https://blog.csdn.net/chenpe32cp/article/details/75452592
1)merge
left = pd.DataFrame({'key': ['foo', 'bar'], 'lval': [1, 2]})
right = pd.DataFrame({'key': ['foo', 'bar'], 'rval': [4, 5]})
pd.merge(left, right, on='key')2)zip
>>> list1 = ['a', 'b', 'c', 'd']
>>> list2 = ['apple', 'boy', 'cat', 'dog']
>>> for x, y in zip(list1, list2):
print(x, 'is', y)
# 输出
a is apple
b is boy
c is cat
d is dog
*是zip逆操作:
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
....: 'foo', 'foo', 'qux', 'qux'],
....: ['one', 'two', 'one', 'two',
....: 'one', 'two', 'one', 'two']]))
....:
输出:
('bar', 'one'),
('bar', 'two'),
('baz', 'one'),
('baz', 'two'),
('foo', 'one'),
('foo', 'two'),
('qux', 'one'),
('qux', 'two')]
zip是把可迭代对象按相同索引合并成新的元组,*就是将元组按索引再一一对应还原回去。
**原理**
Python3中的zip函数可以把两个或者两个以上的迭代器封装成生成器,这种zip生成器会从每个迭代器中获取该迭代器的下一个值,然后把这些值组装成元组(tuple)。这样,zip函数就实现了平行地遍历多个迭代器。
BabyDataSet = list(zip(names,births))
**注意**
如果输入的迭代器长度不同,那么,只要有一个迭代器遍历完,zip就不再产生元组了,zip会提前终止,这可能导致意外的结果,不可不察。如果不能确定zip所封装的列表是否等长,可以改用 itertools 内置模块中的zip_longest 函数,这个函数不在乎它们的长度是否相等。
在Python2中,zip不是生成器,它平行地遍历这些迭代器,组装元组,并把这些元组所构成的列表一次性完整地返回,这可能会占用大量内存并导致程序崩溃,如果在Python2中要遍历数据量大的迭代器,推荐使用 itertools 内置模块中的 izip 函数。3)map函数
有时候我们需要对column的每一列使用函数。这个时候可以使用lambda语法。
对于单个可以直接使用功能函数实现,但要实现整个一列,需要借助lambda:
print(df)
code date
0 000001.SZ 2015-12-10 00:00:00.005
1 000001.SZ 2015-12-11 00:00:00.005
2 000001.SZ 2015-12-14 00:00:00.005
3 000001.SZ 2015-12-15 00:00:00.005
4 000001.SZ 2015-12-16 00:00:00.005
5 000001.SZ 2015-12-17 00:00:00.005
6 000001.SZ 2015-12-18 00:00:00.005
7 000001.SZ 2015-12-21 00:00:00.005
8 000001.SZ 2015-12-22 00:00:00.005
type(df['date'][0])
pandas.tslib.Timestamp
其中df['date']的每个元素都是Timestamp类型。
我们现在想把这一列都转换为datetime.date类型。
**对于单独的元素可以使用方法**
print(df['date'][0].date())
print(type(df['date'][0].date()))
2015-12-10
<class 'datetime.date'>
**但是现在我们想转换df['date']的所有元素。可以用以下方法:**
df['date']=df['date'].apply(lambda x:x.date())
print(df)
code date
0 000001.SZ 2015-12-10
1 000001.SZ 2015-12-11
2 000001.SZ 2015-12-14
3 000001.SZ 2015-12-15
4 000001.SZ 2015-12-16
5 000001.SZ 2015-12-17
6 000001.SZ 2015-12-18
7 000001.SZ 2015-12-21
8 000001.SZ 2015-12-22
4)map函数
总的来说就是apply()是一种让函数作用于列或者行操作,applymap()是一种让函数作用于DataFrame每一个元素的操作,而map是一种让函数作用于Series每一个元素的操作。
5)flatmap函数
参考rdd的api:http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.RDD
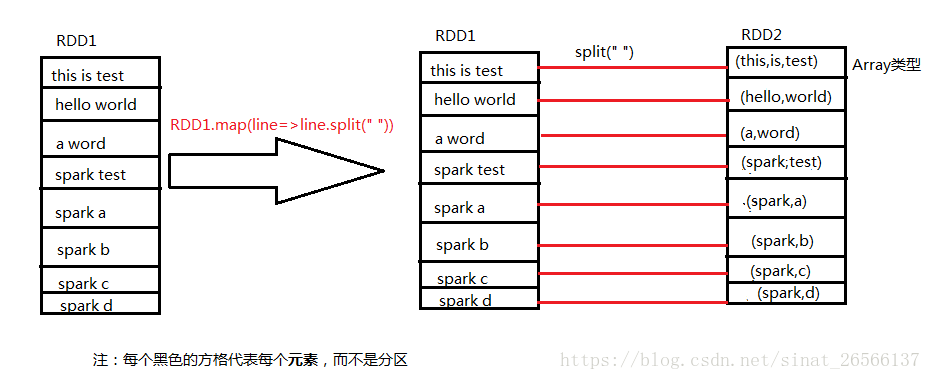
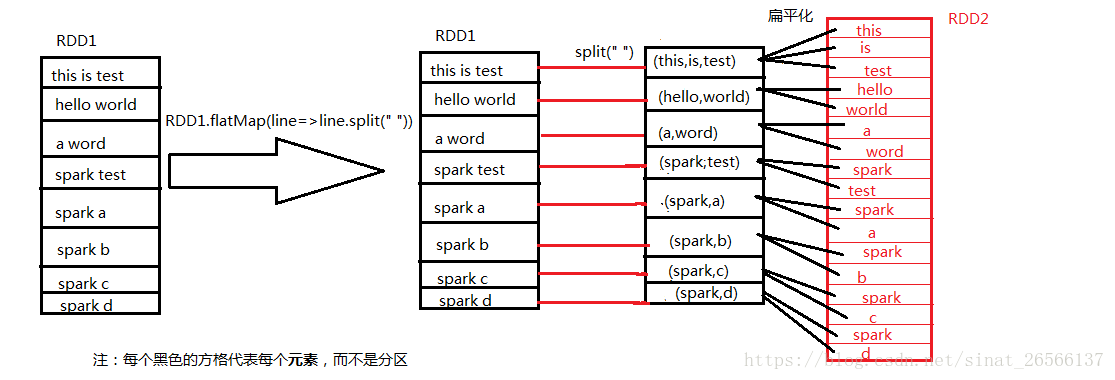
api已经讲解较为清楚,map是将每个元素对应执行f函数,而flatMap对应的是将每个元素执行f函数后将其扁平化;
我们采用将每个元素按照空格的方法将每个元素进行分割,分别执行map与flatMap方法。
map方法如下图所示:
flatMap方法如下图所示:
可参考:
https://blog.csdn.net/huanbia/article/details/51425463
https://www.jianshu.com/p/5aa6ebbc82de
http://pandas.pydata.org/pandas-docs/stable/comparison_with_sql.html