False,不忽略原来的索引
sort:拼接后对索引排序
'''匹配拼接
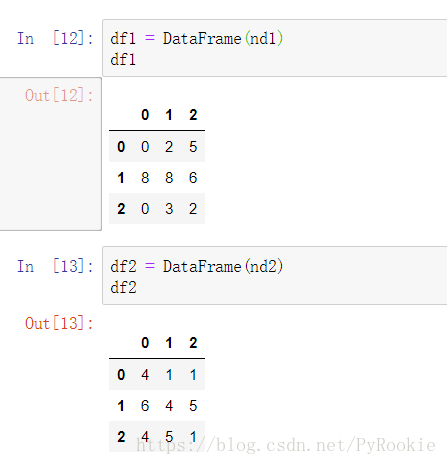
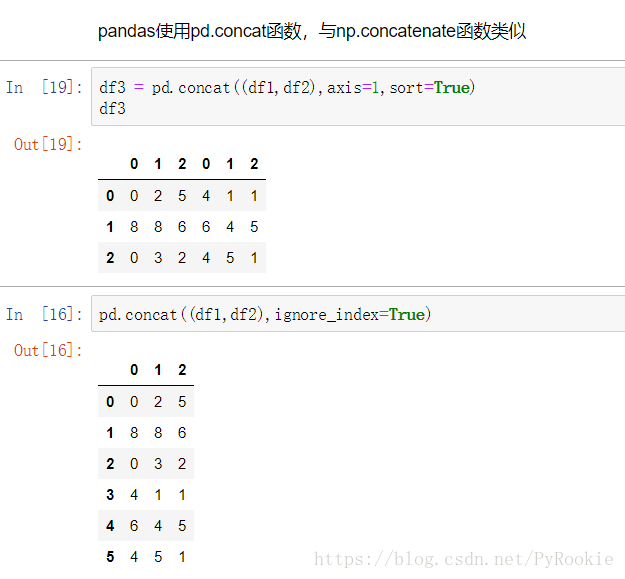
不匹配拼接
形状不匹配拼接时会发出警告,此时只需在函数cancat()中加入参数 sort=Ture 就OK
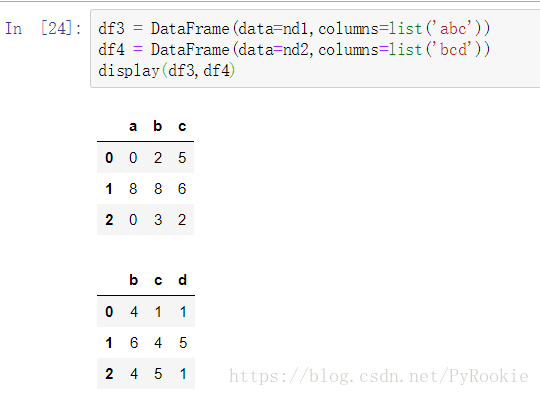
1、默认将对不上的列补NaN填充
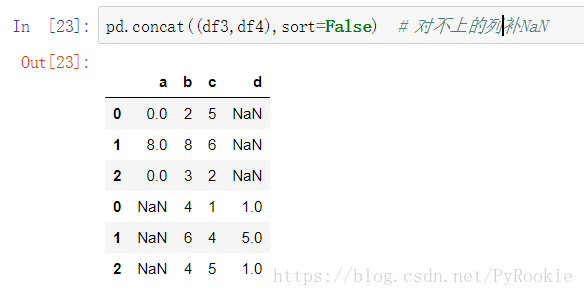
2、axis 拼接方向 (0 纵向, 1 横向)
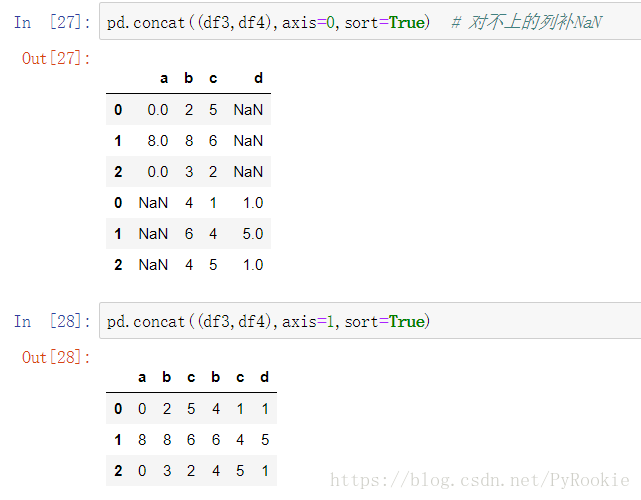
3、join 拼接方式 (outer 外联, inner 内联)
4、join_axes 按指定的拼接,这里的参数填索引对象
1)用已有的列进行拼接
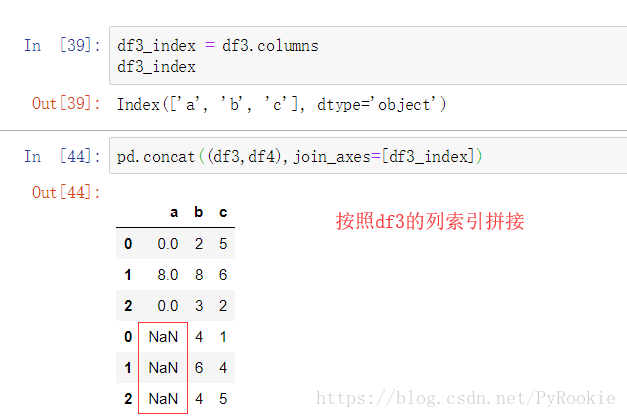
2)指定列进行拼接
需要使用pd.index([‘指定的索引1’,’指定的索引2’…])生成索引对象

2) 使用append()函数在下面拼接
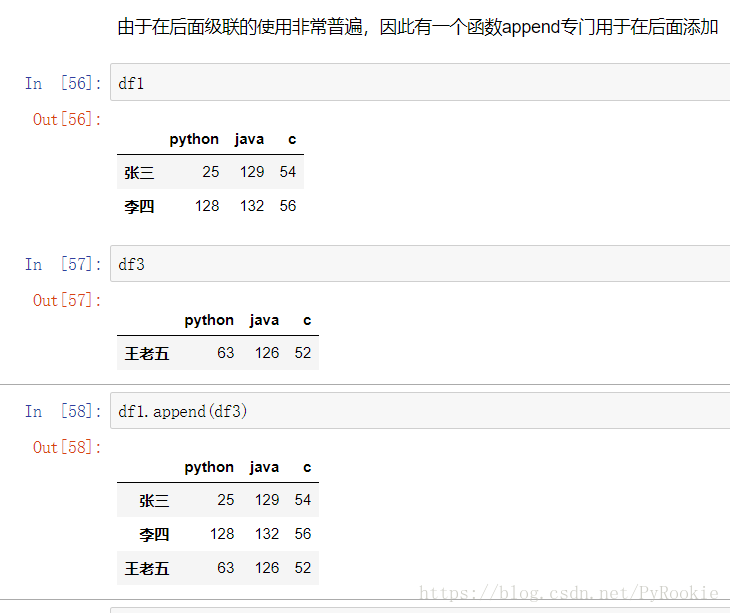
7、使用pd.merge()合并
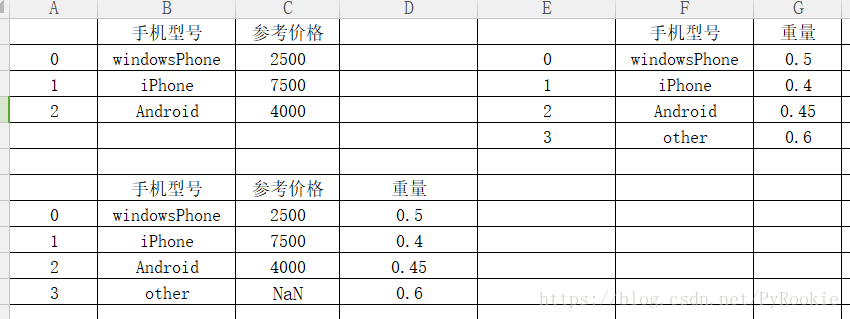
功能:merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
pd.merge(left,right,how=’inner’,on=None,left_on=None,right_on=None,left_index=False,right_index=False, sort=False,suffixes=(‘_x’,’_y’), copy=True,indicator=False, validate=None)
'''
left, right:要合并的对象
how:怎么融合数据
{'left', 'right', 'outer', 'inner'}, default 'inner'
'inner':两个都有的都对应上才会进行拼接
'outer':对所有行/列都会进行合并
'left':以左边的为准
'right':以右边的为准
on:指定用哪一行或多行来拼接
left_on:左边根据那一列合并
right_on:右边根据那一列合并
left_index:
right_index:
sort:
suffixes:对两个相同的列进行区分
indicator:
validate:
'''读取exc文件
pd.read_excel(‘文件路径’,sheet_name=表名)
1)一对一合并
主要研究 how 参数的变化


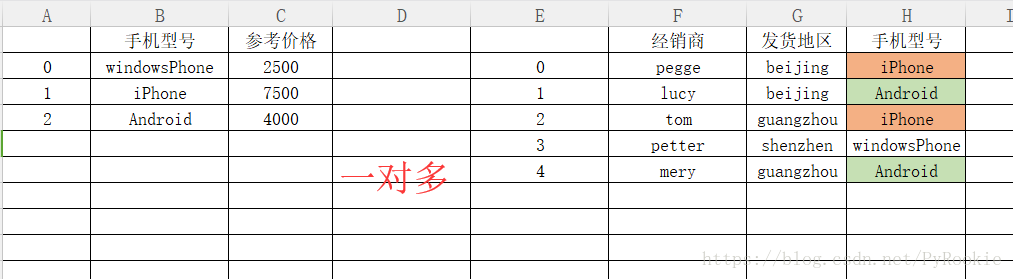
2)多对一合并
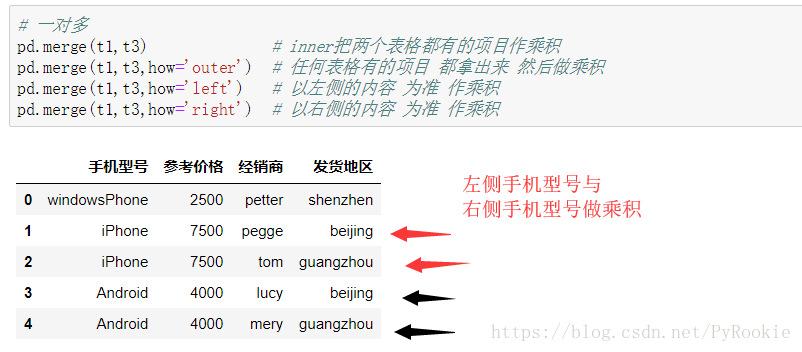
3)多对多合并
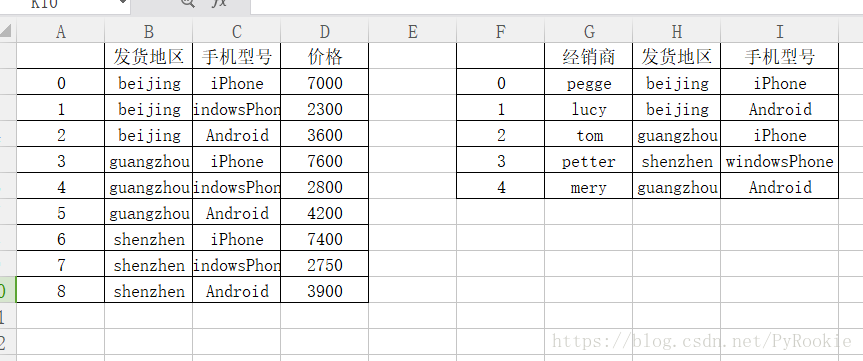
一般在实际业务中会指定列来拼接
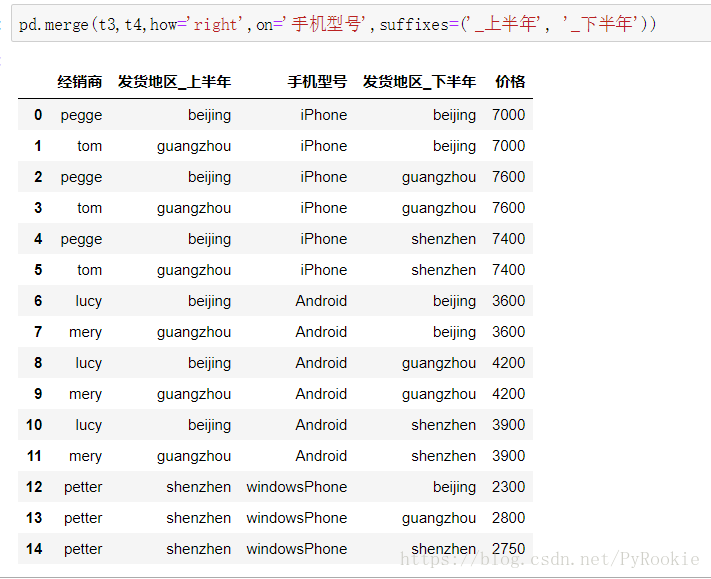
suffixes 用来区分两表中同名的列
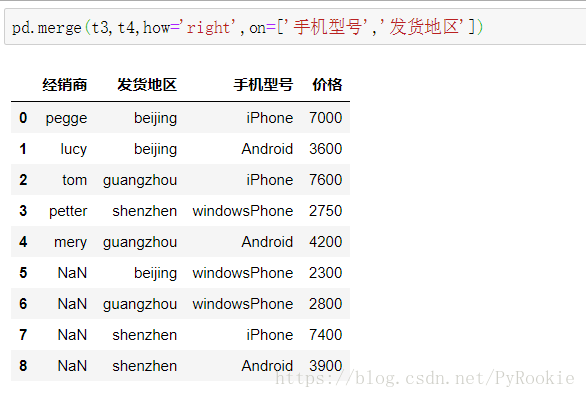
on 用来同时满足两列相同的情况
三、pandas数据处理
1、删除重复元素
重复样本
在实际操作中有的样本(行)的特征(列)完全一样这就是重复样本,在有些情况下需要对这些样本进行处理
样本数据(其中就有重复样本)
>>> data = [[100,100,100],[90,90,88],[100,100,100],[90,90,87],[100,100,100]]
>>> columns = ['python','c','java']
>>> index = list('ABCDE')
>>> df = DataFrame(data=data,index=index,columns=columns)
>>> df
python c java
A 100 100 100
B 90 90 88
C 100 100 100
D 90 90 87
E 100 100 1001)df.duplicated(subset=None,keep=’first’)
'''
keep: {'first', 'last', False}
默认为 first 不算第一个
last 不算最后一个
False 全部都算
'''>>> df.duplicated() #默认keep=“first”
A False --第一个不算重复的(last同理)
B False
C True --重复返回True
D False --不重复返回False
E True
dtype: bool>>> df.duplicated(keep=False)
A True --第一个也算重复样本
B False
C True
D False
E True --最后一个也算重复样本
dtype: bool2)df.drop_duplicates(subset=None,keep=’first’,inplace=False)
功能:删除重复的样本
'''
keep: {'first', 'last', False}
默认为 first 不算第一个
last 不算最后一个
False 全部都算
inplace:修改缓存中的DataFrame(原来的变量也会被改变)
'''keep为默认值
>>> df.drop_duplicates() #默认为“first”
python c java
A 100 100 100 --第一个重复样本被保留(last同理)
B 90 90 88
D 90 90 87keep=False
>>> df.drop_duplicates(keep=False) #所有的重复元素都被删除
python c java
B 90 90 88
D 90 90 872. 映射(替换)
映射的含义:创建一个对应关系列表,把values元素和一个特定的标签或者字符串绑定(类似于字典)
1) replace()函数:替换元素
s1.replace(to_replace=None,value=None,inplace=False,limit=None,regex=False,method=’pad’)
'''
to_replace:要替换的值(旧值)
[字符串,列表,字典]
字符串:需要value也传替换成的参数
列表:需要value也传替换成的参数(需要一一对应)
字典:to_replace={100:'满分','没有的':'也不会报错'} 可以传入没有的值,用来过滤可能会出现的值
value:替换成的值(新值)
limit:限制替换的个数
method:当to_replace和value不传参时,将数据中的NaN以前面的或后面的替换
当to_replace传参,value不传参时,会将to_replace指定的值用前面的或后面的值替换
{'pad', 'ffill', 'bfill', `None`}
pad,ffill:从后面补齐
bfill:从前面补齐
'''(1)Series替换
样本数据
>>> s1 = Series(data = [100,'peppa',np.nan,'beijing'])
>>> s1
0 100
1 peppa
2 NaN
3 beijing
dtype: object单值替换
>>> s1.replace(to_replace='beijing',value='西安')
0 100
1 peppa
2 NaN
3 西安 #将样本中的beijing替换为西安
dtype: object列表替换
两个列表里的值数量需要统一
>>> s1.replace(to_replace=[100,np.nan],value=['满分','缺考'])
0 满分
1 peppa
2 缺考
3 beijing
dtype: object字典替换
可以放入很多没有的值 没有的值就不会替换了 但是也不会报错
应用:可以用来做过滤器
>>> # 字典替换(推荐) 支持单值,多值替换
>>> s1.replace(to_replace={100:'满分',np.nan:'缺考','beijing':'西安','没有的':'也不会报错'})
0 满分
1 peppa
2 缺考
3 西安
dtype: object(2)DataFrame替换操作
样本数据 数据下载
df = pd.read_excel("./data/data.xls",sheet_name=0)
df
0 1 2 3 4
A 甲 NaN NaN NaN Beijing
B 乙 69.0 142.0 29 Beijing
C 丙 111.0 7.0 2 Beijing
D 丁 139.0 19.0 125 shanghai
E 戊 12.0 66.0 Beijing shanghai单值替换
指定替换表中的某些值
df.replace(to_replace='Beijing',value='西安') #将某个值全部替换成新值
0 1 2 3 4
A 甲 NaN NaN NaN 西安
B 乙 69.0 142.0 29 西安
C 丙 111.0 7.0 2 西安
D 丁 139.0 19.0 125 shanghai
E 戊 12.0 66.0 西安 shanghai列替换
指定替换表中的某列中的某些值
(若想替换多列中的值,多写两遍吧)
df.replace(to_replace={4:'Beijing'},value='西安') #设置to_replace中的参数
0 1 2 3 4
A 甲 NaN NaN NaN 西安
B 乙 69.0 142.0 29 西安
C 丙 111.0 7.0 2 西安
D 丁 139.0 19.0 125 shanghai
E 戊 12.0 66.0 Beijing shanghai列表替换
列表以可以传不存在的值用来过滤
df.replace(to_replace=['甲','乙',np.nan],value=[1,2,'空值']) #两个参数中的列表中元素数量需要一致
0 1 2 3 4
A 1 空值 空值 空值 Beijing
B 2 69 142 29 Beijing
C 丙 111 7 2 Beijing
D 丁 139 19 125 shanghai
E 戊 12 66 Beijing shanghai字典替换(推荐)
可以用来用作过滤器
df.replace(to_replace={'甲':1,'乙':2,np.nan:'空值','Beijing':'西安','不存在的也可以放这里':'不会报错'})
0 1 2 3 4
A 1 空值 空值 空值 西安
B 2 69 142 29 西安
C 丙 111 7 2 西安
D 丁 139 19 125 shanghai
E 戊 12 66 西安 shanghai2) map()函数:映射元素
3) rename()函数:替换索引名
3. 使用聚合操作对数据异常值检测和过滤
4. 排序
5.随机抽样
6.数据分类处理
文中所用到的数据(可下载)
可点击下载